 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation without Source Data
Paper and Code
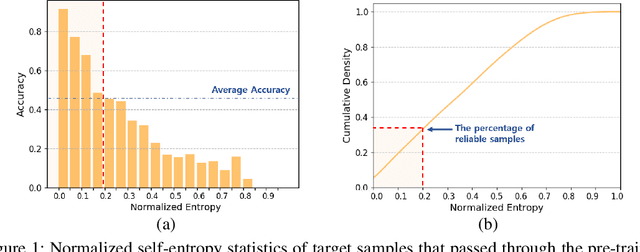
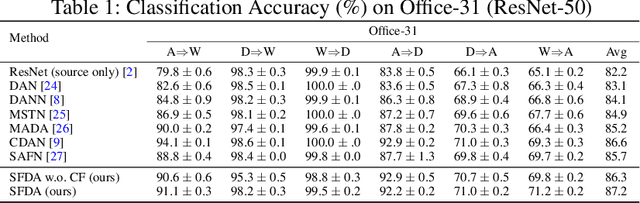
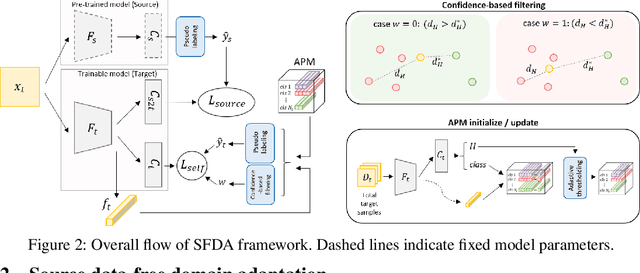

Domain adaptation assumes that samples from source and target domains are freely accessible during a training phase. However, such an assumption is rarely plausible in real cases and possibly causes data-privacy issues, especially when the label of the source domain can be a sensitive attribute as an identifier. To avoid accessing source data which may contain sensitive information, we introduce source data-free domain adaptation (SFDA). Our key idea is to leverage a pre-trained model from the source domain and progressively update the target model in a self-learning manner. We observe that target samples with lower self-entropy measured by the pre-trained source model are more likely to be classified correctly. From this, we select the reliable samples with the self-entropy criterion and define these as class prototypes. We then assign pseudo labels for every target sample based on the similarity score with class prototypes. Further, to reduce the uncertainty from the pseudo labeling process, we propose set-to-set distance-based filtering which does not require any tunable hyperparameters. Finally, we train the target model with the filtered pseudo labels with regularization from the pre-trained source model. Surprisingly, without direct usage of labeled source samples, our SFDA outperforms conventional domain adaptation methods on benchmark datasets. Our code is publicly available at https://github.com/youngryan1993/SFDA-Domain-Adaptation-without-Source-Data.