 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput-Aware Dynamic Timestep Spiking Neural Networks for Efficient In-Memory Computing
May 27, 2023


Spiking Neural Networks (SNNs) have recently attracted widespread research interest as an efficient alternative to traditional Artificial Neural Networks (ANNs) because of their capability to process sparse and binary spike information and avoid expensive multiplication operations. Although the efficiency of SNNs can be realized on the In-Memory Computing (IMC) architecture, we show that the energy cost and latency of SNNs scale linearly with the number of timesteps used on IMC hardware. Therefore, in order to maximize the efficiency of SNNs, we propose input-aware Dynamic Timestep SNN (DT-SNN), a novel algorithmic solution to dynamically determine the number of timesteps during inference on an input-dependent basis. By calculating the entropy of the accumulated output after each timestep, we can compare it to a predefined threshold and decide if the information processed at the current timestep is sufficient for a confident prediction. We deploy DT-SNN on an IMC architecture and show that it incurs negligible computational overhead. We demonstrate that our method only uses 1.46 average timesteps to achieve the accuracy of a 4-timestep static SNN while reducing the energy-delay-product by 80%.
Do We Really Need a Large Number of Visual Prompts?
May 26, 2023Due to increasing interest in adapting models on resource-constrained edges, parameter-efficient transfer learning has been widely explored. Among various methods, Visual Prompt Tuning (VPT), prepending learnable prompts to input space, shows competitive fine-tuning performance compared to training of full network parameters. However, VPT increases the number of input tokens, resulting in additional computational overhead. In this paper, we analyze the impact of the number of prompts on fine-tuning performance and self-attention operation in a vision transformer architecture. Through theoretical and empirical analysis we show that adding more prompts does not lead to linear performance improvement. Further, we propose a Prompt Condensation (PC) technique that aims to prevent performance degradation from using a small number of prompts. We validate our methods on FGVC and VTAB-1k tasks and show that our approach reduces the number of prompts by ~70% while maintaining accuracy.
Sharing Leaky-Integrate-and-Fire Neurons for Memory-Efficient Spiking Neural Networks
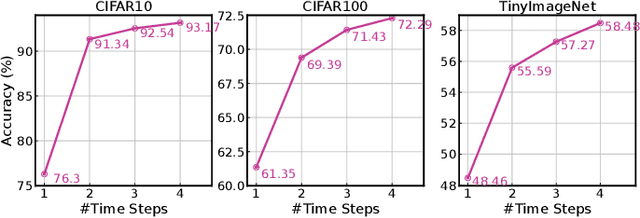
May 26, 2023Spiking Neural Networks (SNNs) have gained increasing attention as energy-efficient neural networks owing to their binary and asynchronous computation. However, their non-linear activation, that is Leaky-Integrate-and-Fire (LIF) neuron, requires additional memory to store a membrane voltage to capture the temporal dynamics of spikes. Although the required memory cost for LIF neurons significantly increases as the input dimension goes larger, a technique to reduce memory for LIF neurons has not been explored so far. To address this, we propose a simple and effective solution, EfficientLIF-Net, which shares the LIF neurons across different layers and channels. Our EfficientLIF-Net achieves comparable accuracy with the standard SNNs while bringing up to ~4.3X forward memory efficiency and ~21.9X backward memory efficiency for LIF neurons. We conduct experiments on various datasets including CIFAR10, CIFAR100, TinyImageNet, ImageNet-100, and N-Caltech101. Furthermore, we show that our approach also offers advantages on Human Activity Recognition (HAR) datasets, which heavily rely on temporal information.
MINT: Multiplier-less Integer Quantization for Spiking Neural Networks
May 20, 2023We propose Multiplier-less INTeger (MINT) quantization, an efficient uniform quantization scheme for the weights and membrane potentials in spiking neural networks (SNNs). Unlike prior SNN quantization works, MINT quantizes the memory-hungry membrane potentials to extremely low bit-width (2-bit) to significantly reduce the total memory footprint. Additionally, MINT quantization shares the quantization scale between the weights and membrane potentials, eliminating the need for multipliers and floating arithmetic units, which are required by the standard uniform quantization. Experimental results demonstrate that our proposed method achieves accuracy that matches other state-of-the-art SNN quantization works while outperforming them on total memory footprint and hardware cost at deployment time. For instance, 2-bit MINT VGG-16 achieves 48.6% accuracy on TinyImageNet (0.28% better than the full-precision baseline) with approximately 93.8% reduction in total memory footprint from the full-precision model; meanwhile, our model reduces area by 93% and dynamic power by 98% compared to other SNN quantization counterparts.
Divide-and-Conquer the NAS puzzle in Resource Constrained Federated Learning Systems
May 11, 2023Federated Learning (FL) is a privacy-preserving distributed machine learning approach geared towards applications in edge devices. However, the problem of designing custom neural architectures in federated environments is not tackled from the perspective of overall system efficiency. In this paper, we propose DC-NAS -- a divide-and-conquer approach that performs supernet-based Neural Architecture Search (NAS) in a federated system by systematically sampling the search space. We propose a novel diversified sampling strategy that balances exploration and exploitation of the search space by initially maximizing the distance between the samples and progressively shrinking this distance as the training progresses. We then perform channel pruning to reduce the training complexity at the devices further. We show that our approach outperforms several sampling strategies including Hadamard sampling, where the samples are maximally separated. We evaluate our method on the CIFAR10, CIFAR100, EMNIST, and TinyImagenet benchmarks and show a comprehensive analysis of different aspects of federated learning such as scalability, and non-IID data. DC-NAS achieves near iso-accuracy as compared to full-scale federated NAS with 50% fewer resources.
Uncovering the Representation of Spiking Neural Networks Trained with Surrogate Gradient
Apr 25, 2023Spiking Neural Networks (SNNs) are recognized as the candidate for the next-generation neural networks due to their bio-plausibility and energy efficiency. Recently, researchers have demonstrated that SNNs are able to achieve nearly state-of-the-art performance in image recognition tasks using surrogate gradient training. However, some essential questions exist pertaining to SNNs that are little studied: Do SNNs trained with surrogate gradient learn different representations from traditional Artificial Neural Networks (ANNs)? Does the time dimension in SNNs provide unique representation power? In this paper, we aim to answer these questions by conducting a representation similarity analysis between SNNs and ANNs using Centered Kernel Alignment (CKA). We start by analyzing the spatial dimension of the networks, including both the width and the depth. Furthermore, our analysis of residual connections shows that SNNs learn a periodic pattern, which rectifies the representations in SNNs to be ANN-like. We additionally investigate the effect of the time dimension on SNN representation, finding that deeper layers encourage more dynamics along the time dimension. We also investigate the impact of input data such as event-stream data and adversarial attacks. Our work uncovers a host of new findings of representations in SNNs. We hope this work will inspire future research to fully comprehend the representation power of SNNs. Code is released at https://github.com/Intelligent-Computing-Lab-Yale/SNNCKA.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
SEENN: Towards Temporal Spiking Early-Exit Neural Networks
Apr 02, 2023Spiking Neural Networks (SNNs) have recently become more popular as a biologically plausible substitute for traditional Artificial Neural Networks (ANNs). SNNs are cost-efficient and deployment-friendly because they process input in both spatial and temporal manners using binary spikes. However, we observe that the information capacity in SNNs is affected by the number of timesteps, leading to an accuracy-efficiency tradeoff. In this work, we study a fine-grained adjustment of the number of timesteps in SNNs. Specifically, we treat the number of timesteps as a variable conditioned on different input samples to reduce redundant timesteps for certain data. We call our method Spiking Early-Exit Neural Networks (SEENNs). To determine the appropriate number of timesteps, we propose SEENN-I which uses a confidence score thresholding to filter out the uncertain predictions, and SEENN-II which determines the number of timesteps by reinforcement learning. Moreover, we demonstrate that SEENN is compatible with both the directly trained SNN and the ANN-SNN conversion. By dynamically adjusting the number of timesteps, our SEENN achieves a remarkable reduction in the average number of timesteps during inference. For example, our SEENN-II ResNet-19 can achieve 96.1% accuracy with an average of 1.08 timesteps on the CIFAR-10 test dataset.
XPert: Peripheral Circuit & Neural Architecture Co-search for Area and Energy-efficient Xbar-based Computing
Mar 30, 2023



The hardware-efficiency and accuracy of Deep Neural Networks (DNNs) implemented on In-memory Computing (IMC) architectures primarily depend on the DNN architecture and the peripheral circuit parameters. It is therefore essential to holistically co-search the network and peripheral parameters to achieve optimal performance. To this end, we propose XPert, which co-searches network architecture in tandem with peripheral parameters such as the type and precision of analog-to-digital converters, crossbar column sharing and the layer-specific input precision using an optimization-based design space exploration. Compared to VGG16 baselines, XPert achieves 10.24x (4.7x) lower EDAP, 1.72x (1.62x) higher TOPS/W,1.93x (3x) higher TOPS/mm2 at 92.46% (56.7%) accuracy for CIFAR10 (TinyImagenet) datasets. The code for this paper is available at https://github.com/Intelligent-Computing-Lab-Yale/XPert.
* Accepted to Design and Automation Conference (DAC)
XploreNAS: Explore Adversarially Robust & Hardware-efficient Neural Architectures for Non-ideal Xbars
Feb 15, 2023



Compute In-Memory platforms such as memristive crossbars are gaining focus as they facilitate acceleration of Deep Neural Networks (DNNs) with high area and compute-efficiencies. However, the intrinsic non-idealities associated with the analog nature of computing in crossbars limits the performance of the deployed DNNs. Furthermore, DNNs are shown to be vulnerable to adversarial attacks leading to severe security threats in their large-scale deployment. Thus, finding adversarially robust DNN architectures for non-ideal crossbars is critical to the safe and secure deployment of DNNs on the edge. This work proposes a two-phase algorithm-hardware co-optimization approach called XploreNAS that searches for hardware-efficient & adversarially robust neural architectures for non-ideal crossbar platforms. We use the one-shot Neural Architecture Search (NAS) approach to train a large Supernet with crossbar-awareness and sample adversarially robust Subnets therefrom, maintaining competitive hardware-efficiency. Our experiments on crossbars with benchmark datasets (SVHN, CIFAR10 & CIFAR100) show upto ~8-16% improvement in the adversarial robustness of the searched Subnets against a baseline ResNet-18 model subjected to crossbar-aware adversarial training. We benchmark our robust Subnets for Energy-Delay-Area-Products (EDAPs) using the Neurosim tool and find that with additional hardware-efficiency driven optimizations, the Subnets attain ~1.5-1.6x lower EDAPs than ResNet-18 baseline.