 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter to Ask in English: Evaluation of Large Language Models on English, Low-resource and Cross-Lingual Settings
Oct 17, 2024Large Language Models (LLMs) are trained on massive amounts of data, enabling their application across diverse domains and tasks. Despite their remarkable performance, most LLMs are developed and evaluated primarily in English. Recently, a few multi-lingual LLMs have emerged, but their performance in low-resource languages, especially the most spoken languages in South Asia, is less explored. To address this gap, in this study, we evaluate LLMs such as GPT-4, Llama 2, and Gemini to analyze their effectiveness in English compared to other low-resource languages from South Asia (e.g., Bangla, Hindi, and Urdu). Specifically, we utilized zero-shot prompting and five different prompt settings to extensively investigate the effectiveness of the LLMs in cross-lingual translated prompts. The findings of the study suggest that GPT-4 outperformed Llama 2 and Gemini in all five prompt settings and across all languages. Moreover, all three LLMs performed better for English language prompts than other low-resource language prompts. This study extensively investigates LLMs in low-resource language contexts to highlight the improvements required in LLMs and language-specific resources to develop more generally purposed NLP applications.
Do Large Language Models Speak All Languages Equally? A Comparative Study in Low-Resource Settings
Aug 05, 2024



Large language models (LLMs) have garnered significant interest in natural language processing (NLP), particularly their remarkable performance in various downstream tasks in resource-rich languages. Recent studies have highlighted the limitations of LLMs in low-resource languages, primarily focusing on binary classification tasks and giving minimal attention to South Asian languages. These limitations are primarily attributed to constraints such as dataset scarcity, computational costs, and research gaps specific to low-resource languages. To address this gap, we present datasets for sentiment and hate speech tasks by translating from English to Bangla, Hindi, and Urdu, facilitating research in low-resource language processing. Further, we comprehensively examine zero-shot learning using multiple LLMs in English and widely spoken South Asian languages. Our findings indicate that GPT-4 consistently outperforms Llama 2 and Gemini, with English consistently demonstrating superior performance across diverse tasks compared to low-resource languages. Furthermore, our analysis reveals that natural language inference (NLI) exhibits the highest performance among the evaluated tasks, with GPT-4 demonstrating superior capabilities.
Z-Index at CheckThat! Lab 2022: Check-Worthiness Identification on Tweet Text
Jul 15, 2022
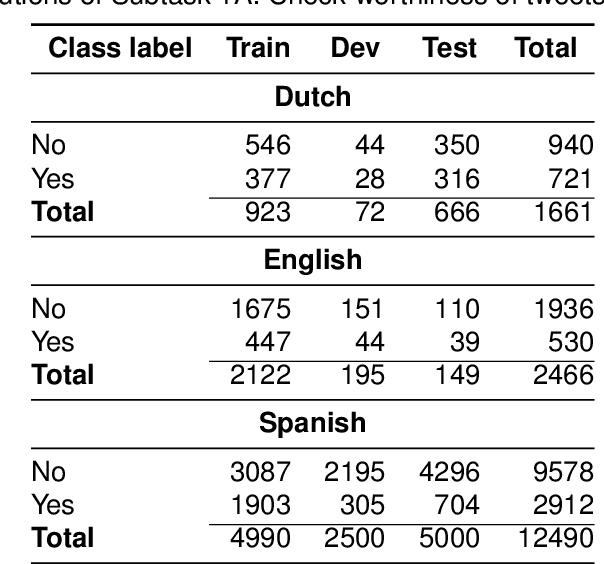
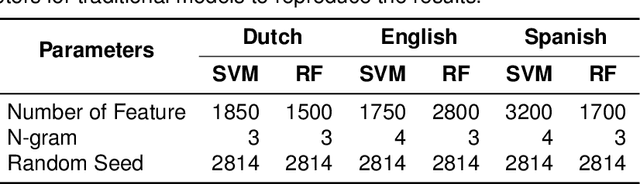

The wide use of social media and digital technologies facilitates sharing various news and information about events and activities. Despite sharing positive information misleading and false information is also spreading on social media. There have been efforts in identifying such misleading information both manually by human experts and automatic tools. Manual effort does not scale well due to the high volume of information, containing factual claims, are appearing online. Therefore, automatically identifying check-worthy claims can be very useful for human experts. In this study, we describe our participation in Subtask-1A: Check-worthiness of tweets (English, Dutch and Spanish) of CheckThat! lab at CLEF 2022. We performed standard preprocessing steps and applied different models to identify whether a given text is worthy of fact checking or not. We use the oversampling technique to balance the dataset and applied SVM and Random Forest (RF) with TF-IDF representations. We also used BERT multilingual (BERT-m) and XLM-RoBERTa-base pre-trained models for the experiments. We used BERT-m for the official submissions and our systems ranked as 3rd, 5th, and 12th in Spanish, Dutch, and English, respectively. In further experiments, our evaluation shows that transformer models (BERT-m and XLM-RoBERTa-base) outperform the SVM and RF in Dutch and English languages where a different scenario is observed for Spanish.