 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Design for Active Sequential Hypothesis Testing using Deep Learning
Oct 11, 2018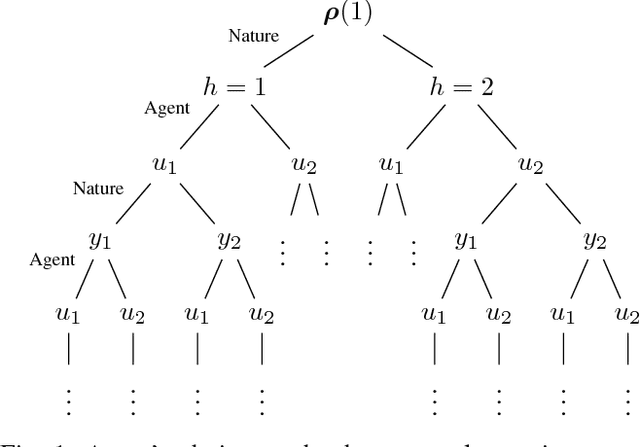
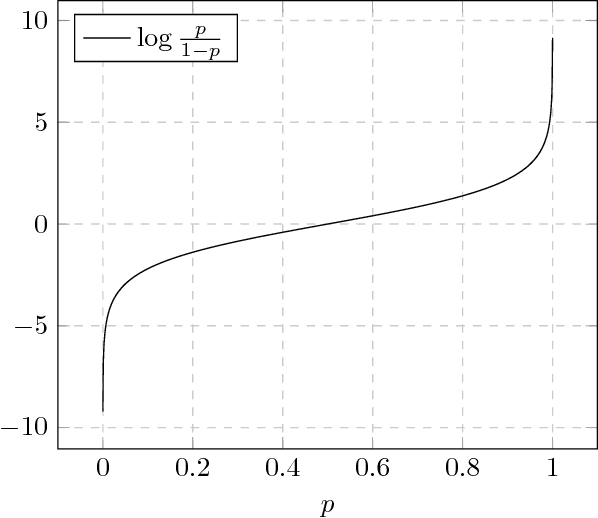
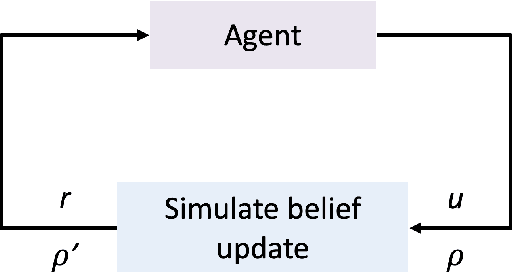
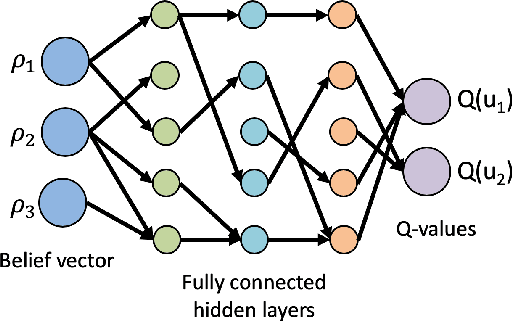
Information theory has been very successful in obtaining performance limits for various problems such as communication, compression and hypothesis testing. Likewise, stochastic control theory provides a characterization of optimal policies for Partially Observable Markov Decision Processes (POMDPs) using dynamic programming. However, finding optimal policies for these problems is computationally hard in general and thus, heuristic solutions are employed in practice. Deep learning can be used as a tool for designing better heuristics in such problems. In this paper, the problem of active sequential hypothesis testing is considered. The goal is to design a policy that can reliably infer the true hypothesis using as few samples as possible by adaptively selecting appropriate queries. This problem can be modeled as a POMDP and bounds on its value function exist in literature. However, optimal policies have not been identified and various heuristics are used. In this paper, two new heuristics are proposed: one based on deep reinforcement learning and another based on a KL-divergence zero-sum game. These heuristics are compared with state-of-the-art solutions and it is demonstrated using numerical experiments that the proposed heuristics can achieve significantly better performance than existing methods in some scenarios.
A Byte-sized Approach to Named Entity Recognition
Sep 22, 2018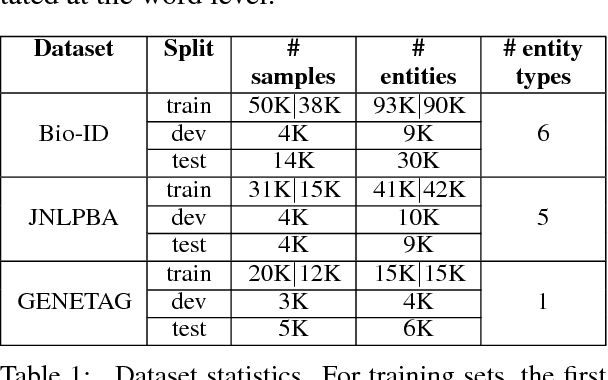
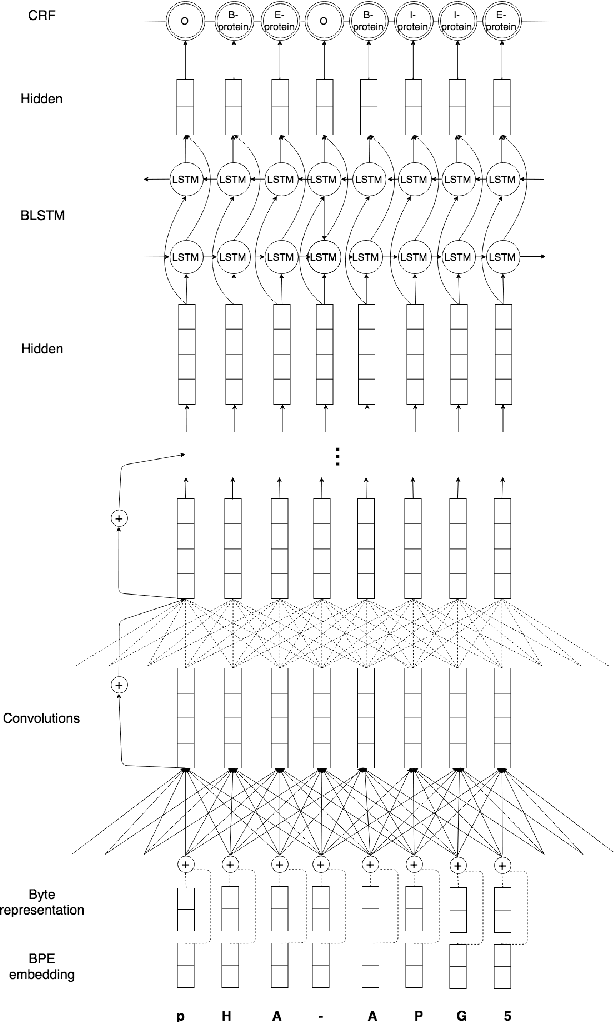
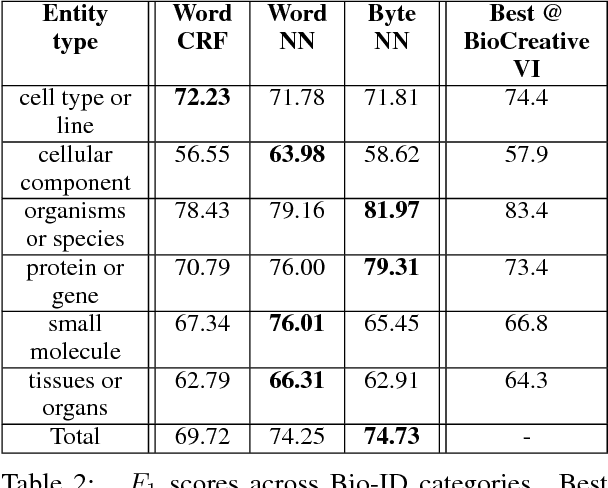
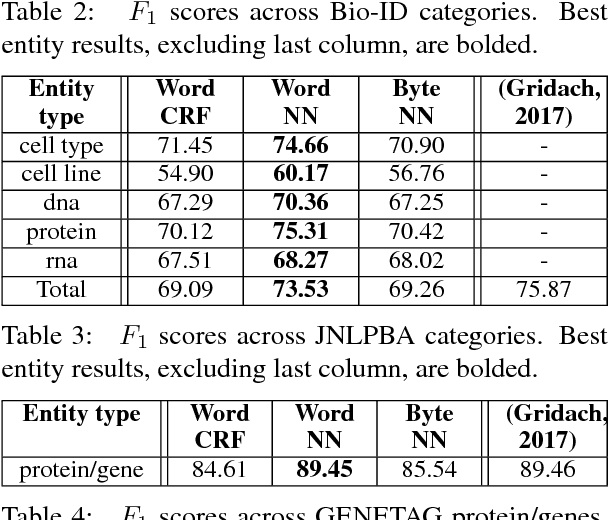
In biomedical literature, it is common for entity boundaries to not align with word boundaries. Therefore, effective identification of entity spans requires approaches capable of considering tokens that are smaller than words. We introduce a novel, subword approach for named entity recognition (NER) that uses byte-pair encodings (BPE) in combination with convolutional and recurrent neural networks to produce byte-level tags of entities. We present experimental results on several standard biomedical datasets, namely the BioCreative VI Bio-ID, JNLPBA, and GENETAG datasets. We demonstrate competitive performance while bypassing the specialized domain expertise needed to create biomedical text tokenization rules.
Deep Multimodal Image-Repurposing Detection
Aug 20, 2018
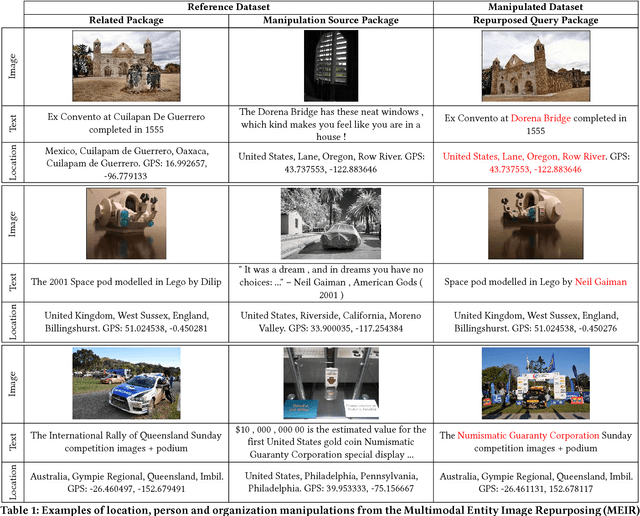
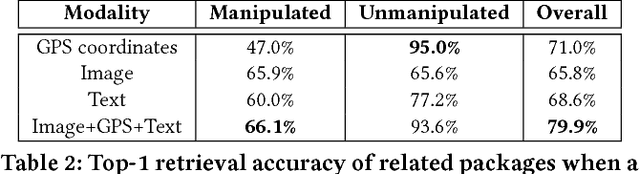
Nefarious actors on social media and other platforms often spread rumors and falsehoods through images whose metadata (e.g., captions) have been modified to provide visual substantiation of the rumor/falsehood. This type of modification is referred to as image repurposing, in which often an unmanipulated image is published along with incorrect or manipulated metadata to serve the actor's ulterior motives. We present the Multimodal Entity Image Repurposing (MEIR) dataset, a substantially challenging dataset over that which has been previously available to support research into image repurposing detection. The new dataset includes location, person, and organization manipulations on real-world data sourced from Flickr. We also present a novel, end-to-end, deep multimodal learning model for assessing the integrity of an image by combining information extracted from the image with related information from a knowledge base. The proposed method is compared against state-of-the-art techniques on existing datasets as well as MEIR, where it outperforms existing methods across the board, with AUC improvement up to 0.23.
Learn to Combine Modalities in Multimodal Deep Learning
May 29, 2018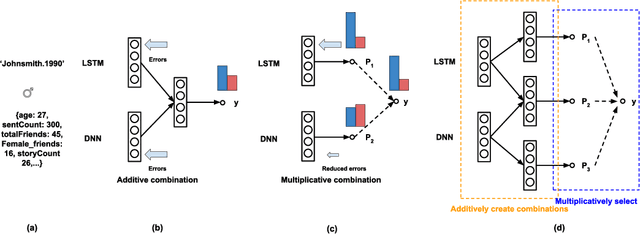

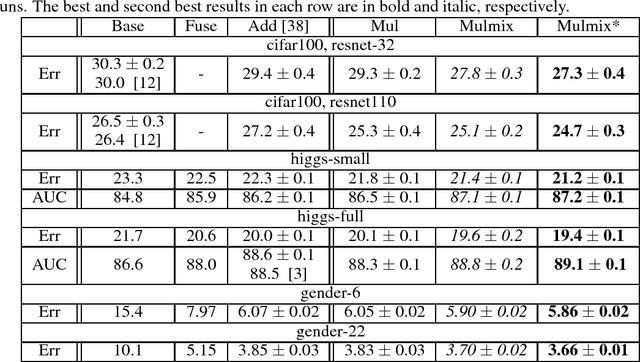
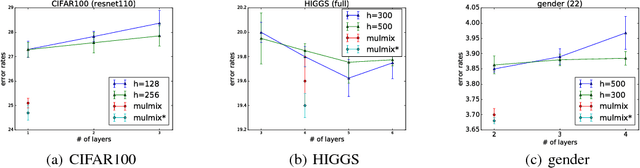
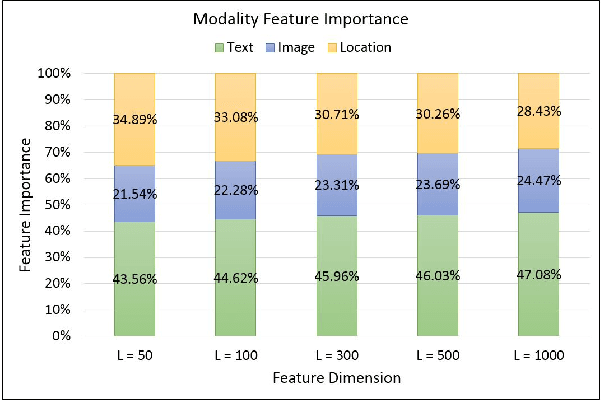
Combining complementary information from multiple modalities is intuitively appealing for improving the performance of learning-based approaches. However, it is challenging to fully leverage different modalities due to practical challenges such as varying levels of noise and conflicts between modalities. Existing methods do not adopt a joint approach to capturing synergies between the modalities while simultaneously filtering noise and resolving conflicts on a per sample basis. In this work we propose a novel deep neural network based technique that multiplicatively combines information from different source modalities. Thus the model training process automatically focuses on information from more reliable modalities while reducing emphasis on the less reliable modalities. Furthermore, we propose an extension that multiplicatively combines not only the single-source modalities, but a set of mixtured source modalities to better capture cross-modal signal correlations. We demonstrate the effectiveness of our proposed technique by presenting empirical results on three multimodal classification tasks from different domains. The results show consistent accuracy improvements on all three tasks.
A Sequential Embedding Approach for Item Recommendation with Heterogeneous Attributes
May 28, 2018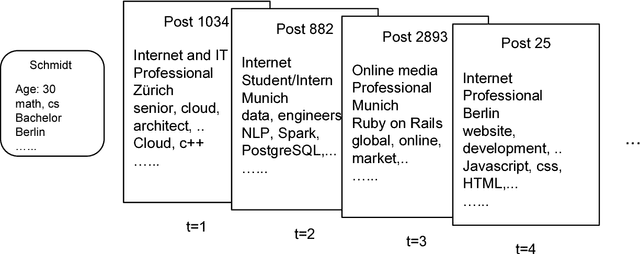

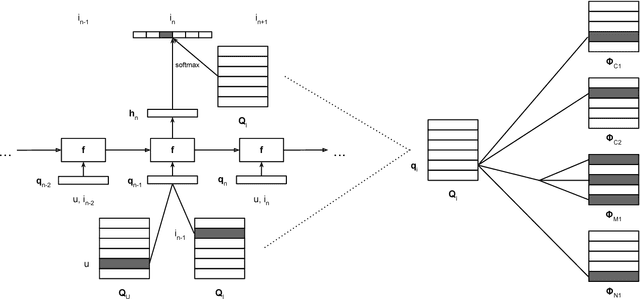
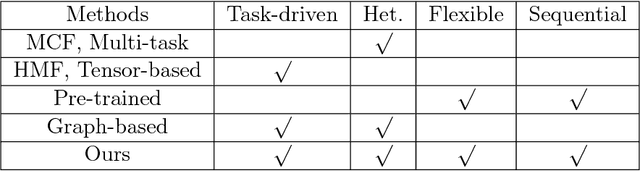
Attributes, such as metadata and profile, carry useful information which in principle can help improve accuracy in recommender systems. However, existing approaches have difficulty in fully leveraging attribute information due to practical challenges such as heterogeneity and sparseness. These approaches also fail to combine recurrent neural networks which have recently shown effectiveness in item recommendations in applications such as video and music browsing. To overcome the challenges and to harvest the advantages of sequence models, we present a novel approach, Heterogeneous Attribute Recurrent Neural Networks (HA-RNN), which incorporates heterogeneous attributes and captures sequential dependencies in \textit{both} items and attributes. HA-RNN extends recurrent neural networks with 1) a hierarchical attribute combination input layer and 2) an output attribute embedding layer. We conduct extensive experiments on two large-scale datasets. The new approach show significant improvements over the state-of-the-art models. Our ablation experiments demonstrate the effectiveness of the two components to address heterogeneous attribute challenges including variable lengths and attribute sparseness. We further investigate why sequence modeling works well by conducting exploratory studies and show sequence models are more effective when data scale increases.
Implicit Language Model in LSTM for OCR
May 23, 2018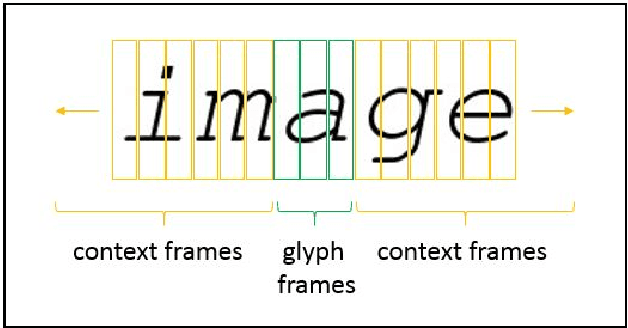
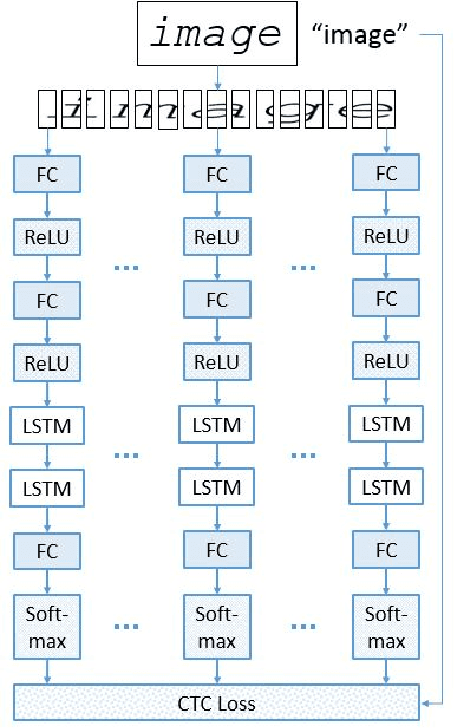
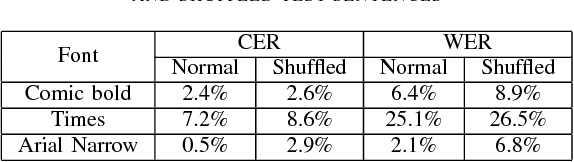
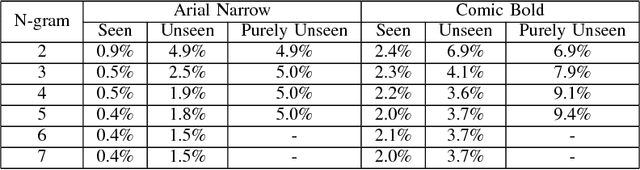
Neural networks have become the technique of choice for OCR, but many aspects of how and why they deliver superior performance are still unknown. One key difference between current neural network techniques using LSTMs and the previous state-of-the-art HMM systems is that HMM systems have a strong independence assumption. In comparison LSTMs have no explicit constraints on the amount of context that can be considered during decoding. In this paper we show that they learn an implicit LM and attempt to characterize the strength of the LM in terms of equivalent n-gram context. We show that this implicitly learned language model provides a 2.4\% CER improvement on our synthetic test set when compared against a test set of random characters (i.e. not naturally occurring sequences), and that the LSTM learns to use up to 5 characters of context (which is roughly 88 frames in our configuration). We believe that this is the first ever attempt at characterizing the strength of the implicit LM in LSTM based OCR systems.
A Batch Learning Framework for Scalable Personalized Ranking
Nov 10, 2017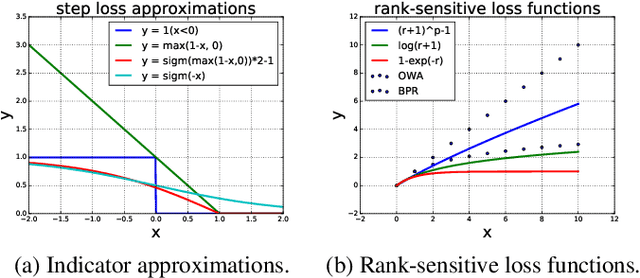

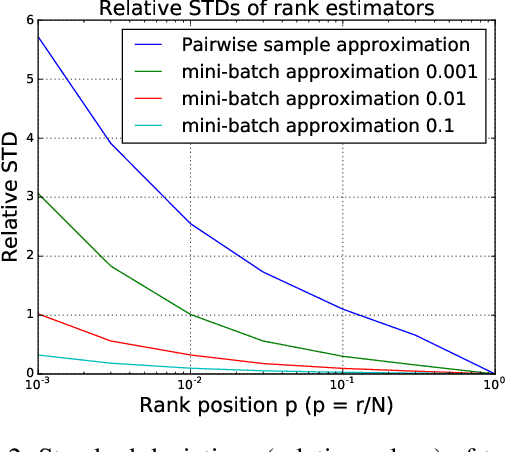
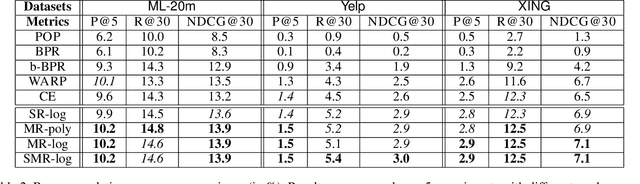
In designing personalized ranking algorithms, it is desirable to encourage a high precision at the top of the ranked list. Existing methods either seek a smooth convex surrogate for a non-smooth ranking metric or directly modify updating procedures to encourage top accuracy. In this work we point out that these methods do not scale well to a large-scale setting, and this is partly due to the inaccurate pointwise or pairwise rank estimation. We propose a new framework for personalized ranking. It uses batch-based rank estimators and smooth rank-sensitive loss functions. This new batch learning framework leads to more stable and accurate rank approximations compared to previous work. Moreover, it enables explicit use of parallel computation to speed up training. We conduct empirical evaluation on three item recommendation tasks. Our method shows consistent accuracy improvements over state-of-the-art methods. Additionally, we observe time efficiency advantages when data scale increases.
* AAAI 2018, Feb 2-7, New Orleans, USA
WMRB: Learning to Rank in a Scalable Batch Training Approach
Nov 10, 2017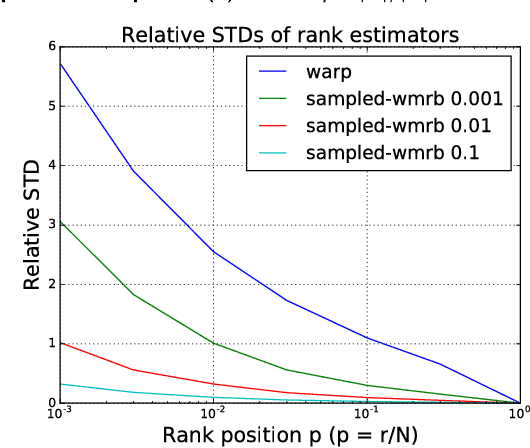
We propose a new learning to rank algorithm, named Weighted Margin-Rank Batch loss (WMRB), to extend the popular Weighted Approximate-Rank Pairwise loss (WARP). WMRB uses a new rank estimator and an efficient batch training algorithm. The approach allows more accurate item rank approximation and explicit utilization of parallel computation to accelerate training. In three item recommendation tasks, WMRB consistently outperforms WARP and other baselines. Moreover, WMRB shows clear time efficiency advantages as data scale increases.
An Investigation into the Pedagogical Features of Documents
Aug 01, 2017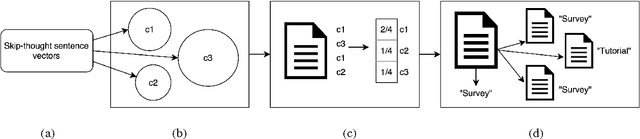
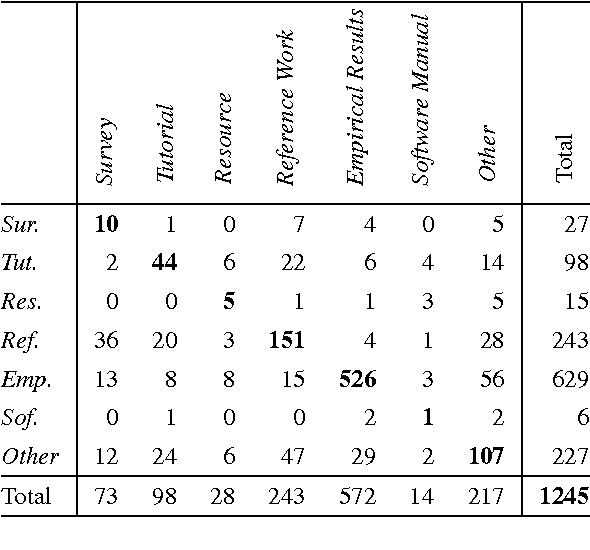
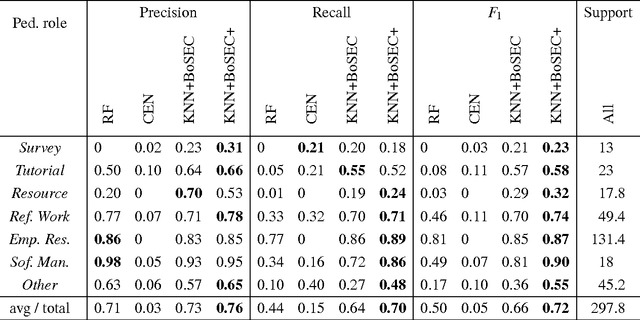
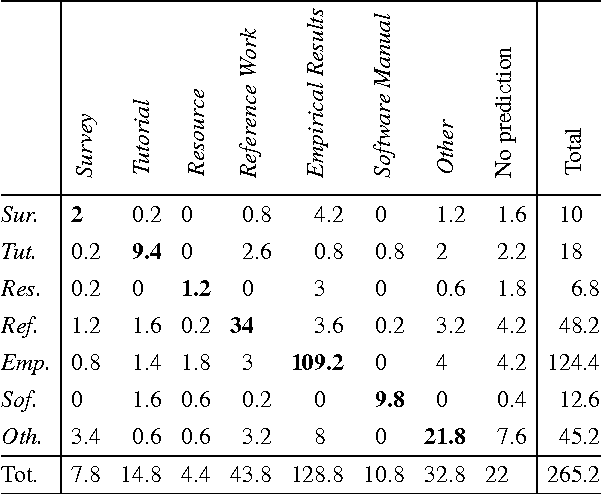
Characterizing the content of a technical document in terms of its learning utility can be useful for applications related to education, such as generating reading lists from large collections of documents. We refer to this learning utility as the "pedagogical value" of the document to the learner. While pedagogical value is an important concept that has been studied extensively within the education domain, there has been little work exploring it from a computational, i.e., natural language processing (NLP), perspective. To allow a computational exploration of this concept, we introduce the notion of "pedagogical roles" of documents (e.g., Tutorial and Survey) as an intermediary component for the study of pedagogical value. Given the lack of available corpora for our exploration, we create the first annotated corpus of pedagogical roles and use it to test baseline techniques for automatic prediction of such roles.
Deep Matching and Validation Network -- An End-to-End Solution to Constrained Image Splicing Localization and Detection
May 27, 2017

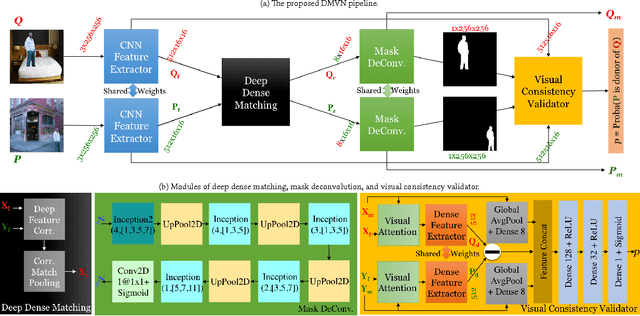
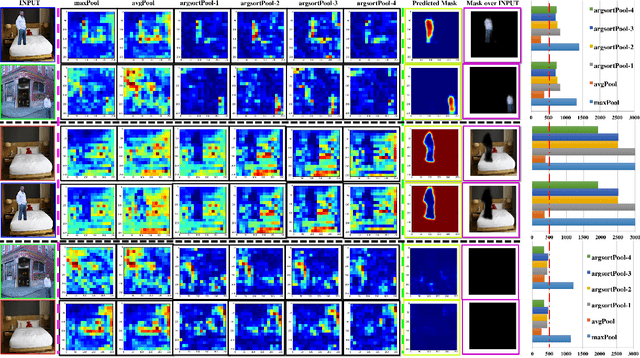
Image splicing is a very common image manipulation technique that is sometimes used for malicious purposes. A splicing detec- tion and localization algorithm usually takes an input image and produces a binary decision indicating whether the input image has been manipulated, and also a segmentation mask that corre- sponds to the spliced region. Most existing splicing detection and localization pipelines suffer from two main shortcomings: 1) they use handcrafted features that are not robust against subsequent processing (e.g., compression), and 2) each stage of the pipeline is usually optimized independently. In this paper we extend the formulation of the underlying splicing problem to consider two input images, a query image and a potential donor image. Here the task is to estimate the probability that the donor image has been used to splice the query image, and obtain the splicing masks for both the query and donor images. We introduce a novel deep convolutional neural network architecture, called Deep Matching and Validation Network (DMVN), which simultaneously localizes and detects image splicing. The proposed approach does not depend on handcrafted features and uses raw input images to create deep learned representations. Furthermore, the DMVN is end-to-end op- timized to produce the probability estimates and the segmentation masks. Our extensive experiments demonstrate that this approach outperforms state-of-the-art splicing detection methods by a large margin in terms of both AUC score and speed.