 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Wildfire Susceptibility from Remote Sensing Using Random Forests and SHAP
Nov 12, 2025



Wildfires pose a significant global threat to ecosystems worldwide, with California experiencing recurring fires due to various factors, including climate, topographical features, vegetation patterns, and human activities. This study aims to develop a comprehensive wildfire risk map for California by applying the random forest (RF) algorithm, augmented with Explainable Artificial Intelligence (XAI) through Shapley Additive exPlanations (SHAP), to interpret model predictions. Model performance was assessed using both spatial and temporal validation strategies. The RF model demonstrated strong predictive performance, achieving near-perfect discrimination for grasslands (AUC = 0.996) and forests (AUC = 0.997). Spatial cross-validation revealed moderate transferability, yielding ROC-AUC values of 0.6155 for forests and 0.5416 for grasslands. In contrast, temporal split validation showed enhanced generalization, especially for forests (ROC-AUC = 0.6615, PR-AUC = 0.8423). SHAP-based XAI analysis identified key ecosystem-specific drivers: soil organic carbon, tree cover, and Normalized Difference Vegetation Index (NDVI) emerged as the most influential in forests, whereas Land Surface Temperature (LST), elevation, and vegetation health indices were dominant in grasslands. District-level classification revealed that Central Valley and Northern Buttes districts had the highest concentration of high-risk grasslands, while Northern Buttes and North Coast Redwoods dominated forested high-risk areas. This RF-SHAP framework offers a robust, comprehensible, and adaptable method for assessing wildfire risks, enabling informed decisions and creating targeted strategies to mitigate dangers.
Benchmarking Sim2Real Gap: High-fidelity Digital Twinning of Agile Manufacturing
Sep 16, 2024



As the manufacturing industry shifts from mass production to mass customization, there is a growing emphasis on adopting agile, resilient, and human-centric methodologies in line with the directives of Industry 5.0. Central to this transformation is the deployment of digital twins, a technology that digitally replicates manufacturing assets to enable enhanced process optimization, predictive maintenance, synthetic data generation, and accelerated customization and prototyping. This chapter delves into the technologies underpinning the creation of digital twins specifically tailored to agile manufacturing scenarios within the realm of robotic automation. It explores the transfer of trained policies and process optimizations from simulated settings to real-world applications through advanced techniques such as domain randomization, domain adaptation, curriculum learning, and model-based system identification. The chapter also examines various industrial manufacturing automation scenarios, including bin-picking, part inspection, and product assembly, under Sim2Real conditions. The performance of digital twin technologies in these scenarios is evaluated using practical metrics including data latency, adaptation rate, simulation fidelity among others reported, providing a comprehensive assessment of their efficacy and potential impact on modern manufacturing processes.
Collaborating for Success: Optimizing System Efficiency and Resilience Under Agile Industrial Settings
Sep 12, 2024



Designing an efficient and resilient human-robot collaboration strategy that not only upholds the safety and ergonomics of shared workspace but also enhances the performance and agility of collaborative setup presents significant challenges concerning environment perception and robot control. In this research, we introduce a novel approach for collaborative environment monitoring and robot motion regulation to address this multifaceted problem. Our study proposes novel computation and division of safety monitoring zones, adhering to ISO 13855 and TS 15066 standards, utilizing 2D lasers information. These zones are not only configured in the standard three-layer arrangement but are also expanded into two adjacent quadrants, thereby enhancing system uptime and preventing unnecessary deadlocks. Moreover, we also leverage 3D visual information to track dynamic human articulations and extended intrusions. Drawing upon the fused sensory data from 2D and 3D perceptual spaces, our proposed hierarchical controller stably regulates robot velocity, validated using Lasalle in-variance principle. Empirical evaluations demonstrate that our approach significantly reduces task execution time and system response delay, resulting in improved efficiency and resilience within collaborative settings.
Enhancing Microgrid Performance Prediction with Attention-based Deep Learning Models
Jul 20, 2024



In this research, an effort is made to address microgrid systems' operational challenges, characterized by power oscillations that eventually contribute to grid instability. An integrated strategy is proposed, leveraging the strengths of convolutional and Gated Recurrent Unit (GRU) layers. This approach is aimed at effectively extracting temporal data from energy datasets to improve the precision of microgrid behavior forecasts. Additionally, an attention layer is employed to underscore significant features within the time-series data, optimizing the forecasting process. The framework is anchored by a Multi-Layer Perceptron (MLP) model, which is tasked with comprehensive load forecasting and the identification of abnormal grid behaviors. Our methodology underwent rigorous evaluation using the Micro-grid Tariff Assessment Tool dataset, with Root Mean Square Error (RMSE), Mean Absolute Error (MAE), and the coefficient of determination (r2-score) serving as the primary metrics. The approach demonstrated exemplary performance, evidenced by a MAE of 0.39, RMSE of 0.28, and an r2-score of 98.89\% in load forecasting, along with near-perfect zero state prediction accuracy (approximately 99.9\%). Significantly outperforming conventional machine learning models such as support vector regression and random forest regression, our model's streamlined architecture is particularly suitable for real-time applications, thereby facilitating more effective and reliable microgrid management.
An Automated Machine Learning Approach to Inkjet Printed Component Analysis: A Step Toward Smart Additive Manufacturing
Apr 06, 2024In this paper, we present a machine learning based architecture for microwave characterization of inkjet printed components on flexible substrates. Our proposed architecture uses several machine learning algorithms and automatically selects the best algorithm to extract the material parameters (ink conductivity and dielectric properties) from on-wafer measurements. Initially, the mutual dependence between material parameters of the inkjet printed coplanar waveguides (CPWs) and EM-simulated propagation constants is utilized to train the machine learning models. Next, these machine learning models along with measured propagation constants are used to extract the ink conductivity and dielectric properties of the test prototypes. To demonstrate the applicability of our proposed approach, we compare and contrast four heuristic based machine learning models. It is shown that eXtreme Gradient Boosted Trees Regressor (XGB) and Light Gradient Boosting (LGB) algorithms perform best for the characterization problem under study.
LSTM-CNN Network for Audio Signature Analysis in Noisy Environments
Dec 12, 2023There are multiple applications to automatically count people and specify their gender at work, exhibitions, malls, sales, and industrial usage. Although current speech detection methods are supposed to operate well, in most situations, in addition to genders, the number of current speakers is unknown and the classification methods are not suitable due to many possible classes. In this study, we focus on a long-short-term memory convolutional neural network (LSTM-CNN) to extract time and / or frequency-dependent features of the sound data to estimate the number / gender of simultaneous active speakers at each frame in noisy environments. Considering the maximum number of speakers as 10, we have utilized 19000 audio samples with diverse combinations of males, females, and background noise in public cities, industrial situations, malls, exhibitions, workplaces, and nature for learning purposes. This proof of concept shows promising performance with training/validation MSE values of about 0.019/0.017 in detecting count and gender.
TLU-Net: A Deep Learning Approach for Automatic Steel Surface Defect Detection
Jan 18, 2021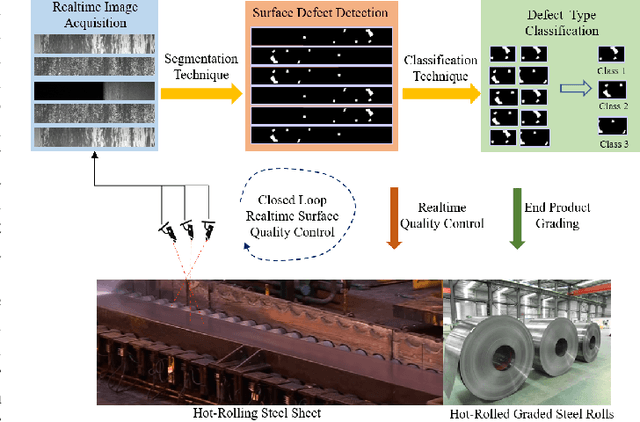
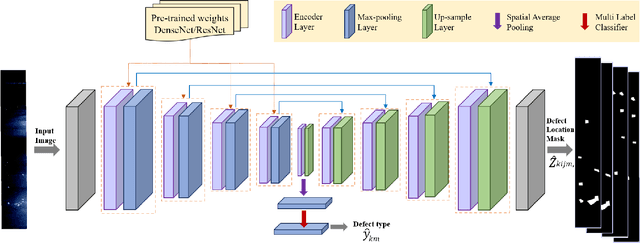
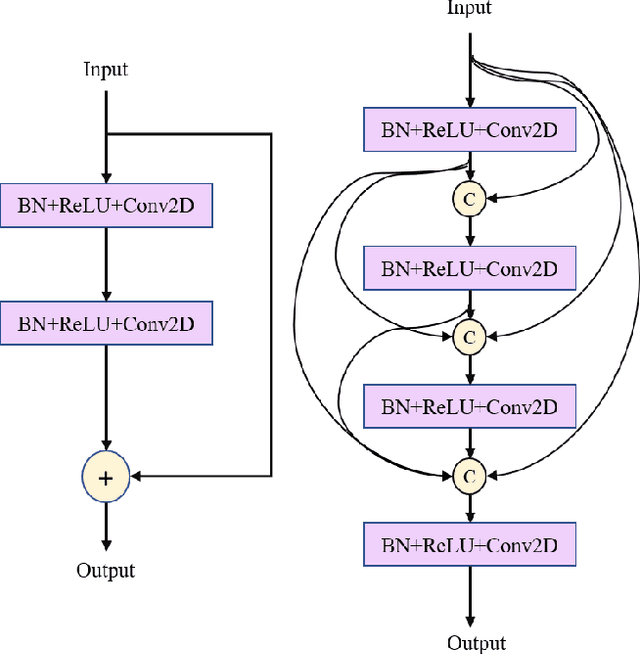
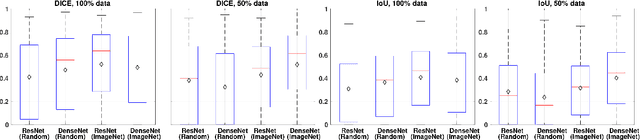
Visual steel surface defect detection is an essential step in steel sheet manufacturing. Several machine learning-based automated visual inspection (AVI) methods have been studied in recent years. However, most steel manufacturing industries still use manual visual inspection due to training time and inaccuracies involved with AVI methods. Automatic steel defect detection methods could be useful in less expensive and faster quality control and feedback. But preparing the annotated training data for segmentation and classification could be a costly process. In this work, we propose to use the Transfer Learning-based U-Net (TLU-Net) framework for steel surface defect detection. We use a U-Net architecture as the base and explore two kinds of encoders: ResNet and DenseNet. We compare these nets' performance using random initialization and the pre-trained networks trained using the ImageNet data set. The experiments are performed using Severstal data. The results demonstrate that the transfer learning performs 5% (absolute) better than that of the random initialization in defect classification. We found that the transfer learning performs 26% (relative) better than that of the random initialization in defect segmentation. We also found the gain of transfer learning increases as the training data decreases, and the convergence rate with transfer learning is better than that of the random initialization.
Effects of Voice-Based Synthetic Assistant on Performance of Emergency Care Provider in Training
Aug 12, 2020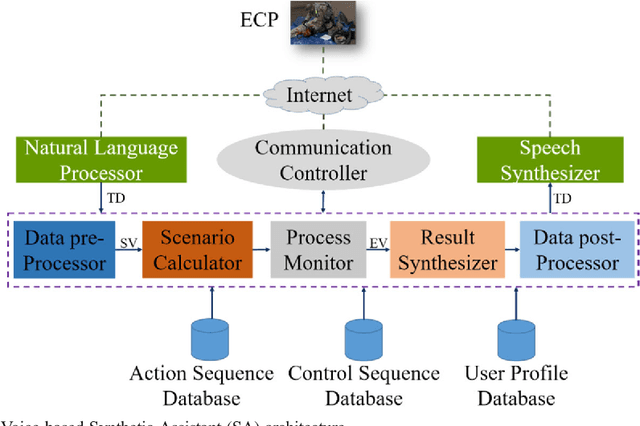
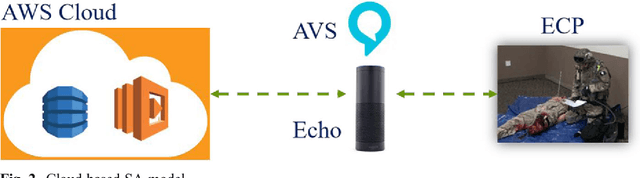


As part of a perennial project, our team is actively engaged in developing new synthetic assistant (SA) technologies to assist in training combat medics and medical first responders. It is critical that medical first responders are well trained to deal with emergencies more effectively. This would require real-time monitoring and feedback for each trainee. Therefore, we introduced a voice-based SA to augment the training process of medical first responders and enhance their performance in the field. The potential benefits of SAs include a reduction in training costs and enhanced monitoring mechanisms. Despite the increased usage of voice-based personal assistants (PAs) in day-to-day life, the associated effects are commonly neglected for a study of human factors. Therefore, this paper focuses on performance analysis of the developed voice-based SA in emergency care provider training for a selected emergency treatment scenario. The research discussed in this paper follows design science in developing proposed technology; at length, we discussed architecture and development and presented working results of voice-based SA. The empirical testing was conducted on two groups as user studies using statistical analysis tools, one trained with conventional methods and the other with the help of SA. The statistical results demonstrated the amplification in training efficacy and performance of medical responders powered by SA. Furthermore, the paper also discusses the accuracy and time of task execution (t) and concludes with the guidelines for resolving the identified problems.
Common Metrics to Benchmark Human-Machine Teams (HMT): A Review
Aug 11, 2020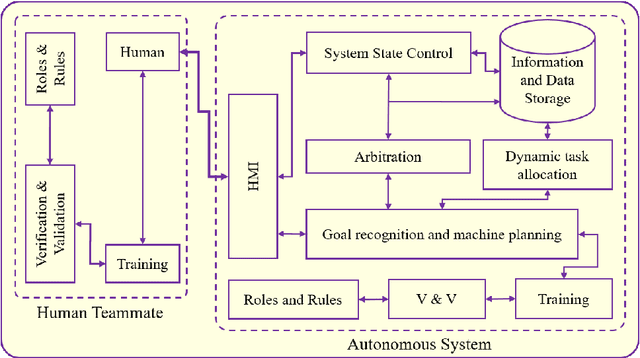
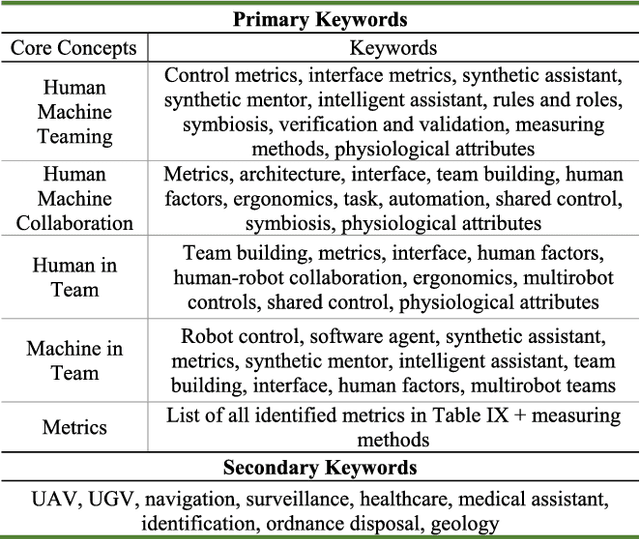

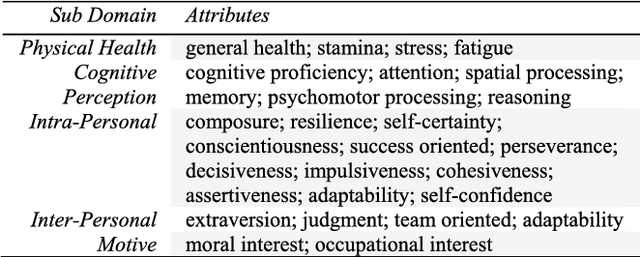
A significant amount of work is invested in human-machine teaming (HMT) across multiple fields. Accurately and effectively measuring system performance of an HMT is crucial for moving the design of these systems forward. Metrics are the enabling tools to devise a benchmark in any system and serve as an evaluation platform for assessing the performance, along with the verification and validation, of a system. Currently, there is no agreed-upon set of benchmark metrics for developing HMT systems. Therefore, identification and classification of common metrics are imperative to create a benchmark in the HMT field. The key focus of this review is to conduct a detailed survey aimed at identification of metrics employed in different segments of HMT and to determine the common metrics that can be used in the future to benchmark HMTs. We have organized this review as follows: identification of metrics used in HMTs until now, and classification based on functionality and measuring techniques. Additionally, we have also attempted to analyze all the identified metrics in detail while classifying them as theoretical, applied, real-time, non-real-time, measurable, and observable metrics. We conclude this review with a detailed analysis of the identified common metrics along with their usage to benchmark HMTs.