 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmented Harmonic Loss: Handling Class-Imbalanced Multi-Label Clinical Data for Medical Coding with Large Language Models
Oct 06, 2023The precipitous rise and adoption of Large Language Models (LLMs) have shattered expectations with the fastest adoption rate of any consumer-facing technology in history. Healthcare, a field that traditionally uses NLP techniques, was bound to be affected by this meteoric rise. In this paper, we gauge the extent of the impact by evaluating the performance of LLMs for the task of medical coding on real-life noisy data. We conducted several experiments on MIMIC III and IV datasets with encoder-based LLMs, such as BERT. Furthermore, we developed Segmented Harmonic Loss, a new loss function to address the extreme class imbalance that we found to prevail in most medical data in a multi-label scenario by segmenting and decoupling co-occurring classes of the dataset with a new segmentation algorithm. We also devised a technique based on embedding similarity to tackle noisy data. Our experimental results show that when trained with the proposed loss, the LLMs achieve significant performance gains even on noisy long-tailed datasets, outperforming the F1 score of the state-of-the-art by over ten percentage points.
The IIT Bombay English-Hindi Parallel Corpus
May 19, 2018
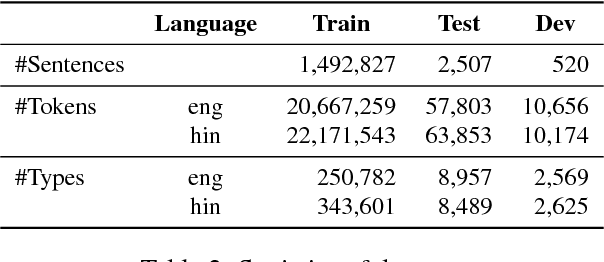
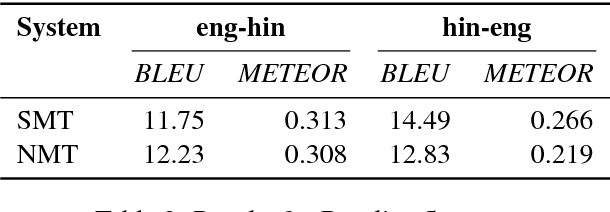
We present the IIT Bombay English-Hindi Parallel Corpus. The corpus is a compilation of parallel corpora previously available in the public domain as well as new parallel corpora we collected. The corpus contains 1.49 million parallel segments, of which 694k segments were not previously available in the public domain. The corpus has been pre-processed for machine translation, and we report baseline phrase-based SMT and NMT translation results on this corpus. This corpus has been used in two editions of shared tasks at the Workshop on Asian Language Translation (2016 and 2017). The corpus is freely available for non-commercial research. To the best of our knowledge, this is the largest publicly available English-Hindi parallel corpus.