 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning Schemes for Power Allocation in Energy Harvesting Communications
Aug 26, 2016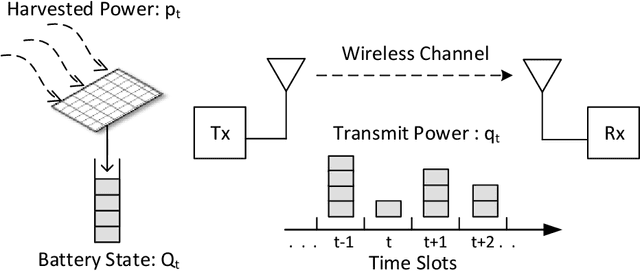
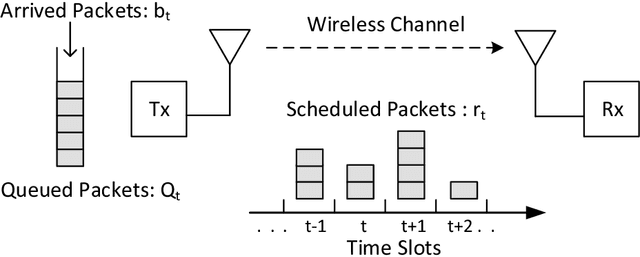
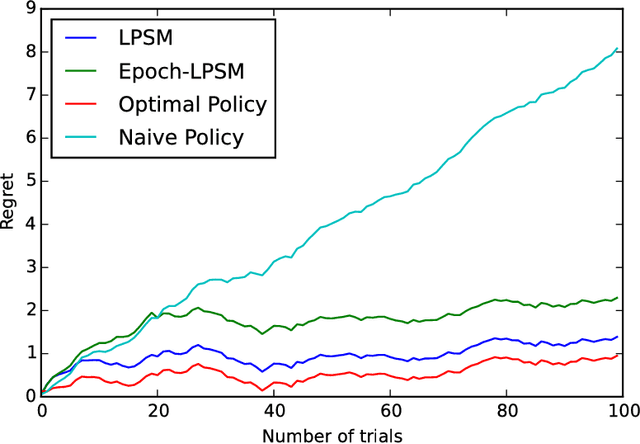
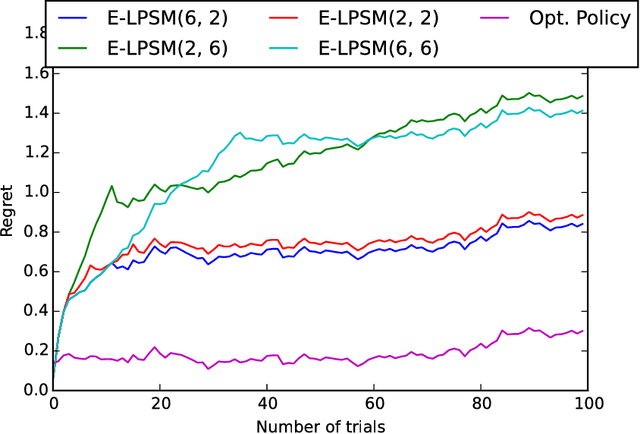
We consider the problem of power allocation over a time-varying channel with unknown distribution in energy harvesting communication systems. In this problem, the transmitter has to choose the transmit power based on the amount of stored energy in its battery with the goal of maximizing the average rate obtained over time. We model this problem as a Markov decision process (MDP) with the transmitter as the agent, the battery status as the state, the transmit power as the action and the rate obtained as the reward. The average reward maximization problem over the MDP can be solved by a linear program (LP) that uses the transition probabilities for the state-action pairs and their reward values to choose a power allocation policy. Since the rewards associated the state-action pairs are unknown, we propose two online learning algorithms: UCLP and Epoch-UCLP that learn these rewards and adapt their policies along the way. The UCLP algorithm solves the LP at each step to decide its current policy using the upper confidence bounds on the rewards, while the Epoch-UCLP algorithm divides the time into epochs, solves the LP only at the beginning of the epochs and follows the obtained policy in that epoch. We prove that the reward losses or regrets incurred by both these algorithms are upper bounded by constants. Epoch-UCLP incurs a higher regret compared to UCLP, but reduces the computational requirements substantially. We also show that the presented algorithms work for online learning in cost minimization problems like the packet scheduling with power-delay tradeoff with minor changes.
Stochastic Contextual Bandits with Known Reward Functions
May 06, 2016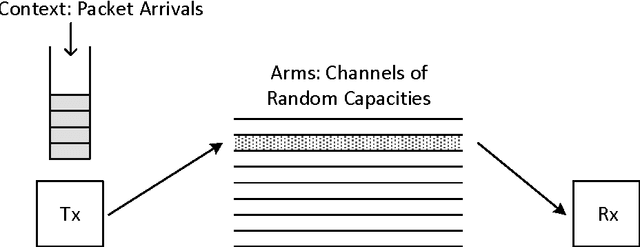
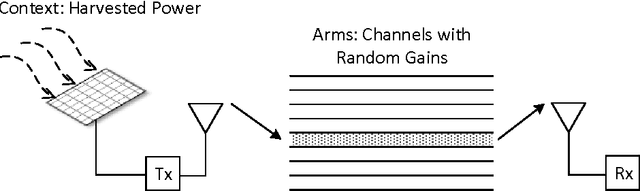
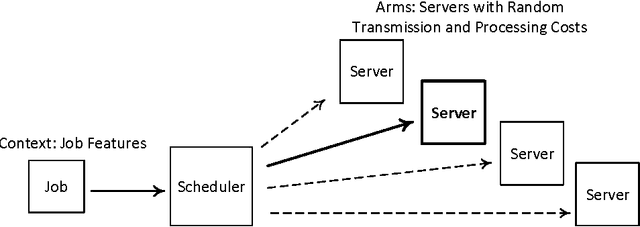
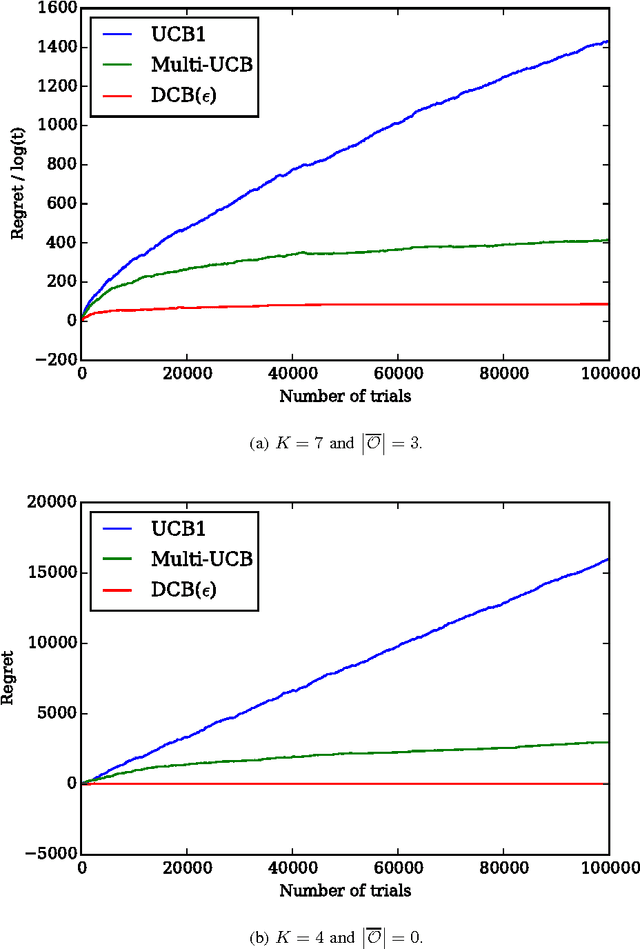
Many sequential decision-making problems in communication networks can be modeled as contextual bandit problems, which are natural extensions of the well-known multi-armed bandit problem. In contextual bandit problems, at each time, an agent observes some side information or context, pulls one arm and receives the reward for that arm. We consider a stochastic formulation where the context-reward tuples are independently drawn from an unknown distribution in each trial. Motivated by networking applications, we analyze a setting where the reward is a known non-linear function of the context and the chosen arm's current state. We first consider the case of discrete and finite context-spaces and propose DCB($\epsilon$), an algorithm that we prove, through a careful analysis, yields regret (cumulative reward gap compared to a distribution-aware genie) scaling logarithmically in time and linearly in the number of arms that are not optimal for any context, improving over existing algorithms where the regret scales linearly in the total number of arms. We then study continuous context-spaces with Lipschitz reward functions and propose CCB($\epsilon, \delta$), an algorithm that uses DCB($\epsilon$) as a subroutine. CCB($\epsilon, \delta$) reveals a novel regret-storage trade-off that is parametrized by $\delta$. Tuning $\delta$ to the time horizon allows us to obtain sub-linear regret bounds, while requiring sub-linear storage. By exploiting joint learning for all contexts we get regret bounds for CCB($\epsilon, \delta$) that are unachievable by any existing contextual bandit algorithm for continuous context-spaces. We also show similar performance bounds for the unknown horizon case.