 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Sensitive Malicious Spelling Error Correction
Jan 23, 2019
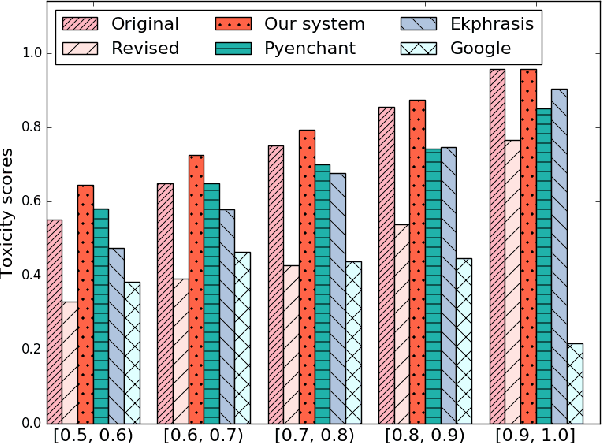

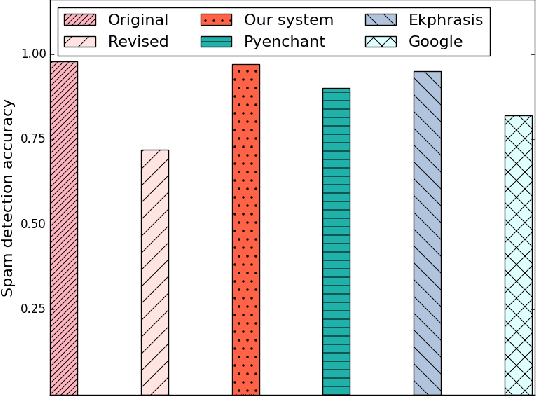
Misspelled words of the malicious kind work by changing specific keywords and are intended to thwart existing automated applications for cyber-environment control such as harassing content detection on the Internet and email spam detection. In this paper, we focus on malicious spelling correction, which requires an approach that relies on the context and the surface forms of targeted keywords. In the context of two applications--profanity detection and email spam detection--we show that malicious misspellings seriously degrade their performance. We then propose a context-sensitive approach for malicious spelling correction using word embeddings and demonstrate its superior performance compared to state-of-the-art spell checkers.
LEARN Codes: Inventing Low-latency Codes via Recurrent Neural Networks
Nov 30, 2018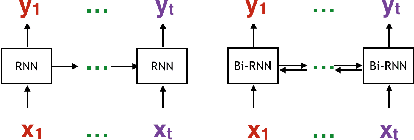
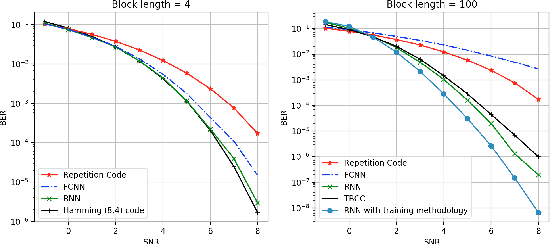
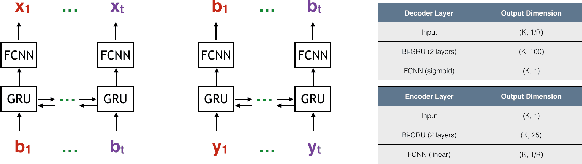
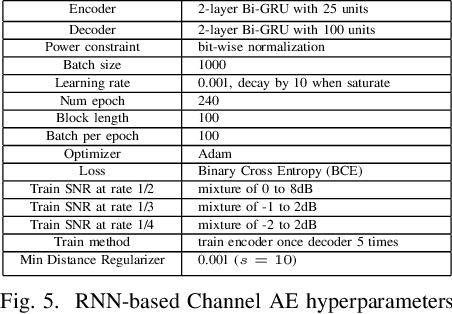
Designing channel codes under low latency constraints is one of the most demanding requirements in 5G standards. However, sharp characterizations of the performances of traditional codes are only available in the large block-length limit. Code designs are guided by those asymptotic analyses and require large block lengths and long latency to achieve the desired error rate. Furthermore, when the codes designed for one channel (e.g. Additive White Gaussian Noise (AWGN) channel) are used for another (e.g. non-AWGN channels), heuristics are necessary to achieve any nontrivial performance -thereby severely lacking in robustness as well as adaptivity. Obtained by jointly designing Recurrent Neural Network (RNN) based encoder and decoder, we propose an end-to-end learned neural code which outperforms canonical convolutional code under block settings. With this gained experience of designing a novel neural block code, we propose a new class of codes under low latency constraint - Low-latency Efficient Adaptive Robust Neural (LEARN) codes, which outperforms the state-of-the-art low latency codes as well as exhibits robustness and adaptivity properties. LEARN codes show the potential of designing new versatile and universal codes for future communications via tools of modern deep learning coupled with communication engineering insights.
Estimating Mutual Information for Discrete-Continuous Mixtures
Oct 09, 2018
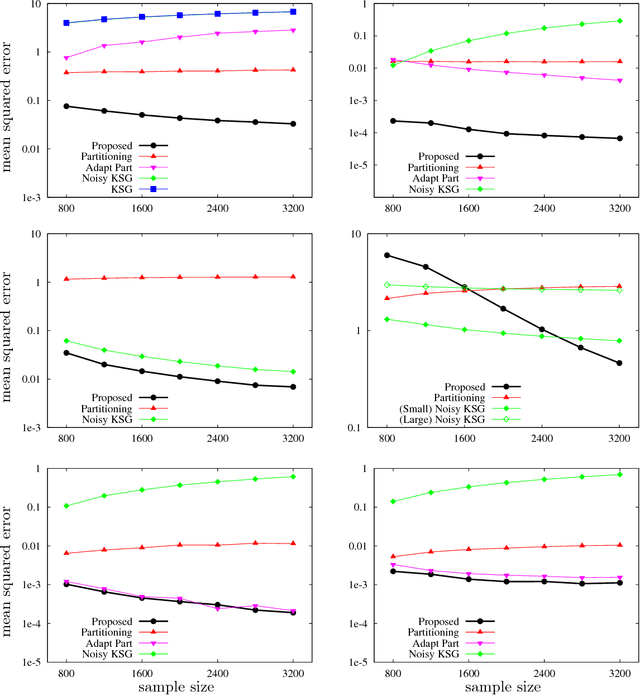
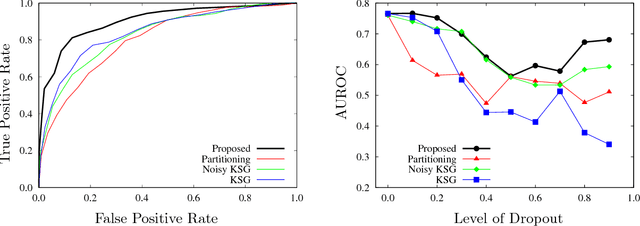
Estimating mutual information from observed samples is a basic primitive, useful in several machine learning tasks including correlation mining, information bottleneck clustering, learning a Chow-Liu tree, and conditional independence testing in (causal) graphical models. While mutual information is a well-defined quantity in general probability spaces, existing estimators can only handle two special cases of purely discrete or purely continuous pairs of random variables. The main challenge is that these methods first estimate the (differential) entropies of X, Y and the pair (X;Y) and add them up with appropriate signs to get an estimate of the mutual information. These 3H-estimators cannot be applied in general mixture spaces, where entropy is not well-defined. In this paper, we design a novel estimator for mutual information of discrete-continuous mixtures. We prove that the proposed estimator is consistent. We provide numerical experiments suggesting superiority of the proposed estimator compared to other heuristics of adding small continuous noise to all the samples and applying standard estimators tailored for purely continuous variables, and quantizing the samples and applying standard estimators tailored for purely discrete variables. This significantly widens the applicability of mutual information estimation in real-world applications, where some variables are discrete, some continuous, and others are a mixture between continuous and discrete components.
Learning One-hidden-layer Neural Networks under General Input Distributions
Oct 09, 2018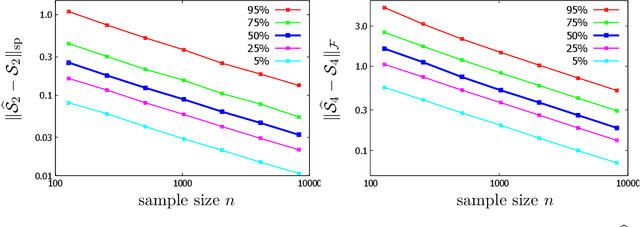
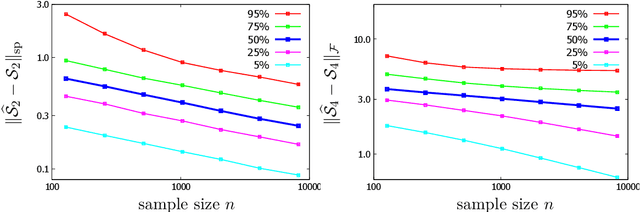
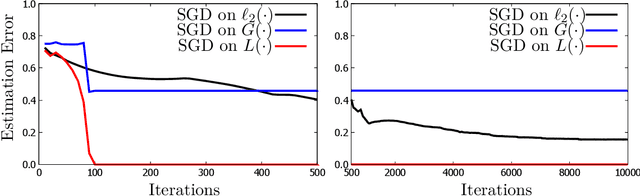
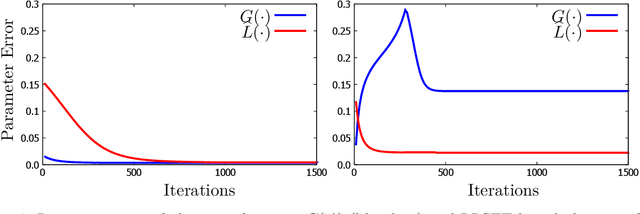
Significant advances have been made recently on training neural networks, where the main challenge is in solving an optimization problem with abundant critical points. However, existing approaches to address this issue crucially rely on a restrictive assumption: the training data is drawn from a Gaussian distribution. In this paper, we provide a novel unified framework to design loss functions with desirable landscape properties for a wide range of general input distributions. On these loss functions, remarkably, stochastic gradient descent theoretically recovers the true parameters with global initializations and empirically outperforms the existing approaches. Our loss function design bridges the notion of score functions with the topic of neural network optimization. Central to our approach is the task of estimating the score function from samples, which is of basic and independent interest to theoretical statistics. Traditional estimation methods (example: kernel based) fail right at the outset; we bring statistical methods of local likelihood to design a novel estimator of score functions, that provably adapts to the local geometry of the unknown density.
Graph2Seq: Scalable Learning Dynamics for Graphs
Oct 09, 2018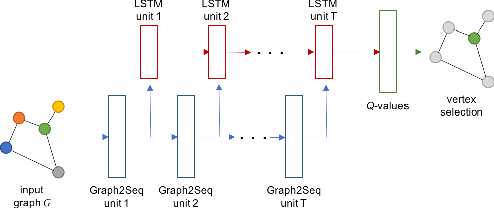
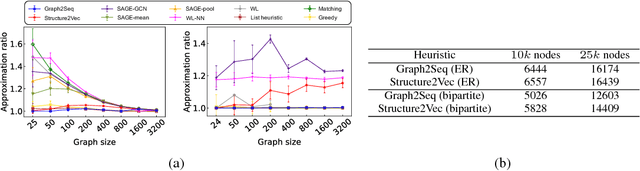
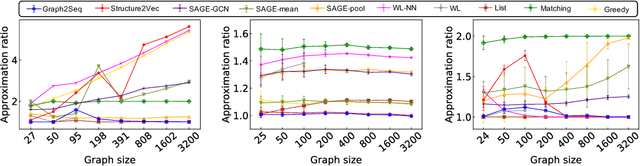
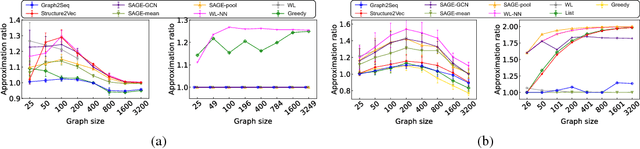
Neural networks have been shown to be an effective tool for learning algorithms over graph-structured data. However, graph representation techniques---that convert graphs to real-valued vectors for use with neural networks---are still in their infancy. Recent works have proposed several approaches (e.g., graph convolutional networks), but these methods have difficulty scaling and generalizing to graphs with different sizes and shapes. We present Graph2Seq, a new technique that represents vertices of graphs as infinite time-series. By not limiting the representation to a fixed dimension, Graph2Seq scales naturally to graphs of arbitrary sizes and shapes. Graph2Seq is also reversible, allowing full recovery of the graph structure from the sequences. By analyzing a formal computational model for graph representation, we show that an unbounded sequence is necessary for scalability. Our experimental results with Graph2Seq show strong generalization and new state-of-the-art performance on a variety of graph combinatorial optimization problems.
Breaking the gridlock in Mixture-of-Experts: Consistent and Efficient Algorithms
Oct 09, 2018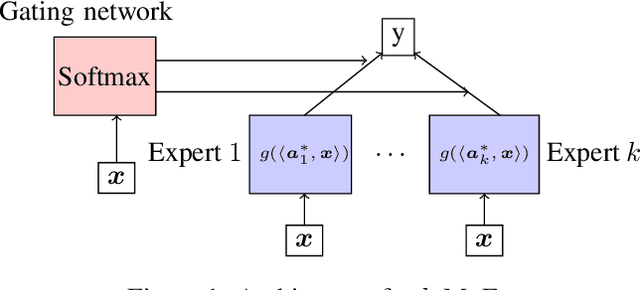

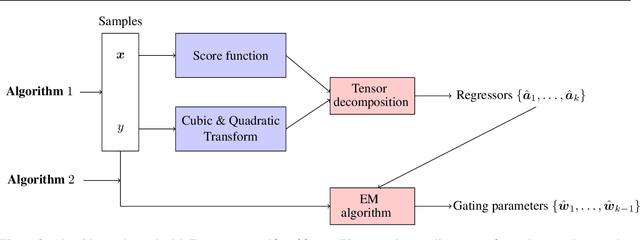
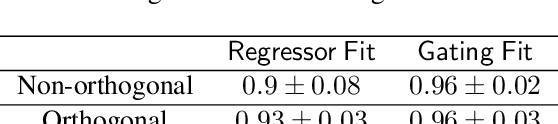
Mixture-of-Experts (MoE) is a widely popular model for ensemble learning and is a basic building block of highly successful modern neural networks as well as a component in Gated Recurrent Units (GRU) and Attention networks. However, present algorithms for learning MoE including the EM algorithm, and gradient descent are known to get stuck in local optima. From a theoretical viewpoint, finding an efficient and provably consistent algorithm to learn the parameters remains a long standing open problem for more than two decades. In this paper, we introduce the first algorithm that learns the true parameters of a MoE model for a wide class of non-linearities with global consistency guarantees. While existing algorithms jointly or iteratively estimate the expert parameters and the gating paramters in the MoE, we propose a novel algorithm that breaks the deadlock and can directly estimate the expert parameters by sensing its echo in a carefully designed cross-moment tensor between the inputs and the output. Once the experts are known, the recovery of gating parameters still requires an EM algorithm; however, we show that the EM algorithm for this simplified problem, unlike the joint EM algorithm, converges to the true parameters. We empirically validate our algorithm on both the synthetic and real data sets in a variety of settings, and show superior performance to standard baselines.
Deepcode: Feedback Codes via Deep Learning
Jul 02, 2018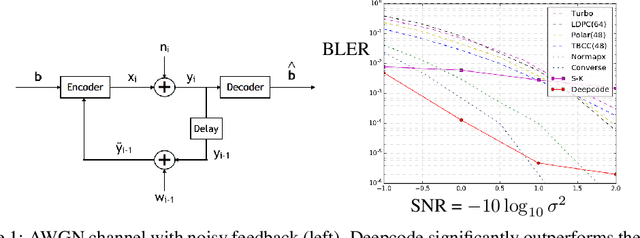
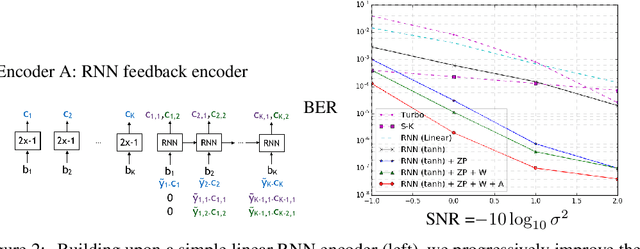
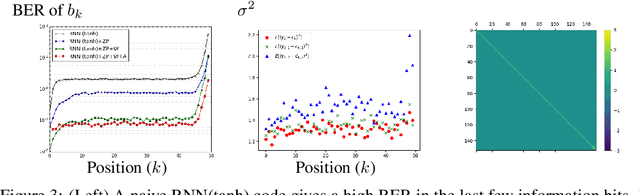
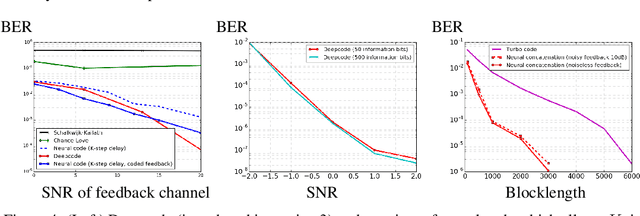
The design of codes for communicating reliably over a statistically well defined channel is an important endeavor involving deep mathematical research and wide-ranging practical applications. In this work, we present the first family of codes obtained via deep learning, which significantly beats state-of-the-art codes designed over several decades of research. The communication channel under consideration is the Gaussian noise channel with feedback, whose study was initiated by Shannon; feedback is known theoretically to improve reliability of communication, but no practical codes that do so have ever been successfully constructed. We break this logjam by integrating information theoretic insights harmoniously with recurrent-neural-network based encoders and decoders to create novel codes that outperform known codes by 3 orders of magnitude in reliability. We also demonstrate several desirable properties of the codes: (a) generalization to larger block lengths, (b) composability with known codes, (c) adaptation to practical constraints. This result also has broader ramifications for coding theory: even when the channel has a clear mathematical model, deep learning methodologies, when combined with channel-specific information-theoretic insights, can potentially beat state-of-the-art codes constructed over decades of mathematical research.
Embedding Syntax and Semantics of Prepositions via Tensor Decomposition
May 23, 2018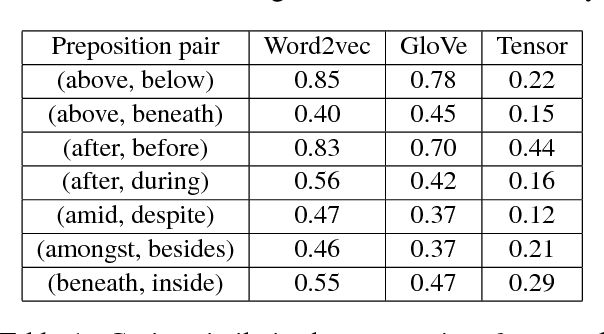
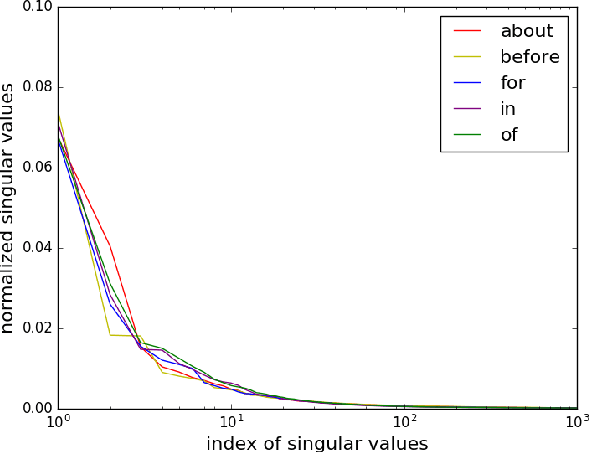

Prepositions are among the most frequent words in English and play complex roles in the syntax and semantics of sentences. Not surprisingly, they pose well-known difficulties in automatic processing of sentences (prepositional attachment ambiguities and idiosyncratic uses in phrases). Existing methods on preposition representation treat prepositions no different from content words (e.g., word2vec and GloVe). In addition, recent studies aiming at solving prepositional attachment and preposition selection problems depend heavily on external linguistic resources and use dataset-specific word representations. In this paper we use word-triple counts (one of the triples being a preposition) to capture a preposition's interaction with its attachment and complement. We then derive preposition embeddings via tensor decomposition on a large unlabeled corpus. We reveal a new geometry involving Hadamard products and empirically demonstrate its utility in paraphrasing phrasal verbs. Furthermore, our preposition embeddings are used as simple features in two challenging downstream tasks: preposition selection and prepositional attachment disambiguation. We achieve results comparable to or better than the state-of-the-art on multiple standardized datasets.
Communication Algorithms via Deep Learning
May 23, 2018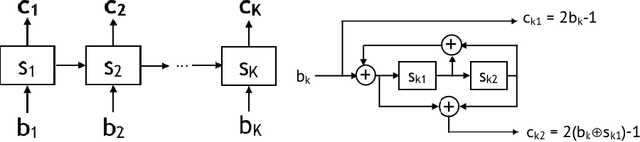
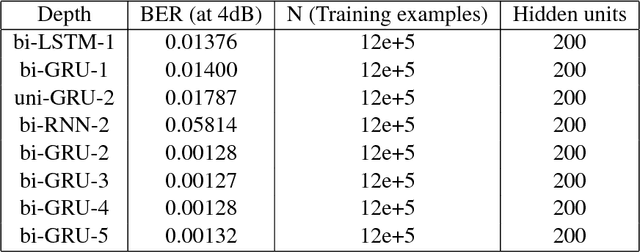
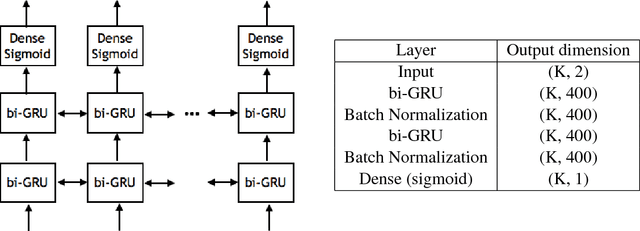
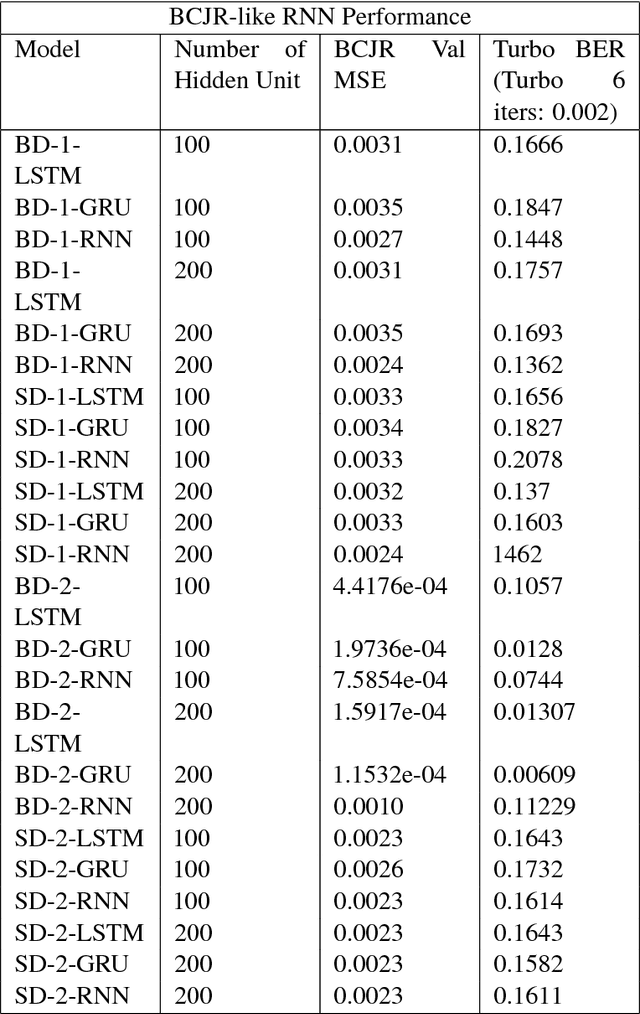
Coding theory is a central discipline underpinning wireline and wireless modems that are the workhorses of the information age. Progress in coding theory is largely driven by individual human ingenuity with sporadic breakthroughs over the past century. In this paper we study whether it is possible to automate the discovery of decoding algorithms via deep learning. We study a family of sequential codes parameterized by recurrent neural network (RNN) architectures. We show that creatively designed and trained RNN architectures can decode well known sequential codes such as the convolutional and turbo codes with close to optimal performance on the additive white Gaussian noise (AWGN) channel, which itself is achieved by breakthrough algorithms of our times (Viterbi and BCJR decoders, representing dynamic programing and forward-backward algorithms). We show strong generalizations, i.e., we train at a specific signal to noise ratio and block length but test at a wide range of these quantities, as well as robustness and adaptivity to deviations from the AWGN setting.
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
Mar 19, 2018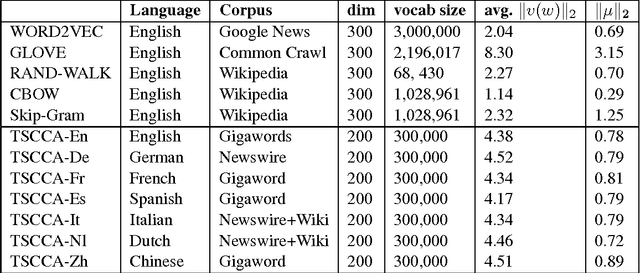
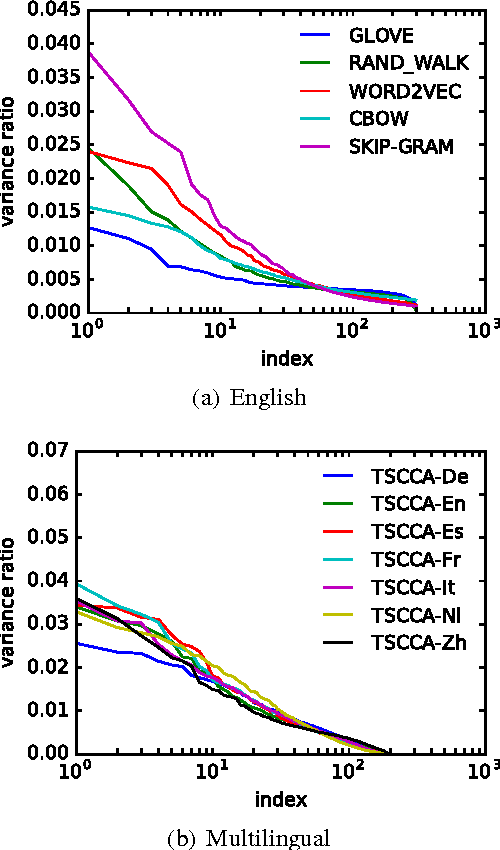
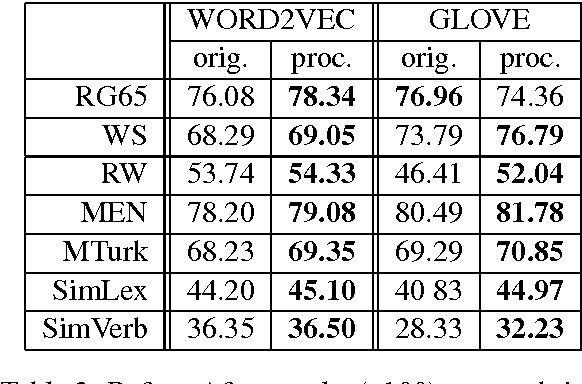
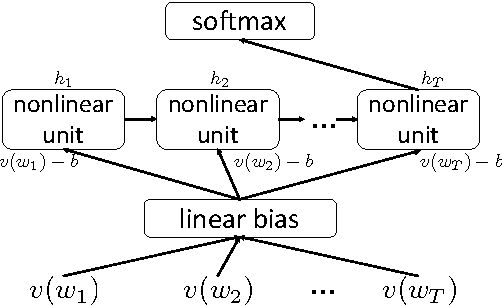
Real-valued word representations have transformed NLP applications; popular examples are word2vec and GloVe, recognized for their ability to capture linguistic regularities. In this paper, we demonstrate a {\em very simple}, and yet counter-intuitive, postprocessing technique -- eliminate the common mean vector and a few top dominating directions from the word vectors -- that renders off-the-shelf representations {\em even stronger}. The postprocessing is empirically validated on a variety of lexical-level intrinsic tasks (word similarity, concept categorization, word analogy) and sentence-level tasks (semantic textural similarity and { text classification}) on multiple datasets and with a variety of representation methods and hyperparameter choices in multiple languages; in each case, the processed representations are consistently better than the original ones.