 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPolar: Inventing Nonlinear Large-Kernel Polar Codes via Deep Learning
Feb 14, 2024



Polar codes, developed on the foundation of Arikan's polarization kernel, represent a breakthrough in coding theory and have emerged as the state-of-the-art error-correction-code in short-to-medium block length regimes. Importantly, recent research has indicated that the reliability of polar codes can be further enhanced by substituting Arikan's kernel with a larger one, leading to a faster polarization. However, for short-to-medium block length regimes, the development of polar codes that effectively employ large kernel sizes has not yet been realized. In this paper, we explore a novel, non-linear generalization of polar codes with an expanded kernel size, which we call DeepPolar codes. Our results show that DeepPolar codes effectively utilize the benefits of larger kernel size, resulting in enhanced reliability compared to both the existing neural codes and conventional polar codes.
ZeroSwap: Data-driven Optimal Market Making in DeFi
Oct 13, 2023



Automated Market Makers (AMMs) are major centers of matching liquidity supply and demand in Decentralized Finance. Their functioning relies primarily on the presence of liquidity providers (LPs) incentivized to invest their assets into a liquidity pool. However, the prices at which a pooled asset is traded is often more stale than the prices on centralized and more liquid exchanges. This leads to the LPs suffering losses to arbitrage. This problem is addressed by adapting market prices to trader behavior, captured via the classical market microstructure model of Glosten and Milgrom. In this paper, we propose the first optimal Bayesian and the first model-free data-driven algorithm to optimally track the external price of the asset. The notion of optimality that we use enforces a zero-profit condition on the prices of the market maker, hence the name ZeroSwap. This ensures that the market maker balances losses to informed traders with profits from noise traders. The key property of our approach is the ability to estimate the external market price without the need for price oracles or loss oracles. Our theoretical guarantees on the performance of both these algorithms, ensuring the stability and convergence of their price recommendations, are of independent interest in the theory of reinforcement learning. We empirically demonstrate the robustness of our algorithms to changing market conditions.
Machine Learning-Aided Efficient Decoding of Reed-Muller Subcodes
Jan 16, 2023



Reed-Muller (RM) codes achieve the capacity of general binary-input memoryless symmetric channels and have a comparable performance to that of random codes in terms of scaling laws. However, they lack efficient decoders with performance close to that of a maximum-likelihood decoder for general code parameters. Also, they only admit limited sets of rates. In this paper, we focus on subcodes of RM codes with flexible rates. We first extend the recently-introduced recursive projection-aggregation (RPA) decoding algorithm to RM subcodes. To lower the complexity of our decoding algorithm, referred to as subRPA, we investigate different approaches to prune the projections. Next, we derive the soft-decision based version of our algorithm, called soft-subRPA, that not only improves upon the performance of subRPA but also enables a differentiable decoding algorithm. Building upon the soft-subRPA algorithm, we then provide a framework for training a machine learning (ML) model to search for \textit{good} sets of projections that minimize the decoding error rate. Training our ML model enables achieving very close to the performance of full-projection decoding with a significantly smaller number of projections. We also show that the choice of the projections in decoding RM subcodes matters significantly, and our ML-aided projection pruning scheme is able to find a \textit{good} selection, i.e., with negligible performance degradation compared to the full-projection case, given a reasonable number of projections.
CRISP: Curriculum based Sequential Neural Decoders for Polar Code Family
Oct 01, 2022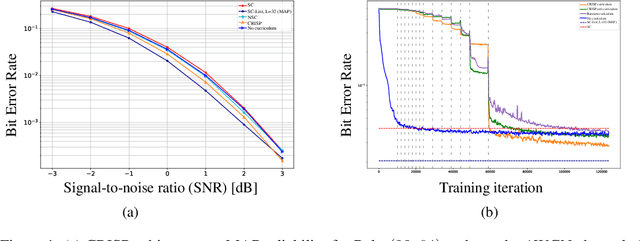
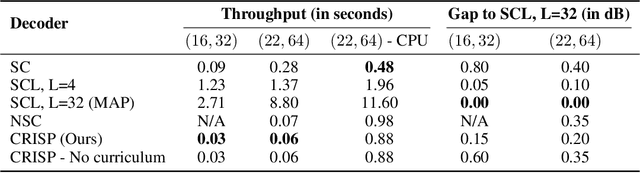
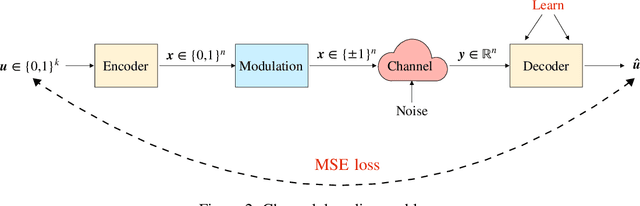
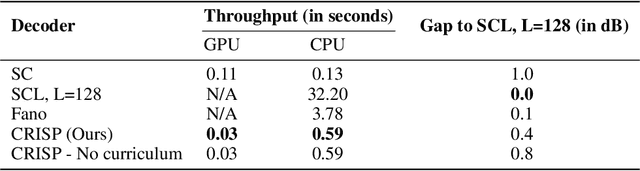
Polar codes are widely used state-of-the-art codes for reliable communication that have recently been included in the 5th generation wireless standards (5G). However, there remains room for the design of polar decoders that are both efficient and reliable in the short blocklength regime. Motivated by recent successes of data-driven channel decoders, we introduce a novel $\textbf{C}$ur$\textbf{RI}$culum based $\textbf{S}$equential neural decoder for $\textbf{P}$olar codes (CRISP). We design a principled curriculum, guided by information-theoretic insights, to train CRISP and show that it outperforms the successive-cancellation (SC) decoder and attains near-optimal reliability performance on the Polar(16,32) and Polar(22, 64) codes. The choice of the proposed curriculum is critical in achieving the accuracy gains of CRISP, as we show by comparing against other curricula. More notably, CRISP can be readily extended to Polarization-Adjusted-Convolutional (PAC) codes, where existing SC decoders are significantly less reliable. To the best of our knowledge, CRISP constructs the first data-driven decoder for PAC codes and attains near-optimal performance on the PAC(16, 32) code.
TinyTurbo: Efficient Turbo Decoders on Edge
Sep 30, 2022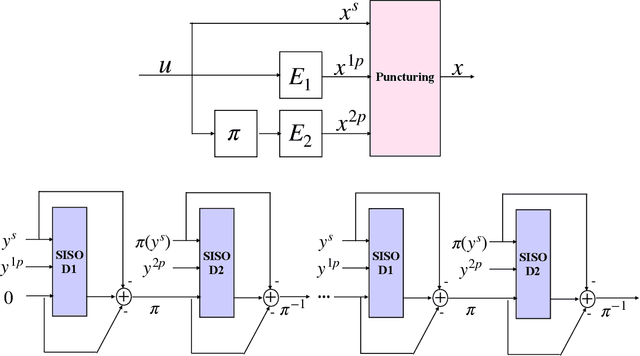

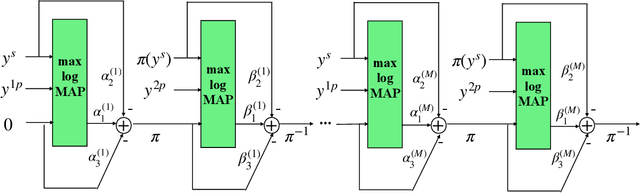
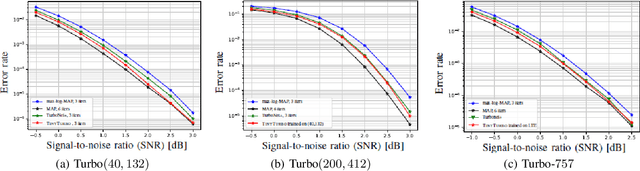
In this paper, we introduce a neural-augmented decoder for Turbo codes called TINYTURBO . TINYTURBO has complexity comparable to the classical max-log-MAP algorithm but has much better reliability than the max-log-MAP baseline and performs close to the MAP algorithm. We show that TINYTURBO exhibits strong robustness on a variety of practical channels of interest, such as EPA and EVA channels, which are included in the LTE standards. We also show that TINYTURBO strongly generalizes across different rate, blocklengths, and trellises. We verify the reliability and efficiency of TINYTURBO via over-the-air experiments.
* 10 pages, 6 figures. Published at the 2022 IEEE International Symposium on Information Theory (ISIT)
KO codes: Inventing Nonlinear Encoding and Decoding for Reliable Wireless Communication via Deep-learning
Aug 29, 2021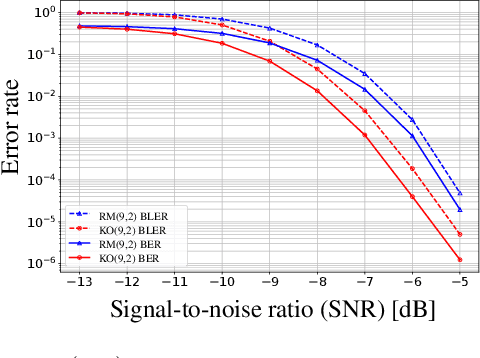
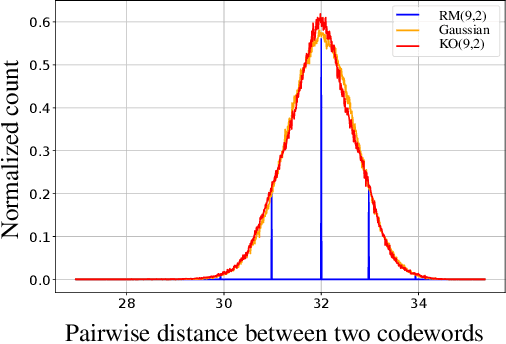
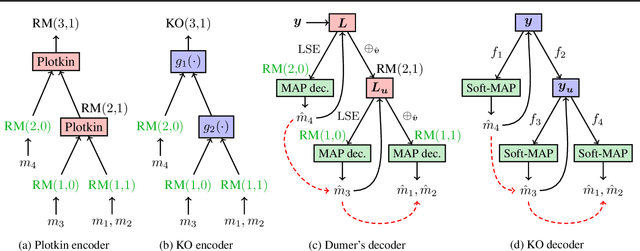
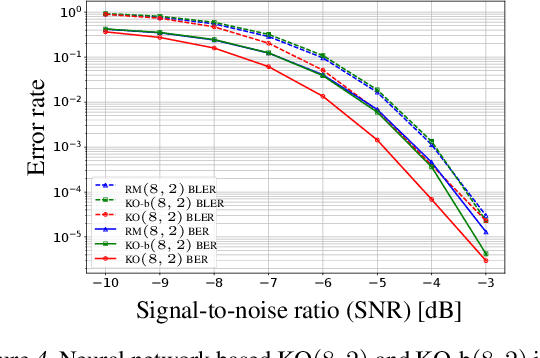
Landmark codes underpin reliable physical layer communication, e.g., Reed-Muller, BCH, Convolution, Turbo, LDPC and Polar codes: each is a linear code and represents a mathematical breakthrough. The impact on humanity is huge: each of these codes has been used in global wireless communication standards (satellite, WiFi, cellular). Reliability of communication over the classical additive white Gaussian noise (AWGN) channel enables benchmarking and ranking of the different codes. In this paper, we construct KO codes, a computationaly efficient family of deep-learning driven (encoder, decoder) pairs that outperform the state-of-the-art reliability performance on the standardized AWGN channel. KO codes beat state-of-the-art Reed-Muller and Polar codes, under the low-complexity successive cancellation decoding, in the challenging short-to-medium block length regime on the AWGN channel. We show that the gains of KO codes are primarily due to the nonlinear mapping of information bits directly to transmit real symbols (bypassing modulation) and yet possess an efficient, high performance decoder. The key technical innovation that renders this possible is design of a novel family of neural architectures inspired by the computation tree of the {\bf K}ronecker {\bf O}peration (KO) central to Reed-Muller and Polar codes. These architectures pave way for the discovery of a much richer class of hitherto unexplored nonlinear algebraic structures. The code is available at \href{https://github.com/deepcomm/KOcodes}{https://github.com/deepcomm/KOcodes}
Enriching Word Embeddings with Temporal and Spatial Information
Oct 02, 2020
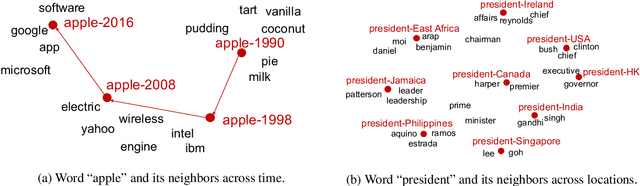
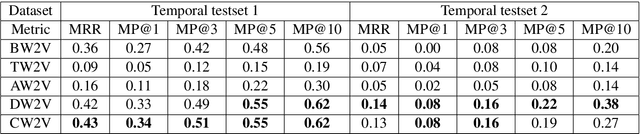
The meaning of a word is closely linked to sociocultural factors that can change over time and location, resulting in corresponding meaning changes. Taking a global view of words and their meanings in a widely used language, such as English, may require us to capture more refined semantics for use in time-specific or location-aware situations, such as the study of cultural trends or language use. However, popular vector representations for words do not adequately include temporal or spatial information. In this work, we present a model for learning word representation conditioned on time and location. In addition to capturing meaning changes over time and location, we require that the resulting word embeddings retain salient semantic and geometric properties. We train our model on time- and location-stamped corpora, and show using both quantitative and qualitative evaluations that it can capture semantics across time and locations. We note that our model compares favorably with the state-of-the-art for time-specific embedding, and serves as a new benchmark for location-specific embeddings.
Deepcode and Modulo-SK are Designed for Different Settings
Aug 18, 2020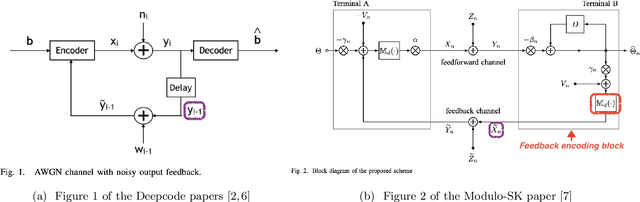

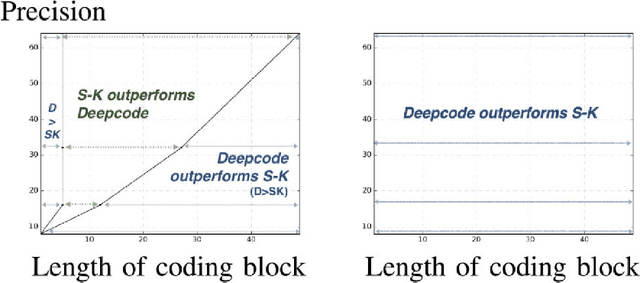
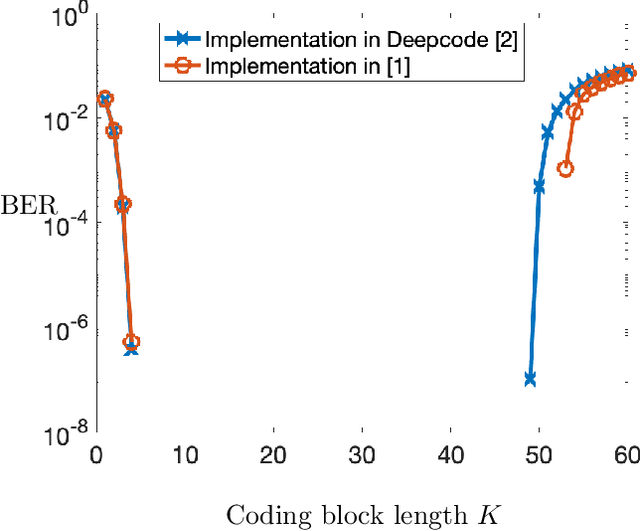
We respond to [1] which claimed that "Modulo-SK scheme outperforms Deepcode [2]". We demonstrate that this statement is not true: the two schemes are designed and evaluated for entirely different settings. DeepCode is designed and evaluated for the AWGN channel with (potentially delayed) uncoded output feedback. Modulo-SK is evaluated on the AWGN channel with coded feedback and unit delay. [1] also claimed an implementation of Schalkwijk and Kailath (SK) [3] which was numerically stable for any number of information bits and iterations. However, we observe that while their implementation does marginally improve over ours, it also suffers from a fundamental issue with precision. Finally, we show that Deepcode dominates the optimized performance of SK, over a natural choice of parameterizations when the feedback is noisy.
Turbo Autoencoder: Deep learning based channel codes for point-to-point communication channels
Nov 08, 2019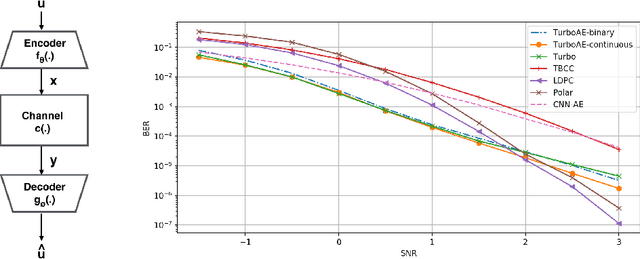

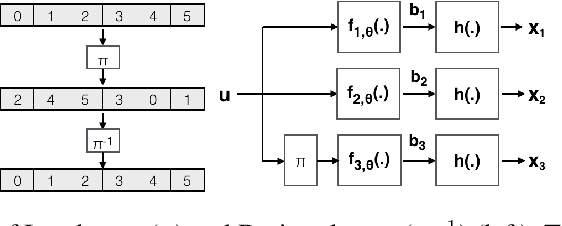

Designing codes that combat the noise in a communication medium has remained a significant area of research in information theory as well as wireless communications. Asymptotically optimal channel codes have been developed by mathematicians for communicating under canonical models after over 60 years of research. On the other hand, in many non-canonical channel settings, optimal codes do not exist and the codes designed for canonical models are adapted via heuristics to these channels and are thus not guaranteed to be optimal. In this work, we make significant progress on this problem by designing a fully end-to-end jointly trained neural encoder and decoder, namely, Turbo Autoencoder (TurboAE), with the following contributions: ($a$) under moderate block lengths, TurboAE approaches state-of-the-art performance under canonical channels; ($b$) moreover, TurboAE outperforms the state-of-the-art codes under non-canonical settings in terms of reliability. TurboAE shows that the development of channel coding design can be automated via deep learning, with near-optimal performance.
Learning in Gated Neural Networks
Jun 06, 2019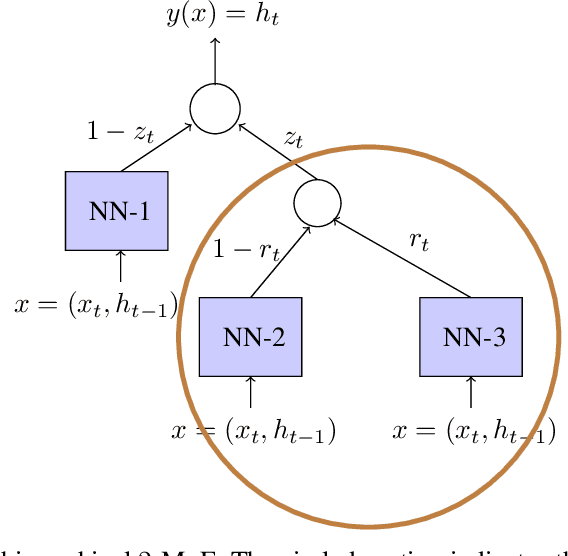
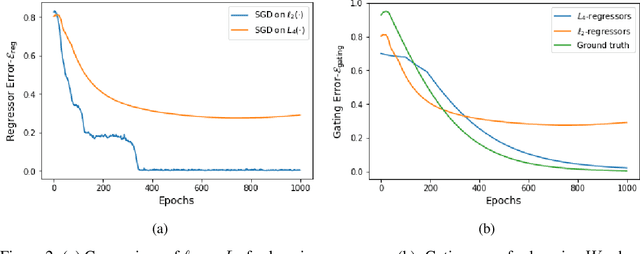
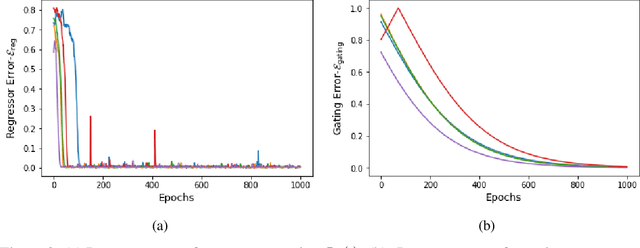
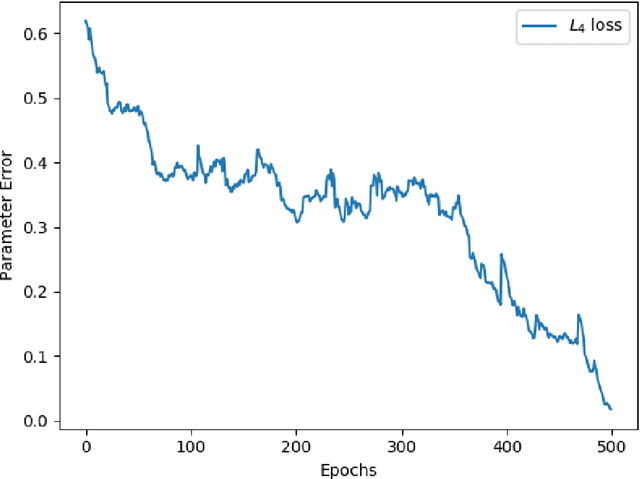
Gating is a key feature in modern neural networks including LSTMs, GRUs and sparsely-gated deep neural networks. The backbone of such gated networks is a mixture-of-experts layer, where several experts make regression decisions and gating controls how to weigh the decisions in an input-dependent manner. Despite having such a prominent role in both modern and classical machine learning, very little is understood about parameter recovery of mixture-of-experts since gradient descent and EM algorithms are known to be stuck in local optima in such models. In this paper, we perform a careful analysis of the optimization landscape and show that with appropriately designed loss functions, gradient descent can indeed learn the parameters accurately. A key idea underpinning our results is the design of two {\em distinct} loss functions, one for recovering the expert parameters and another for recovering the gating parameters. We demonstrate the first sample complexity results for parameter recovery in this model for any algorithm and demonstrate significant performance gains over standard loss functions in numerical experiments.