 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLitmus: Zero-Label, Code-Driven Metric Specification for Evaluating AI Systems
Jun 22, 2026As agentic LLM systems move from prototypes to deployment across increasingly diverse domains, evaluating them has become both more important and more difficult. The challenge is not only that individual metrics may be unreliable, but that evaluation goals are often left implicit. Without a clear account of what a system is expected to do, how it can fail, and which failures matter, metric choices become difficult to justify, interpret, or validate. We present Litmus, a zero-label system that designs evaluation and monitoring metrics for AI pipelines by eliciting evaluation intent from source code and targeted interrogation. Instead of assuming that the evaluation target is already known, Litmus first identifies what must be measured and why, then converts those answers into constraints for constructing a justified, per-stage metric portfolio. We evaluate Litmus on three real, code-defined AI pipelines - financial account grouping, scientific QA, and inherent risk assessment - against AutoMetrics and three DynamicRubric baselines. Litmus achieves the broadest or tied-broadest concern coverage, spans more pipeline stages, produces a near-zero-redundancy portfolio, and ranks first in validity against per-row quality labels on all three pipelines - decisively on scientific QA (Spearman $ρ=0.72$ vs. less than $0.47$ for every baseline), and within overlapping confidence intervals in relation to two components of the audit framework despite using no labels during metric design. Our results support a shift from automatic metric implementation to automatic metric specification: before asking which metric to compute, evaluation systems should ask what must be measured and why.
Early Diagnosis of Retinal Blood Vessel Damage via Deep Learning-Powered Collective Intelligence Models
Oct 17, 2022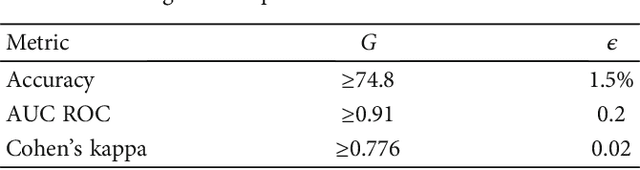
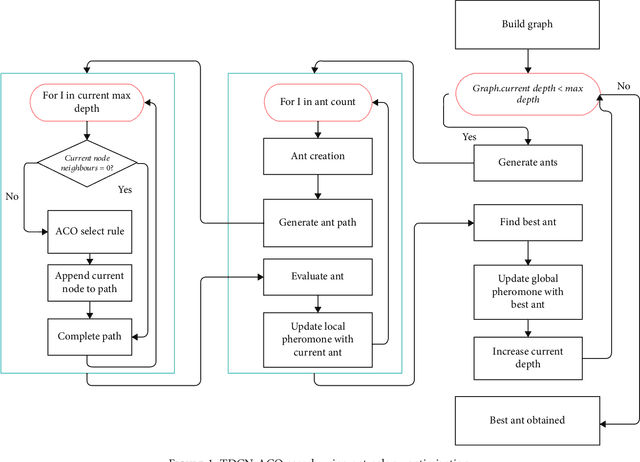

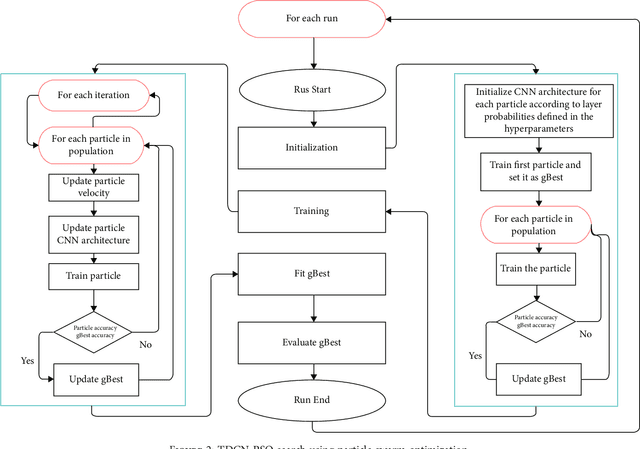
Early diagnosis of retinal diseases such as diabetic retinopathy has had the attention of many researchers. Deep learning through the introduction of convolutional neural networks has become a prominent solution for image-related tasks such as classification and segmentation. Most tasks in image classification are handled by deep CNNs pretrained and evaluated on imagenet dataset. However, these models do not always translate to the best result on other datasets. Devising a neural network manually from scratch based on heuristics may not lead to an optimal model as there are numerous hyperparameters in play. In this paper, we use two nature-inspired swarm algorithms: particle swarm optimization (PSO) and ant colony optimization (ACO) to obtain TDCN models to perform classification of fundus images into severity classes. The power of swarm algorithms is used to search for various combinations of convolutional, pooling, and normalization layers to provide the best model for the task. It is observed that TDCN-PSO outperforms imagenet models and existing literature, while TDCN-ACO achieves faster architecture search. The best TDCN model achieves an accuracy of 90.3%, AUC ROC of 0.956, and a Cohen kappa score of 0.967. The results were compared with the previous studies to show that the proposed TDCN models exhibit superior performance.