 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Control at the Edge with Language Models for Scene Understanding
May 09, 2025



In this paper, we present Optimized Prompt-based Unified System (OPUS), a framework that utilizes a Large Language Model (LLM) to control Pan-Tilt-Zoom (PTZ) cameras, providing contextual understanding of natural environments. To achieve this goal, the OPUS system improves cost-effectiveness by generating keywords from a high-level camera control API and transferring knowledge from larger closed-source language models to smaller ones through Supervised Fine-Tuning (SFT) on synthetic data. This enables efficient edge deployment while maintaining performance comparable to larger models like GPT-4. OPUS enhances environmental awareness by converting data from multiple cameras into textual descriptions for language models, eliminating the need for specialized sensory tokens. In benchmark testing, our approach significantly outperformed both traditional language model techniques and more complex prompting methods, achieving a 35% improvement over advanced techniques and a 20% higher task accuracy compared to closed-source models like Gemini Pro. The system demonstrates OPUS's capability to simplify PTZ camera operations through an intuitive natural language interface. This approach eliminates the need for explicit programming and provides a conversational method for interacting with camera systems, representing a significant advancement in how users can control and utilize PTZ camera technology.
Validation of Vector Data using Oblique Images
Jun 17, 2022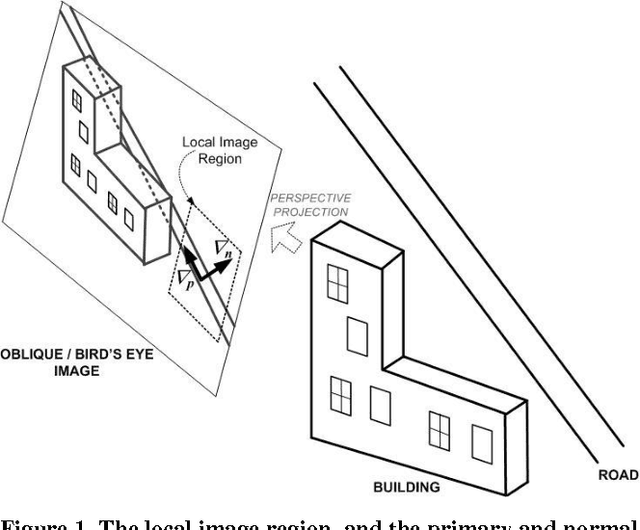
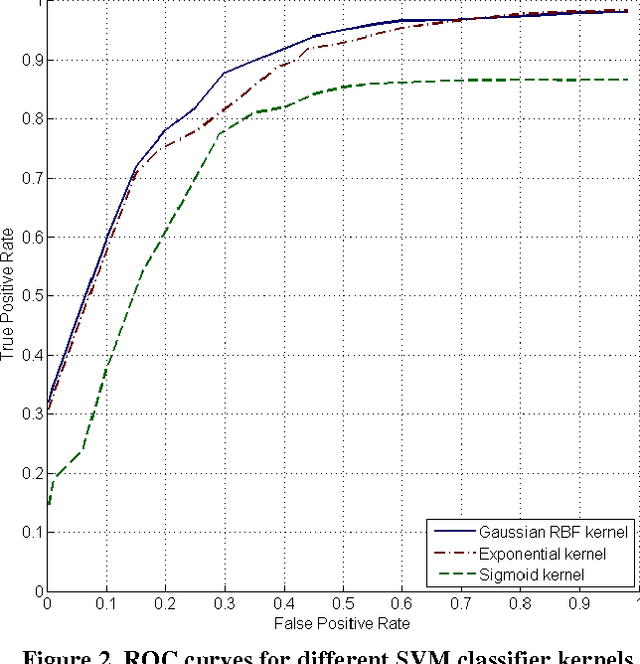
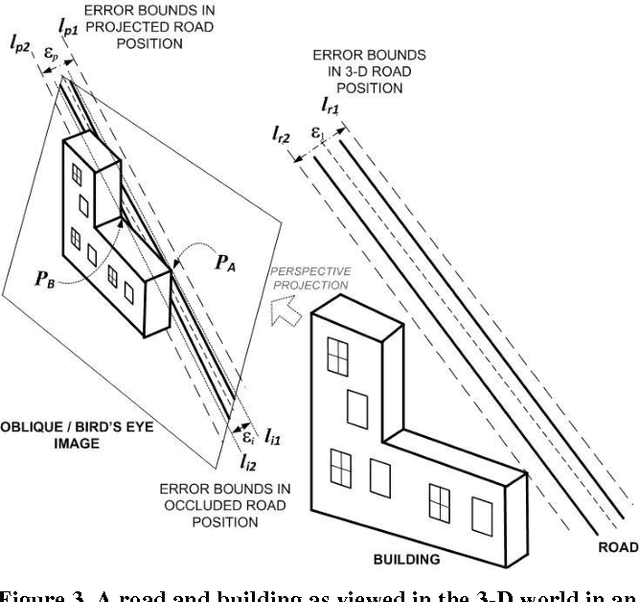
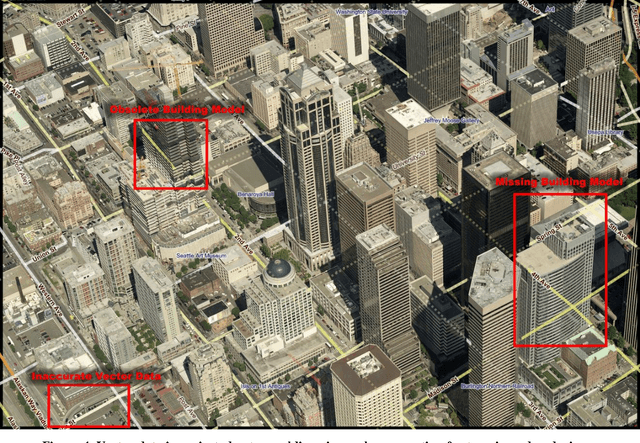
Oblique images are aerial photographs taken at oblique angles to the earth's surface. Projections of vector and other geospatial data in these images depend on camera parameters, positions of the geospatial entities, surface terrain, occlusions, and visibility. This paper presents a robust and scalable algorithm to detect inconsistencies in vector data using oblique images. The algorithm uses image descriptors to encode the local appearance of a geospatial entity in images. These image descriptors combine color, pixel-intensity gradients, texture, and steerable filter responses. A Support Vector Machine classifier is trained to detect image descriptors that are not consistent with underlying vector data, digital elevation maps, building models, and camera parameters. In this paper, we train the classifier on visible road segments and non-road data. Thereafter, the trained classifier detects inconsistencies in vectors, which include both occluded and misaligned road segments. The consistent road segments validate our vector, DEM, and 3-D model data for those areas while inconsistent segments point out errors. We further show that a search for descriptors that are consistent with visible road segments in the neighborhood of a misaligned road yields the desired road alignment that is consistent with pixels in the image.
* In Proceedings of 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS'08)
EigenFairing: 3D Model Fairing using Image Coherence
Jun 10, 2022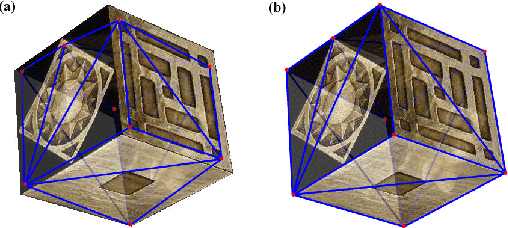
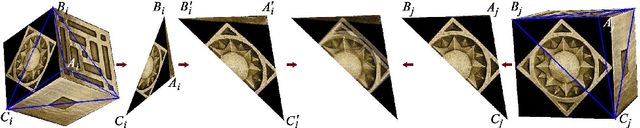

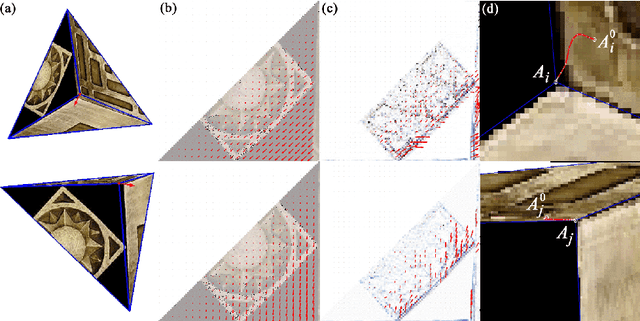
A surface is often modeled as a triangulated mesh of 3D points and textures associated with faces of the mesh. The 3D points could be either sampled from range data or derived from a set of images using a stereo or Structure-from-Motion algorithm. When the points do not lie at critical points of maximum curvature or discontinuities of the real surface, faces of the mesh do not lie close to the modeled surface. This results in textural artifacts, and the model is not perfectly coherent with a set of actual images -- the ones that are used to texture-map its mesh. This paper presents a technique for perfecting the 3D surface model by repositioning its vertices so that it is coherent with a set of observed images of the object. The textural artifacts and incoherence with images are due to the non-planarity of a surface patch being approximated by a planar face, as observed from multiple viewpoints. Image areas from the viewpoints are used to represent texture for the patch in Eigenspace. The Eigenspace representation captures variations of texture, which we seek to minimize. A coherence measure based on the difference between the face textures reconstructed from Eigenspace and the actual images is used to reposition the vertices so that the model is improved or faired. We refer to this technique of model refinement as EigenFairing, by which the model is faired, both geometrically and texturally, to better approximate the real surface.
* British Machine Vision Conference, BMVC 2004, Kingston, UK, September 7-9, 2004