 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity of Stability: Theoretical & Empirical Analysis of Replicability for Adaptive Data Selection in Transfer Learning
Aug 06, 2025The widespread adoption of transfer learning has revolutionized machine learning by enabling efficient adaptation of pre-trained models to new domains. However, the reliability of these adaptations remains poorly understood, particularly when using adaptive data selection strategies that dynamically prioritize training examples. We present a comprehensive theoretical and empirical analysis of replicability in transfer learning, introducing a mathematical framework that quantifies the fundamental trade-off between adaptation effectiveness and result consistency. Our key contribution is the formalization of selection sensitivity ($\Delta_Q$), a measure that captures how adaptive selection strategies respond to perturbations in training data. We prove that replicability failure probability: the likelihood that two independent training runs produce models differing in performance by more than a threshold, increases quadratically with selection sensitivity while decreasing exponentially with sample size. Through extensive experiments on the MultiNLI corpus using six adaptive selection strategies - ranging from uniform sampling to gradient-based selection - we demonstrate that this theoretical relationship holds precisely in practice. Our results reveal that highly adaptive strategies like gradient-based and curriculum learning achieve superior task performance but suffer from high replicability failure rates, while less adaptive approaches maintain failure rates below 7%. Crucially, we show that source domain pretraining provides a powerful mitigation mechanism, reducing failure rates by up to 30% while preserving performance gains. These findings establish principled guidelines for practitioners to navigate the performance-replicability trade-off and highlight the need for replicability-aware design in modern transfer learning systems.
SEMI-FND: Stacked Ensemble Based Multimodal Inference For Faster Fake News Detection
May 17, 2022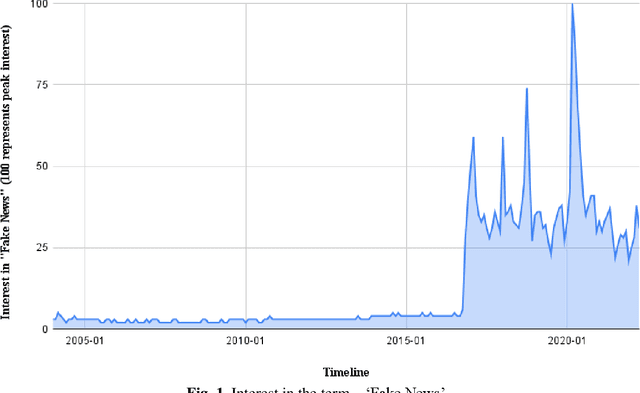

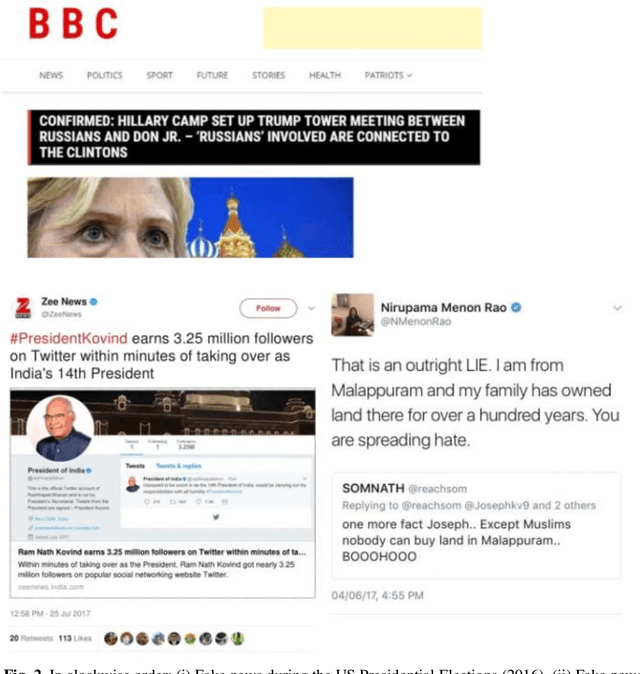
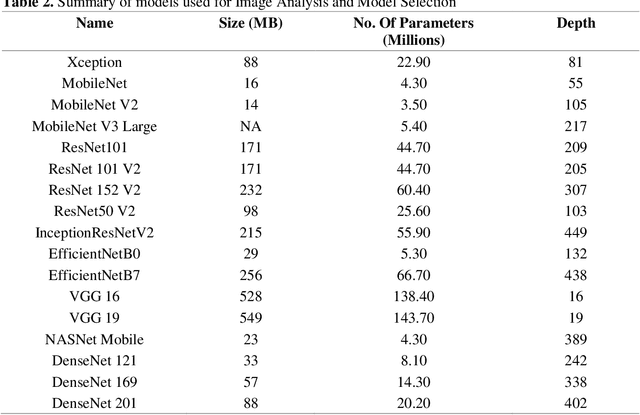
Fake News Detection (FND) is an essential field in natural language processing that aims to identify and check the truthfulness of major claims in a news article to decide the news veracity. FND finds its uses in preventing social, political and national damage caused due to misrepresentation of facts which may harm a certain section of society. Further, with the explosive rise in fake news dissemination over social media, including images and text, it has become imperative to identify fake news faster and more accurately. To solve this problem, this work investigates a novel multimodal stacked ensemble-based approach (SEMIFND) to fake news detection. Focus is also kept on ensuring faster performance with fewer parameters. Moreover, to improve multimodal performance, a deep unimodal analysis is done on the image modality to identify NasNet Mobile as the most appropriate model for the task. For text, an ensemble of BERT and ELECTRA is used. The approach was evaluated on two datasets: Twitter MediaEval and Weibo Corpus. The suggested framework offered accuracies of 85.80% and 86.83% on the Twitter and Weibo datasets respectively. These reported metrics are found to be superior when compared to similar recent works. Further, we also report a reduction in the number of parameters used in training when compared to recent relevant works. SEMI-FND offers an overall parameter reduction of at least 20% with unimodal parametric reduction on text being 60%. Therefore, based on the investigations presented, it is concluded that the application of a stacked ensembling significantly improves FND over other approaches while also improving speed.