 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM: GPU-Variability-Aware Expert to GPU Mapping for MoE Systems
May 19, 2026Mixture-of-Expert (MoE) models enable efficient inference by employing smaller experts and activating only a subset of them per token. MoE serving engines distribute experts across multiple GPUs and route tokens to appropriate GPUs at inference time based on experts activated. They process tokens in lock-step fashion, where tokens within a batch must finish processing before proceeding to the next layer. This synchronization barrier acts as a critical bottleneck because the performance of MoE models is limited by the straggler GPU that finishes last. Stragglers emerge when too many heavily used experts are placed on the same GPU or the slowest GPU. While prior works place experts that balance token loads across GPUs, they all overlook GPU variability and often place highly used experts on the slowest GPUs. We propose GEM, GPU-variability-aware Expert Mapping, a framework for GPU variability-aware expert to GPU mapping for MoE models. GEM exploits two insights. First, we must place experts such that each GPU receives non-uniform token loads based on their variability and they all finish processing a layer at about the same time. Our studies show that there are two types of experts: consistent that are used most of the time and temporal that are often used together for the remaining time. Our second insight is that we must place simultaneously used consistent and temporal experts on different GPUs and avoid placing them on slower GPUs to reduce slowdown. GEM gathers the variability profile of GPUs for each model and task and uses the token load distributions per task to map experts to GPUs. Our experiments show that GEM improves end-to-end latency by 7.9% on average and by up to 16.5% compared to the baseline.
Test-Time Speculation
May 10, 2026Speculative decoding accelerates LLM inference by using a fast draft model to generate tokens and a more accurate target model to verify them. Its performance depends on the $\textit{acceptance length}$, or number of draft tokens accepted by the target. Our studies show that the acceptance length of even state-of-the-art speculators, like DFlash, EAGLE-3 and PARD degrade with generation length, reaching values close to 1 (i.e. no speedup) within just a few thousand output tokens, making speculators ineffective for long-response tasks. Acceptance lengths decline because most speculators are trained offline on short sequences, but are forced to match the target model on much longer outputs at inference, well beyond their training distribution. To address this issue, we propose $\textit{Test-Time Speculation (TTS)}$, an online distillation approach that continuously adapts the speculator at test-time. TTS leverages the key insight that the token verification step already invokes the target model for each draft token, providing the training signal needed to adapt the draft at no additional cost. Treating the draft as the student and the target as a teacher, TTS adjusts the draft over several speculation rounds, with each update improving the draft's accuracy as generation proceeds. Our results across multiple models from the Qwen-3, Qwen-3.5, and Llama3.1 families show that TTS improves acceptance lengths over state-of-the-art speculators by up to $72\%$ and $41\%$ on average, with the benefits scaling with increased generation lengths.
Are LLMs Good For Quantum Software, Architecture, and System Design?
Mar 27, 2026Quantum computers promise massive computational speedup for problems in many critical domains, such as physics, chemistry, cryptanalysis, healthcare, etc. However, despite decades of research, they remain far from entering an era of utility. The lack of mature software, architecture, and systems solutions capable of translating quantum-mechanical properties of algorithms into physical state transformations on qubit devices remains a key factor underlying the slow pace of technological progress. The problem worsens due to significant reliance on domain-specific expertise, especially for software developers, computer architects, and systems engineers. To address these limitations and accelerate large-scale high-performance quantum system design, we ask: Can large language models (LLMs) help with solving quantum software, architecture, and systems problems? In this work, we present a case study assessing the performance of LLMs on quantum system reasoning tasks. We evaluate nine frontier LLMs and compare their performance to graduate UT Austin students on a set of quantum computing problems. Finally, we recommend several directions along which research and engineering development efforts must be pursued.
HELIOS: Adaptive Model And Early-Exit Selection for Efficient LLM Inference Serving
Apr 14, 2025



Deploying large language models (LLMs) presents critical challenges due to the inherent trade-offs associated with key performance metrics, such as latency, accuracy, and throughput. Typically, gains in one metric is accompanied with degradation in others. Early-Exit LLMs (EE-LLMs) efficiently navigate this trade-off space by skipping some of the later model layers when it confidently finds an output token early, thus reducing latency without impacting accuracy. However, as the early exits taken depend on the task and are unknown apriori to request processing, EE-LLMs conservatively load the entire model, limiting resource savings and throughput. Also, current frameworks statically select a model for a user task, limiting our ability to adapt to changing nature of the input queries. We propose HELIOS to address these challenges. First, HELIOS shortlists a set of candidate LLMs, evaluates them using a subset of prompts, gathering telemetry data in real-time. Second, HELIOS uses the early exit data from these evaluations to greedily load the selected model only up to a limited number of layers. This approach yields memory savings which enables us to process more requests at the same time, thereby improving throughput. Third, HELIOS monitors and periodically reassesses the performance of the candidate LLMs and if needed, switches to another model that can service incoming queries more efficiently (such as using fewer layers without lowering accuracy). Our evaluations show that HELIOS achieves 1.48$\times$ throughput, 1.10$\times$ energy-efficiency, 1.39$\times$ lower response time, and 3.7$\times$ improvements in inference batch sizes compared to the baseline, when optimizing for the respective service level objectives.
Dialogue Without Limits: Constant-Sized KV Caches for Extended Responses in LLMs
Mar 02, 2025Autoregressive Transformers rely on Key-Value (KV) caching to accelerate inference. However, the linear growth of the KV cache with context length leads to excessive memory consumption and bandwidth constraints. This bottleneck is particularly problematic in real-time applications -- such as chatbots and interactive assistants -- where low latency and high memory efficiency are critical. Existing methods drop distant tokens or compress states in a lossy manner, sacrificing accuracy by discarding vital context or introducing bias. We propose MorphKV, an inference-time technique that maintains a constant-sized KV cache while preserving accuracy. MorphKV balances long-range dependencies and local coherence during text generation. It eliminates early-token bias while retaining high-fidelity context by adaptively ranking tokens through correlation-aware selection. Unlike heuristic retention or lossy compression, MorphKV iteratively refines the KV cache via lightweight updates guided by attention patterns of recent tokens. This approach captures inter-token correlation with greater accuracy, crucial for tasks like content creation and code generation. Our studies on long-response tasks show 52.9$\%$ memory savings and 18.2$\%$ higher accuracy on average compared to state-of-the-art prior works, enabling efficient real-world deployment.
Élivágar: Efficient Quantum Circuit Search for Classification
Jan 17, 2024



Designing performant and noise-robust circuits for Quantum Machine Learning (QML) is challenging -- the design space scales exponentially with circuit size, and there are few well-supported guiding principles for QML circuit design. Although recent Quantum Circuit Search (QCS) methods attempt to search for performant QML circuits that are also robust to hardware noise, they directly adopt designs from classical Neural Architecture Search (NAS) that are misaligned with the unique constraints of quantum hardware, resulting in high search overheads and severe performance bottlenecks. We present \'Eliv\'agar, a novel resource-efficient, noise-guided QCS framework. \'Eliv\'agar innovates in all three major aspects of QCS -- search space, search algorithm and candidate evaluation strategy -- to address the design flaws in current classically-inspired QCS methods. \'Eliv\'agar achieves hardware-efficiency and avoids an expensive circuit-mapping co-search via noise- and device topology-aware candidate generation. By introducing two cheap-to-compute predictors, Clifford noise resilience and Representational capacity, \'Eliv\'agar decouples the evaluation of noise robustness and performance, enabling early rejection of low-fidelity circuits and reducing circuit evaluation costs. Due to its resource-efficiency, \'Eliv\'agar can further search for data embeddings, significantly improving performance. Based on a comprehensive evaluation of \'Eliv\'agar on 12 real quantum devices and 9 QML applications, \'Eliv\'agar achieves 5.3% higher accuracy and a 271$\times$ speedup compared to state-of-the-art QCS methods.
FrozenQubits: Boosting Fidelity of QAOA by Skipping Hotspot Nodes
Oct 31, 2022



Quantum Approximate Optimization Algorithm (QAOA) is one of the leading candidates for demonstrating the quantum advantage using near-term quantum computers. Unfortunately, high device error rates limit us from reliably running QAOA circuits for problems with more than a few qubits. In QAOA, the problem graph is translated into a quantum circuit such that every edge corresponds to two 2-qubit CNOT operations in each layer of the circuit. As CNOTs are extremely error-prone, the fidelity of QAOA circuits is dictated by the number of edges in the problem graph. We observe that majority of graphs corresponding to real-world applications follow the ``power-law`` distribution, where some hotspot nodes have significantly higher number of connections. We leverage this insight and propose ``FrozenQubits`` that freezes the hotspot nodes or qubits and intelligently partitions the state-space of the given problem into several smaller sub-spaces which are then solved independently. The corresponding QAOA sub-circuits are significantly less vulnerable to gate and decoherence errors due to the reduced number of CNOT operations in each sub-circuit. Unlike prior circuit-cutting approaches, FrozenQubits does not require any exponentially complex post-processing step. Our evaluations with 5,300 QAOA circuits on eight different quantum computers from IBM shows that FrozenQubits can improve the quality of solutions by 8.73x on average (and by up to 57x), albeit utilizing 2x more quantum resources.
Multilevel Threshold Based Gray Scale Image Segmentation using Cuckoo Search
Jul 01, 2013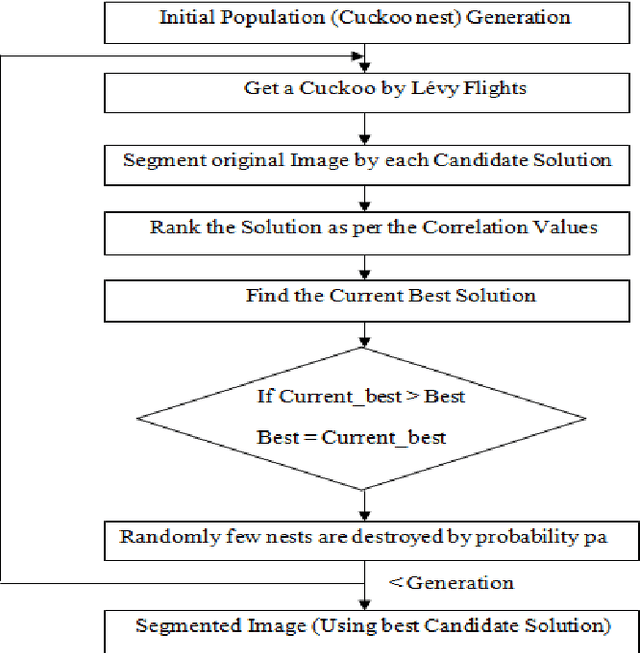
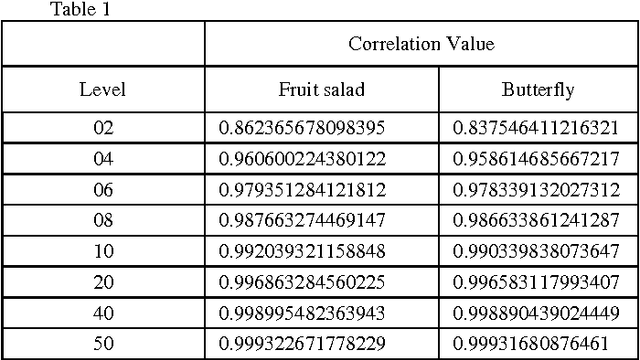


Image Segmentation is a technique of partitioning the original image into some distinct classes. Many possible solutions may be available for segmenting an image into a certain number of classes, each one having different quality of segmentation. In our proposed method, multilevel thresholding technique has been used for image segmentation. A new approach of Cuckoo Search (CS) is used for selection of optimal threshold value. In other words, the algorithm is used to achieve the best solution from the initial random threshold values or solutions and to evaluate the quality of a solution correlation function is used. Finally, MSE and PSNR are measured to understand the segmentation quality.
Embedding of Blink Frequency in Electrooculography Signal using Difference Expansion based Reversible Watermarking Technique
Mar 09, 2013

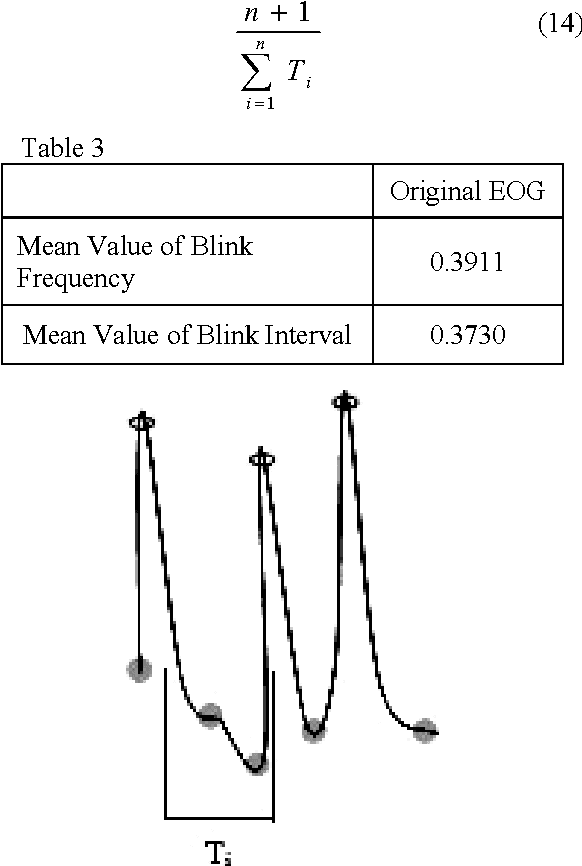
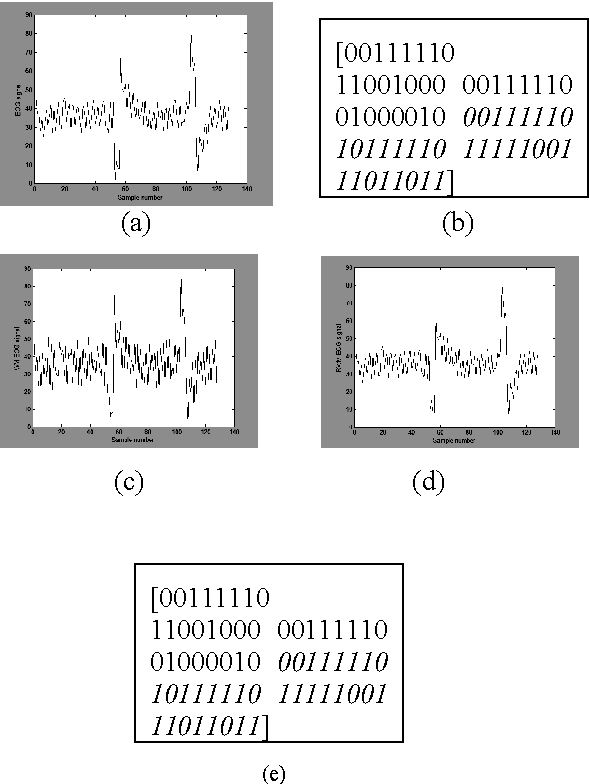
In the past few years, like other fields, rapid expansion of digitization and globalization has influenced the medical field as well. For progress of diagnostic results most of the reputed hospitals and diagnostic centres all over the world have started exchanging medical information. In this proposed method, the calculated diagnostic parametric values of the original Electrooculography (EOG) signal are embedded as a watermark by using Difference Expansion (DE) algorithm based reversible watermarking technique. The extracted watermark provides the required parametric values at the recipient end without any post computation of the recovered EOG signal. By computing the parametric values from the recovered signal, the integrity of the extracted watermark can be validated. The time domain features of EOG signal are calculated for the generation of watermark. In the current work, various features are studied and two major features related to blink frequency are used to generate the watermark. The high Signal to Noise Ratio (SNR) and the Bit Error Rate (BER) claim the robustness of the proposed method.
* 6 Pages, 3 Figures, 4 Tables