 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePo-chun Hsu
Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
Oct 25, 2019
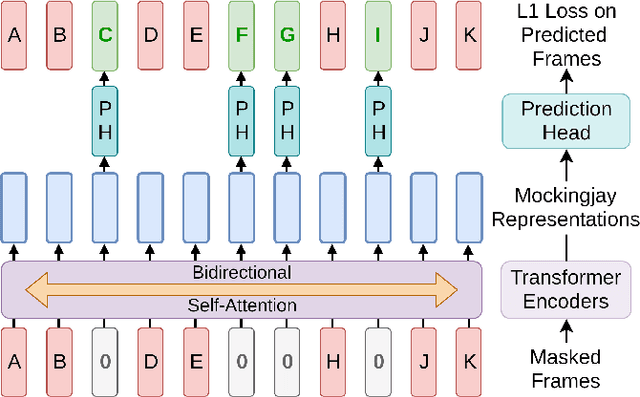
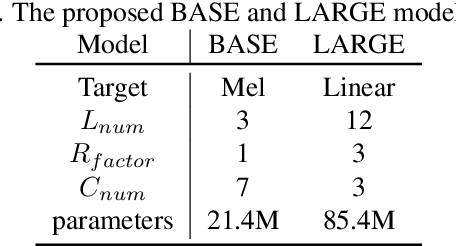
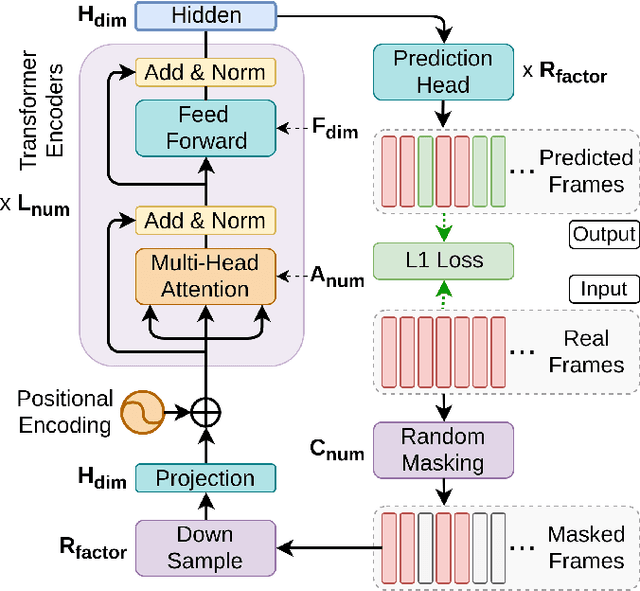
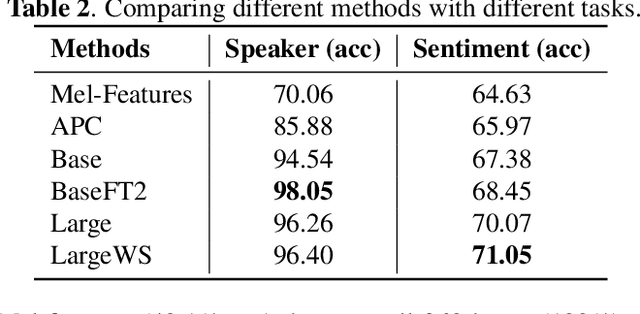
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts. The Mockingjay representation improves performance for a wide range of downstream tasks, including phoneme classification, speaker recognition, and sentiment classification on spoken content, while outperforming other approaches. Mockingjay is empirically powerful and can be fine-tuned with downstream models, with only 2 epochs we further improve performance dramatically. In a low resource setting with only 0.1% of labeled data, we outperform the result of Mel-features that uses all 100% labeled data.
Unsupervised End-to-End Learning of Discrete Linguistic Units for Voice Conversion
May 28, 2019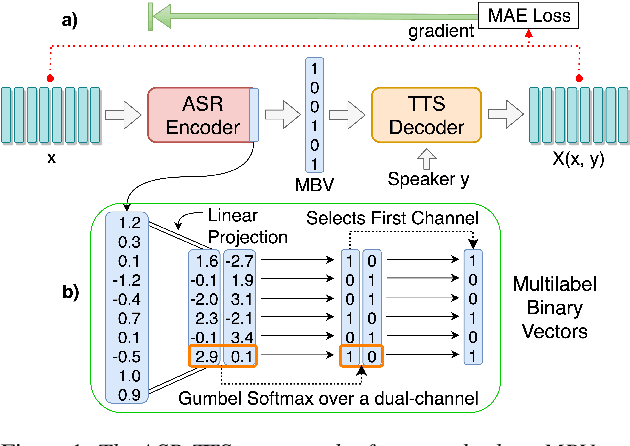
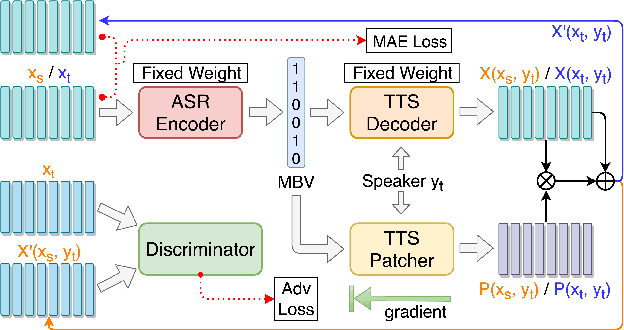
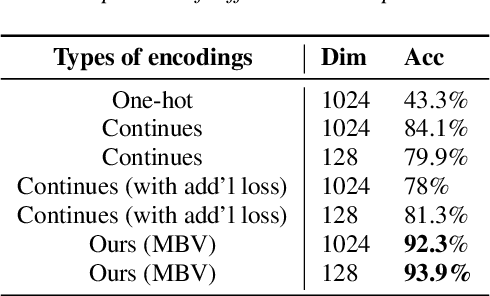
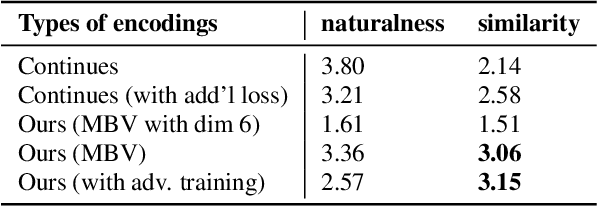
We present an unsupervised end-to-end training scheme where we discover discrete subword units from speech without using any labels. The discrete subword units are learned under an ASR-TTS autoencoder reconstruction setting, where an ASR-Encoder is trained to discover a set of common linguistic units given a variety of speakers, and a TTS-Decoder trained to project the discovered units back to the designated speech. We propose a discrete encoding method, Multilabel-Binary Vectors (MBV), to make the ASR-TTS autoencoder differentiable. We found that the proposed encoding method offers automatic extraction of speech content from speaker style, and is sufficient to cover full linguistic content in a given language. Therefore, the TTS-Decoder can synthesize speech with the same content as the input of ASR-Encoder but with different speaker characteristics, which achieves voice conversion (VC). We further improve the quality of VC using adversarial training, where we train a TTS-Patcher that augments the output of TTS-Decoder. Objective and subjective evaluations show that the proposed approach offers strong VC results as it eliminates speaker identity while preserving content within speech. In the ZeroSpeech 2019 Challenge, we achieved outstanding performance in terms of low bitrate.