 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall-Variance Asymptotics for Nonparametric Bayesian Overlapping Stochastic Blockmodels
Jul 10, 2018
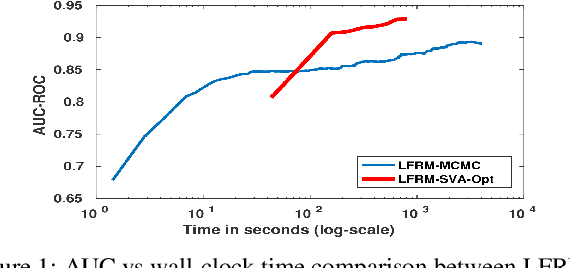
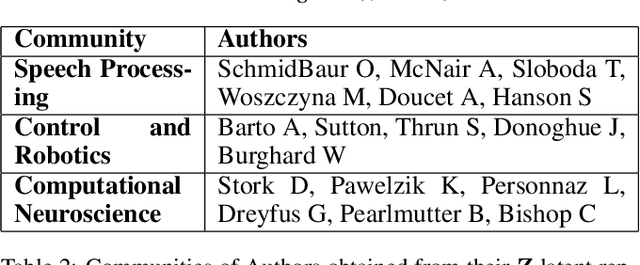
The latent feature relational model (LFRM) is a generative model for graph-structured data to learn a binary vector representation for each node in the graph. The binary vector denotes the node's membership in one or more communities. At its core, the LFRM miller2009nonparametric is an overlapping stochastic blockmodel, which defines the link probability between any pair of nodes as a bilinear function of their community membership vectors. Moreover, using a nonparametric Bayesian prior (Indian Buffet Process) enables learning the number of communities automatically from the data. However, despite its appealing properties, inference in LFRM remains a challenge and is typically done via MCMC methods. This can be slow and may take a long time to converge. In this work, we develop a small-variance asymptotics based framework for the non-parametric Bayesian LFRM. This leads to an objective function that retains the nonparametric Bayesian flavor of LFRM, while enabling us to design deterministic inference algorithms for this model, that are easy to implement (using generic or specialized optimization routines) and are fast in practice. Our results on several benchmark datasets demonstrate that our algorithm is competitive to methods such as MCMC, while being much faster.
Generalized Zero-Shot Learning via Synthesized Examples
Jun 12, 2018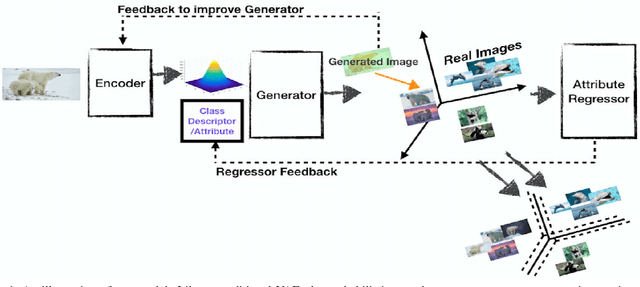
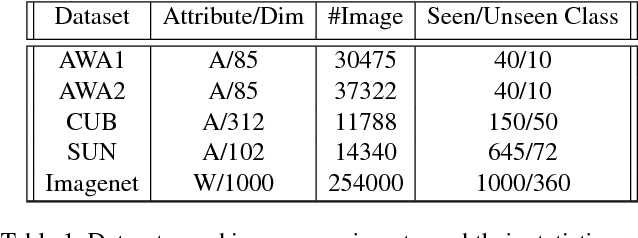
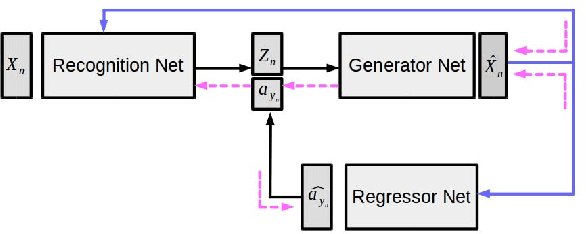
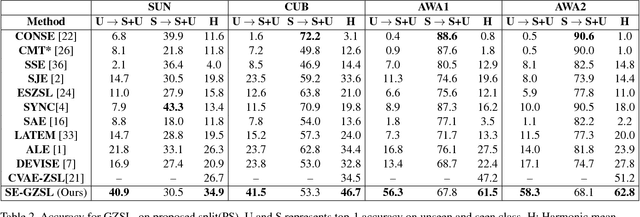
We present a generative framework for generalized zero-shot learning where the training and test classes are not necessarily disjoint. Built upon a variational autoencoder based architecture, consisting of a probabilistic encoder and a probabilistic conditional decoder, our model can generate novel exemplars from seen/unseen classes, given their respective class attributes. These exemplars can subsequently be used to train any off-the-shelf classification model. One of the key aspects of our encoder-decoder architecture is a feedback-driven mechanism in which a discriminator (a multivariate regressor) learns to map the generated exemplars to the corresponding class attribute vectors, leading to an improved generator. Our model's ability to generate and leverage examples from unseen classes to train the classification model naturally helps to mitigate the bias towards predicting seen classes in generalized zero-shot learning settings. Through a comprehensive set of experiments, we show that our model outperforms several state-of-the-art methods, on several benchmark datasets, for both standard as well as generalized zero-shot learning.
A Generative Approach to Zero-Shot and Few-Shot Action Recognition
Jan 27, 2018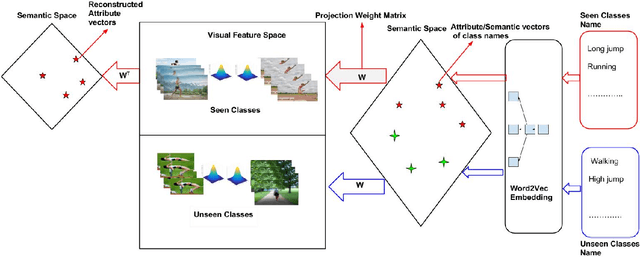
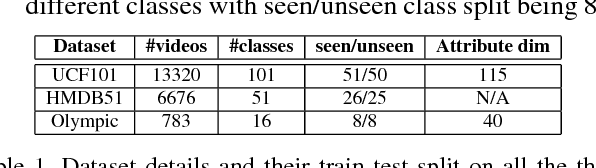
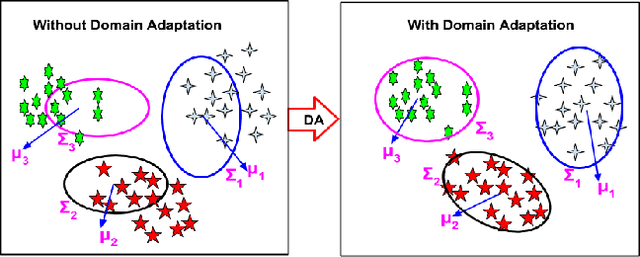
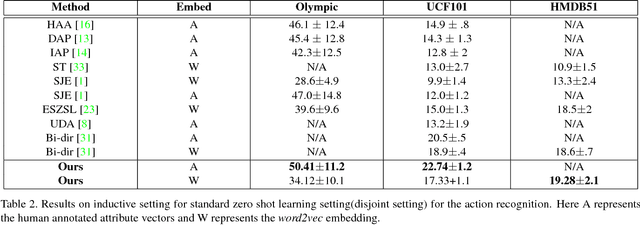
We present a generative framework for zero-shot action recognition where some of the possible action classes do not occur in the training data. Our approach is based on modeling each action class using a probability distribution whose parameters are functions of the attribute vector representing that action class. In particular, we assume that the distribution parameters for any action class in the visual space can be expressed as a linear combination of a set of basis vectors where the combination weights are given by the attributes of the action class. These basis vectors can be learned solely using labeled data from the known (i.e., previously seen) action classes, and can then be used to predict the parameters of the probability distributions of unseen action classes. We consider two settings: (1) Inductive setting, where we use only the labeled examples of the seen action classes to predict the unseen action class parameters; and (2) Transductive setting which further leverages unlabeled data from the unseen action classes. Our framework also naturally extends to few-shot action recognition where a few labeled examples from unseen classes are available. Our experiments on benchmark datasets (UCF101, HMDB51 and Olympic) show significant performance improvements as compared to various baselines, in both standard zero-shot (disjoint seen and unseen classes) and generalized zero-shot learning settings.
A Simple Exponential Family Framework for Zero-Shot Learning
Jan 25, 2018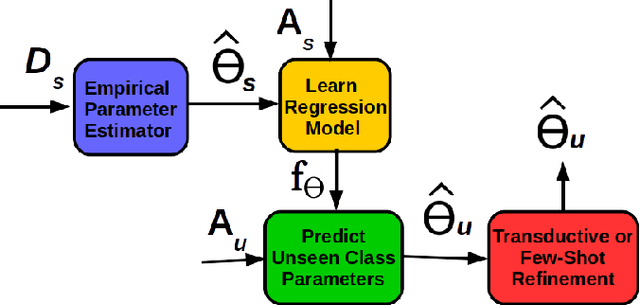
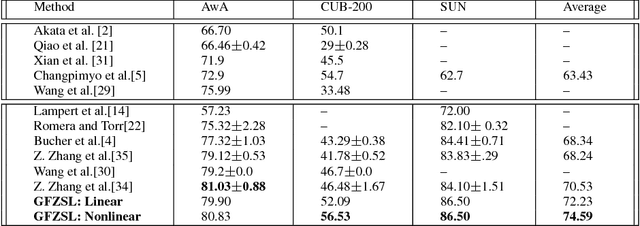
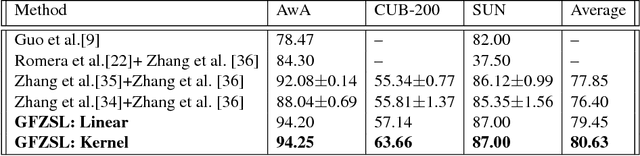
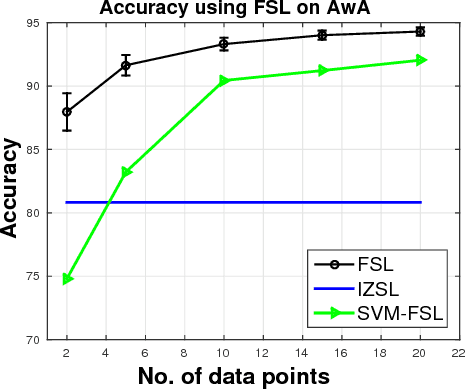
We present a simple generative framework for learning to predict previously unseen classes, based on estimating class-attribute-gated class-conditional distributions. We model each class-conditional distribution as an exponential family distribution and the parameters of the distribution of each seen/unseen class are defined as functions of the respective observed class attributes. These functions can be learned using only the seen class data and can be used to predict the parameters of the class-conditional distribution of each unseen class. Unlike most existing methods for zero-shot learning that represent classes as fixed embeddings in some vector space, our generative model naturally represents each class as a probability distribution. It is simple to implement and also allows leveraging additional unlabeled data from unseen classes to improve the estimates of their class-conditional distributions using transductive/semi-supervised learning. Moreover, it extends seamlessly to few-shot learning by easily updating these distributions when provided with a small number of additional labelled examples from unseen classes. Through a comprehensive set of experiments on several benchmark data sets, we demonstrate the efficacy of our framework.
Zero-Shot Learning via Class-Conditioned Deep Generative Models
Nov 19, 2017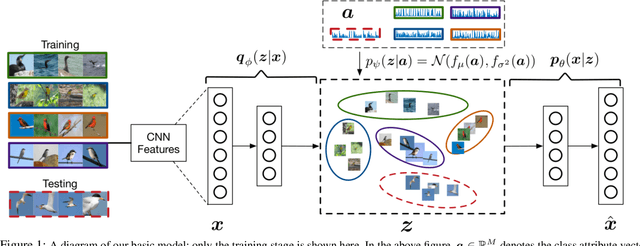
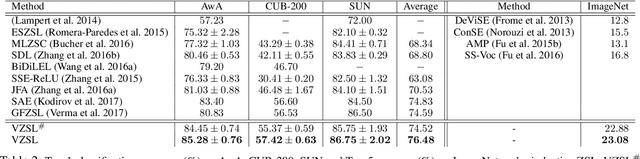
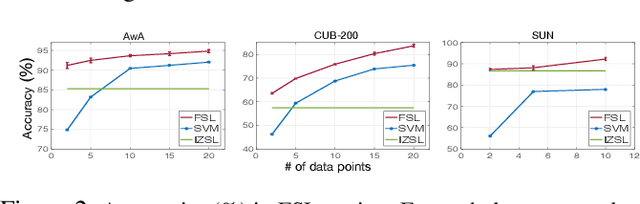
We present a deep generative model for learning to predict classes not seen at training time. Unlike most existing methods for this problem, that represent each class as a point (via a semantic embedding), we represent each seen/unseen class using a class-specific latent-space distribution, conditioned on class attributes. We use these latent-space distributions as a prior for a supervised variational autoencoder (VAE), which also facilitates learning highly discriminative feature representations for the inputs. The entire framework is learned end-to-end using only the seen-class training data. The model infers corresponding attributes of a test image by maximizing the VAE lower bound; the inferred attributes may be linked to labels not seen when training. We further extend our model to a (1) semi-supervised/transductive setting by leveraging unlabeled unseen-class data via an unsupervised learning module, and (2) few-shot learning where we also have a small number of labeled inputs from the unseen classes. We compare our model with several state-of-the-art methods through a comprehensive set of experiments on a variety of benchmark data sets.
Leveraging Distributional Semantics for Multi-Label Learning
Nov 10, 2017

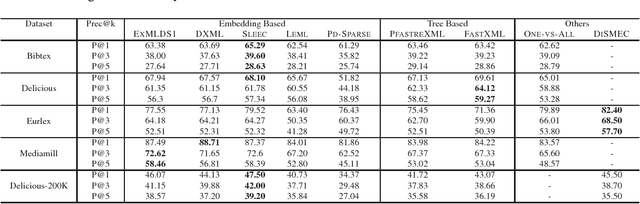
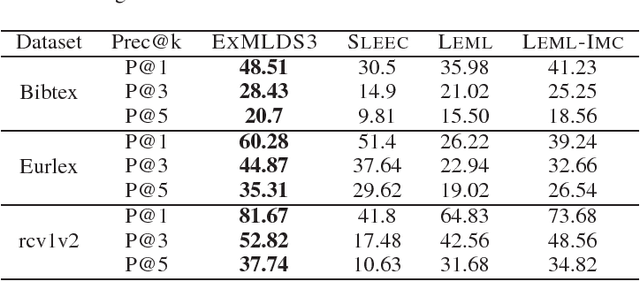
We present a novel and scalable label embedding framework for large-scale multi-label learning a.k.a ExMLDS (Extreme Multi-Label Learning using Distributional Semantics). Our approach draws inspiration from ideas rooted in distributional semantics, specifically the Skip Gram Negative Sampling (SGNS) approach, widely used to learn word embeddings for natural language processing tasks. Learning such embeddings can be reduced to a certain matrix factorization. Our approach is novel in that it highlights interesting connections between label embedding methods used for multi-label learning and paragraph/document embedding methods commonly used for learning representations of text data. The framework can also be easily extended to incorporate auxiliary information such as label-label correlations; this is crucial especially when there are a lot of missing labels in the training data. We demonstrate the effectiveness of our approach through an extensive set of experiments on a variety of benchmark datasets, and show that the proposed learning methods perform favorably compared to several baselines and state-of-the-art methods for large-scale multi-label learning. To facilitate end-to-end learning, we develop a joint learning algorithm that can learn the embeddings as well as a regression model that predicts these embeddings given input features, via efficient gradient-based methods.
A Deep Generative Framework for Paraphrase Generation
Sep 15, 2017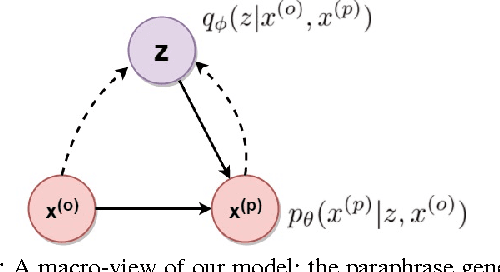
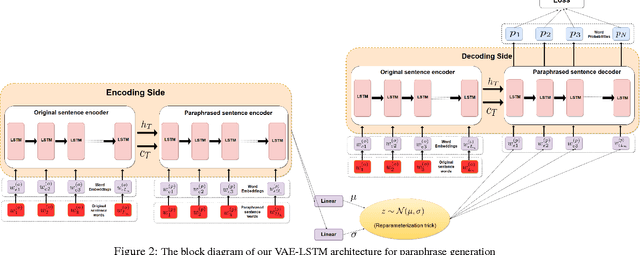
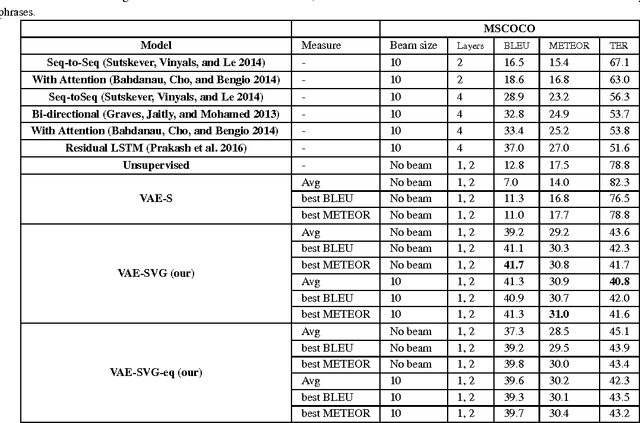
Paraphrase generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. In this paper, we address the problem of generating paraphrases automatically. Our proposed method is based on a combination of deep generative models (VAE) with sequence-to-sequence models (LSTM) to generate paraphrases, given an input sentence. Traditional VAEs when combined with recurrent neural networks can generate free text but they are not suitable for paraphrase generation for a given sentence. We address this problem by conditioning the both, encoder and decoder sides of VAE, on the original sentence, so that it can generate the given sentence's paraphrases. Unlike most existing models, our model is simple, modular and can generate multiple paraphrases, for a given sentence. Quantitative evaluation of the proposed method on a benchmark paraphrase dataset demonstrates its efficacy, and its performance improvement over the state-of-the-art methods by a significant margin, whereas qualitative human evaluation indicate that the generated paraphrases are well-formed, grammatically correct, and are relevant to the input sentence. Furthermore, we evaluate our method on a newly released question paraphrase dataset, and establish a new baseline for future research.
Deep Generative Models for Relational Data with Side Information
Jun 16, 2017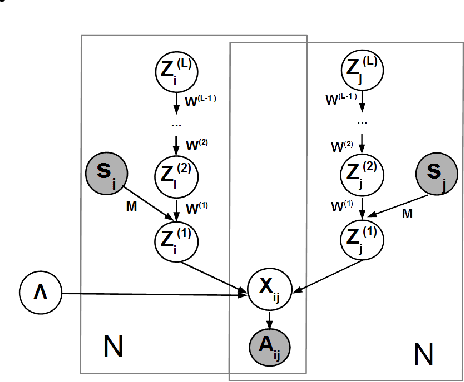
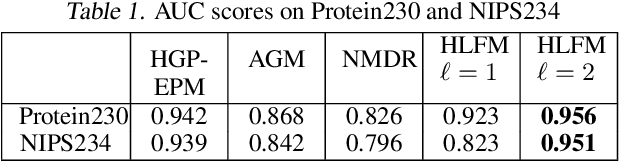
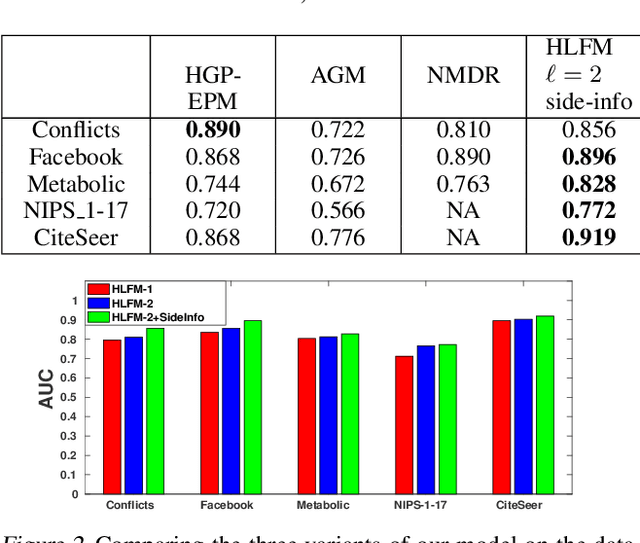
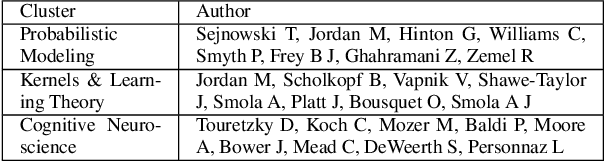
We present a probabilistic framework for overlapping community discovery and link prediction for relational data, given as a graph. The proposed framework has: (1) a deep architecture which enables us to infer multiple layers of latent features/communities for each node, providing superior link prediction performance on more complex networks and better interpretability of the latent features; and (2) a regression model which allows directly conditioning the node latent features on the side information available in form of node attributes. Our framework handles both (1) and (2) via a clean, unified model, which enjoys full local conjugacy via data augmentation, and facilitates efficient inference via closed form Gibbs sampling. Moreover, inference cost scales in the number of edges which is attractive for massive but sparse networks. Our framework is also easily extendable to model weighted networks with count-valued edges. We compare with various state-of-the-art methods and report results, both quantitative and qualitative, on several benchmark data sets.
Earliness-Aware Deep Convolutional Networks for Early Time Series Classification
Nov 14, 2016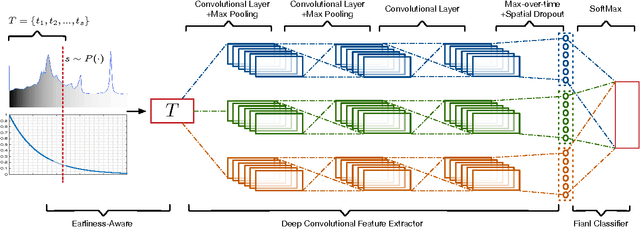
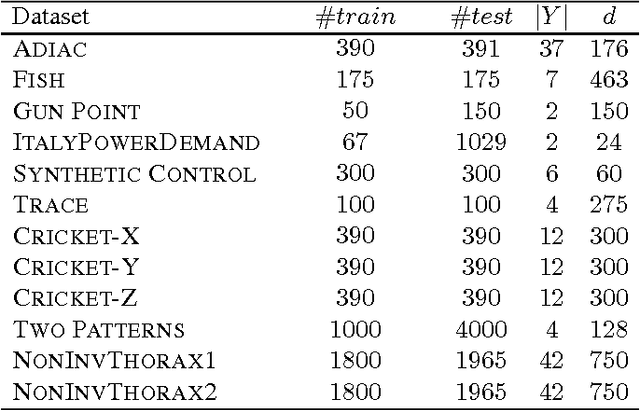
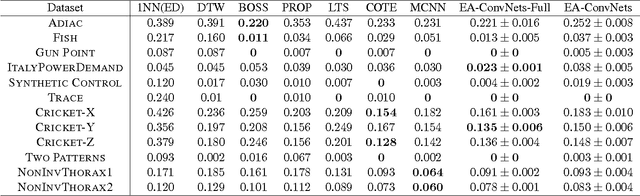
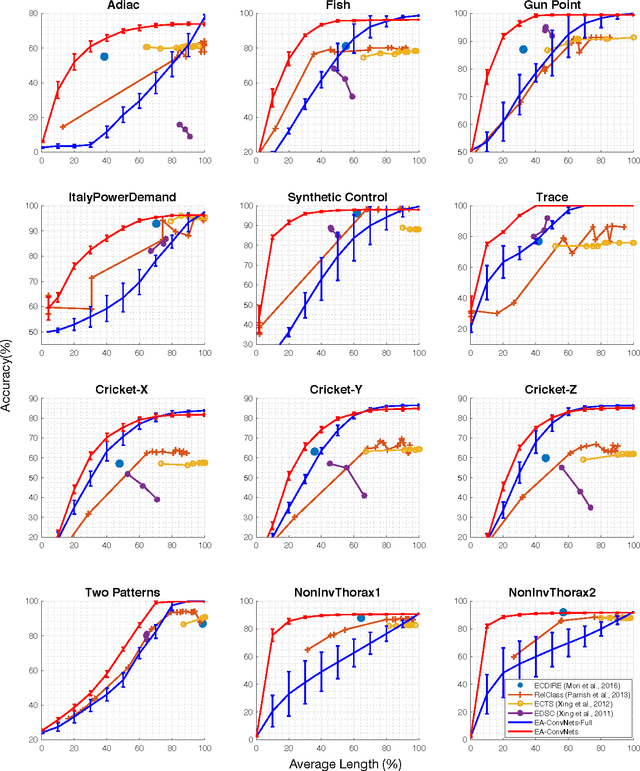
We present Earliness-Aware Deep Convolutional Networks (EA-ConvNets), an end-to-end deep learning framework, for early classification of time series data. Unlike most existing methods for early classification of time series data, that are designed to solve this problem under the assumption of the availability of a good set of pre-defined (often hand-crafted) features, our framework can jointly perform feature learning (by learning a deep hierarchy of \emph{shapelets} capturing the salient characteristics in each time series), along with a dynamic truncation model to help our deep feature learning architecture focus on the early parts of each time series. Consequently, our framework is able to make highly reliable early predictions, outperforming various state-of-the-art methods for early time series classification, while also being competitive when compared to the state-of-the-art time series classification algorithms that work with \emph{fully observed} time series data. To the best of our knowledge, the proposed framework is the first to perform data-driven (deep) feature learning in the context of early classification of time series data. We perform a comprehensive set of experiments, on several benchmark data sets, which demonstrate that our method yields significantly better predictions than various state-of-the-art methods designed for early time series classification. In addition to obtaining high accuracies, our experiments also show that the learned deep shapelets based features are also highly interpretable and can help gain better understanding of the underlying characteristics of time series data.
Scalable Bayesian Non-Negative Tensor Factorization for Massive Count Data
Aug 18, 2015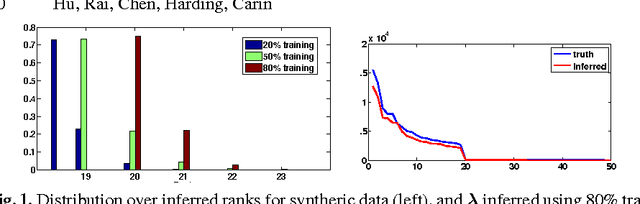
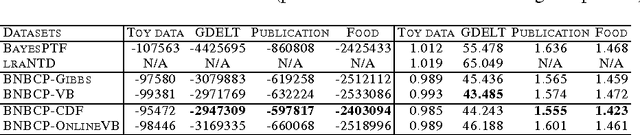
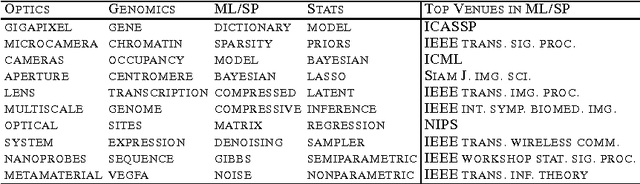

We present a Bayesian non-negative tensor factorization model for count-valued tensor data, and develop scalable inference algorithms (both batch and online) for dealing with massive tensors. Our generative model can handle overdispersed counts as well as infer the rank of the decomposition. Moreover, leveraging a reparameterization of the Poisson distribution as a multinomial facilitates conjugacy in the model and enables simple and efficient Gibbs sampling and variational Bayes (VB) inference updates, with a computational cost that only depends on the number of nonzeros in the tensor. The model also provides a nice interpretability for the factors; in our model, each factor corresponds to a "topic". We develop a set of online inference algorithms that allow further scaling up the model to massive tensors, for which batch inference methods may be infeasible. We apply our framework on diverse real-world applications, such as \emph{multiway} topic modeling on a scientific publications database, analyzing a political science data set, and analyzing a massive household transactions data set.