 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Retrieval-Augmented Text Generation with LLMs for Reading Content Recommendations
Jun 12, 2026This work presents the design, implementation, and evaluation of a system for generating personalized reading content using Large Language Models (LLMs) combined with Retrieval-Augmented Generation (RAG). The proposed architecture consists of four modules: Input, RAG, Generation, and Judging and enables users to specify both a question and a target reading content complexity. RAG is employed to retrieve relevant information from the Internet, enriching and grounding the content produced by three modern LLMs: Meta LLaMA 4 Scout, LLaMA 3.1 8B Instant, and Google Gemma2 9B. Reading materials are generated using three prompting strategies (Chain-of-Thought, zero-shot, and few-shot), and the LLM-as-a-Judge module automatically evaluates answer quality and alignment with the desired readability level. Experimental results show that RAG consistently improves system performance across all models and prompting techniques, increasing relevance and particularly groundedness by up to 26-35 percentage points. Overall, the findings demonstrate that the RAG-augmented architecture effectively produces reading content tailored to user queries and desired textual complexity.
Discovery of Crime Event Sequences with Constricted Spatio-Temporal Sequential Patterns
Dec 03, 2021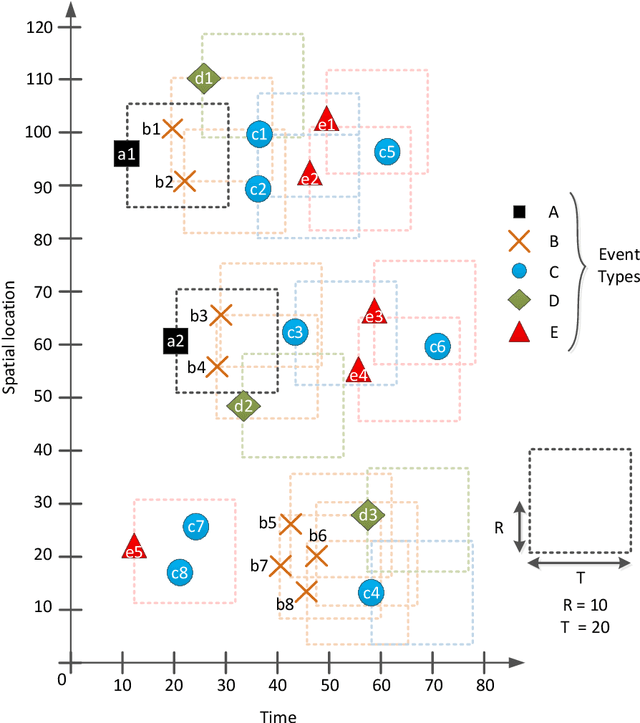
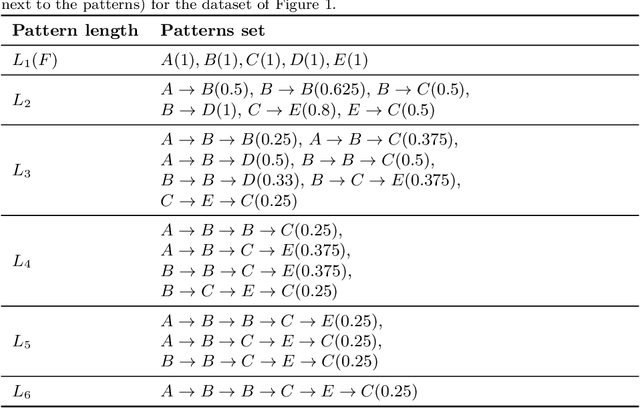
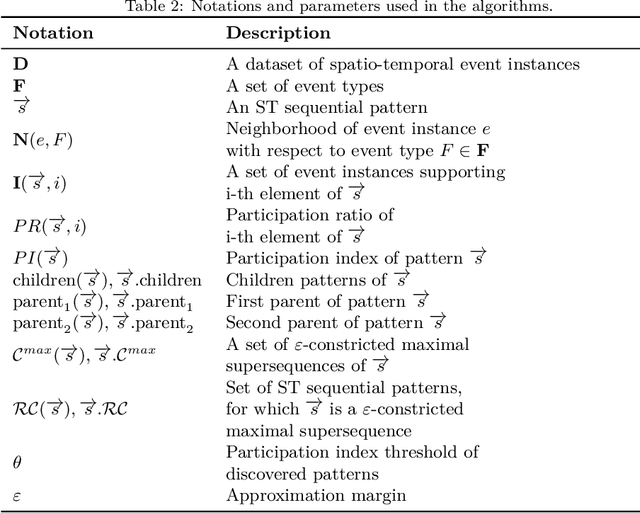
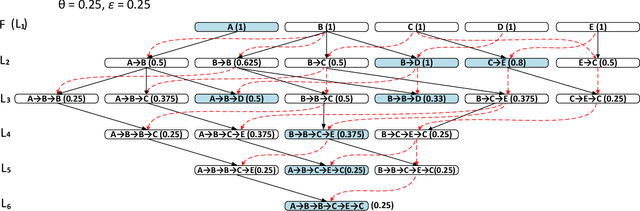
In this article, we introduce a novel type of spatio-temporal sequential patterns called Constricted Spatio-Temporal Sequential (CSTS) patterns and thoroughly analyze their properties. We demonstrate that the set of CSTS patterns is a concise representation of all spatio-temporal sequential patterns that can be discovered in a given dataset. To measure significance of the discovered CSTS patterns we adapt the participation index measure. We also provide CSTS-Miner: an algorithm that discovers all participation index strong CSTS patterns in event data. We experimentally evaluate the proposed algorithms using two crime-related datasets: Pittsburgh Police Incident Blotter Dataset and Boston Crime Incident Reports Dataset. In the experiments, the CSTS-Miner algorithm is compared with the other four state-of-the-art algorithms: STS-Miner, CSTPM, STBFM and CST-SPMiner. As the results of experiments suggest, the proposed algorithm discovers much fewer patterns than the other selected algorithms. Finally, we provide the examples of interesting crime-related patterns discovered by the proposed CSTS-Miner algorithm.
Unsupervised Anomaly Detection in Stream Data with Online Evolving Spiking Neural Networks
Dec 18, 2019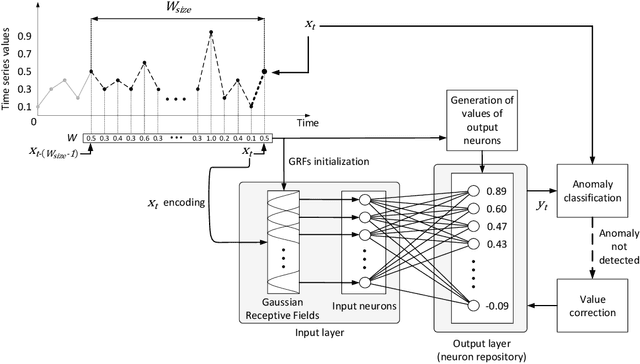
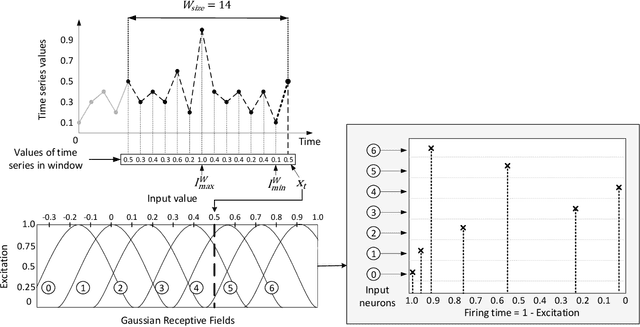
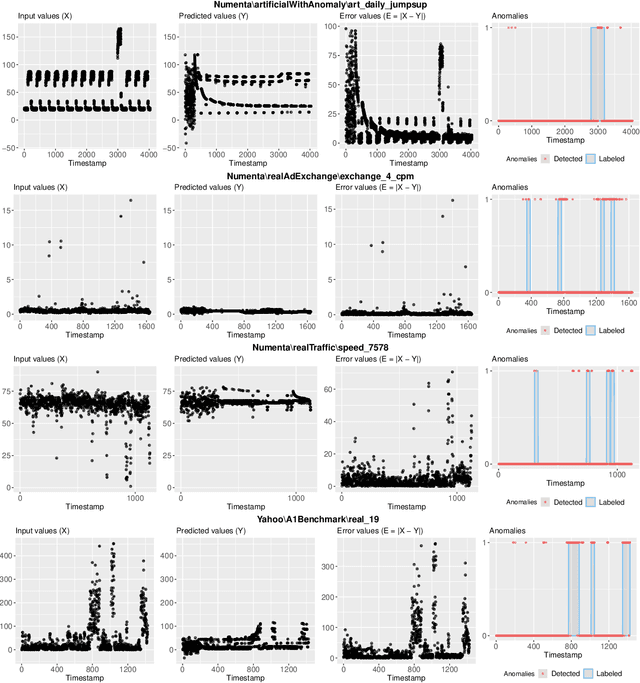

In this work, we propose a novel OeSNN-UAD (Online evolving Spiking Neural Networks for Unsupervised Anomaly Detection) approach for online anomaly detection in univariate time series data. Our approach is based on evolving Spiking Neural Networks (eSNN). Its distinctive feature is that the proposed eSNN architecture learns in the process of classifying input values to be anomalous or not. In fact, we offer an unsupervised learning method for eSNN, in which classification is carried out without earlier pre-training of the network with data with labeled anomalies. Unlike in a typical eSNN architecture, neurons in the output repository of our architecture are not divided into known a priori decision classes. Each output neuron is assigned its own output value, which is modified in the course of learning and classifying the incoming input values of time series data. To better adapt to the changing characteristic of the input data and to make their classification efficient, the number of output neurons is limited: the older neurons are replaced with new neurons whose output values and synapses' weights are adjusted according to the current input values of the time series. The proposed OeSNN-UAD approach was experimentally compared to the state-of-the-art unsupervised methods and algorithms for anomaly detection in stream data. The experiments were carried out on Numenta Anomaly Benchmark and Yahoo Anomaly Datasets. According to the results of these experiments, our approach significantly outperforms other solutions provided in the literature in the case of Numenta Anomaly Benchmark. Also in the case of real data files category of Yahoo Anomaly Benchmark, OeSNN-UAD outperforms other selected algorithms, whereas in the case of Yahoo Anomaly Benchmark synthetic data files, it provides competitive results to the results recently reported in the literature.