 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUDGEBERT: Assessing Legal Meaning Preservation Between Sentences
Aug 23, 2025Simplifying text while preserving its meaning is a complex yet essential task, especially in sensitive domain applications like legal texts. When applied to a specialized field, like the legal domain, preservation differs significantly from its role in regular texts. This paper introduces FrJUDGE, a new dataset to assess legal meaning preservation between two legal texts. It also introduces JUDGEBERT, a novel evaluation metric designed to assess legal meaning preservation in French legal text simplification. JUDGEBERT demonstrates a superior correlation with human judgment compared to existing metrics. It also passes two crucial sanity checks, while other metrics did not: For two identical sentences, it always returns a score of 100%; on the other hand, it returns 0% for two unrelated sentences. Our findings highlight its potential to transform legal NLP applications, ensuring accuracy and accessibility for text simplification for legal practitioners and lay users.
Generating Intelligible Plumitifs Descriptions: Use Case Application with Ethical Considerations
Nov 24, 2020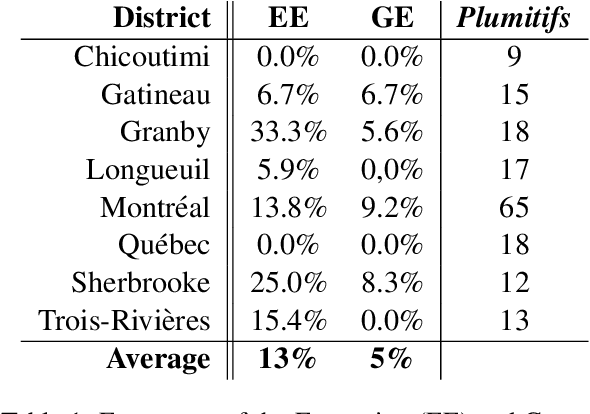
Plumitifs (dockets) were initially a tool for law clerks. Nowadays, they are used as summaries presenting all the steps of a judicial case. Information concerning parties' identity, jurisdiction in charge of administering the case, and some information relating to the nature and the course of the preceding are available through plumitifs. They are publicly accessible but barely understandable; they are written using abbreviations and referring to provisions from the Criminal Code of Canada, which makes them hard to reason about. In this paper, we propose a simple yet efficient multi-source language generation architecture that leverages both the plumitif and the Criminal Code's content to generate intelligible plumitifs descriptions. It goes without saying that ethical considerations rise with these sensitive documents made readable and available at scale, legitimate concerns that we address in this paper.