 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Generation of Microfluidic Netlists using Large Language Models
Feb 24, 2026Microfluidic devices have emerged as powerful tools in various laboratory applications, but the complexity of their design limits accessibility for many practitioners. While progress has been made in microfluidic design automation (MFDA), a practical and intuitive solution is still needed to connect microfluidic practitioners with MFDA techniques. This work introduces the first practical application of large language models (LLMs) in this context, providing a preliminary demonstration. Building on prior research in hardware description language (HDL) code generation with LLMs, we propose an initial methodology to convert natural language microfluidic device specifications into system-level structural Verilog netlists. We demonstrate the feasibility of our approach by generating structural netlists for practical benchmarks representative of typical microfluidic designs with correct functional flow and an average syntactical accuracy of 88%.
Nexus: A Lightweight and Scalable Multi-Agent Framework for Complex Tasks Automation
Feb 26, 2025Recent advancements in Large Language Models (LLMs) have substantially evolved Multi-Agent Systems (MASs) capabilities, enabling systems that not only automate tasks but also leverage near-human reasoning capabilities. To achieve this, LLM-based MASs need to be built around two critical principles: (i) a robust architecture that fully exploits LLM potential for specific tasks -- or related task sets -- and ($ii$) an effective methodology for equipping LLMs with the necessary capabilities to perform tasks and manage information efficiently. It goes without saying that a priori architectural designs can limit the scalability and domain adaptability of a given MAS. To address these challenges, in this paper we introduce Nexus: a lightweight Python framework designed to easily build and manage LLM-based MASs. Nexus introduces the following innovations: (i) a flexible multi-supervisor hierarchy, (ii) a simplified workflow design, and (iii) easy installation and open-source flexibility: Nexus can be installed via pip and is distributed under a permissive open-source license, allowing users to freely modify and extend its capabilities. Experimental results demonstrate that architectures built with Nexus exhibit state-of-the-art performance across diverse domains. In coding tasks, Nexus-driven MASs achieve a 99% pass rate on HumanEval and a flawless 100% on VerilogEval-Human, outperforming cutting-edge reasoning language models such as o3-mini and DeepSeek-R1. Moreover, these architectures display robust proficiency in complex reasoning and mathematical problem solving, achieving correct solutions for all randomly selected problems from the MATH dataset. In the realm of multi-objective optimization, Nexus-based architectures successfully address challenging timing closure tasks on designs from the VTR benchmark suite, while guaranteeing, on average, a power saving of nearly 30%.
Logic Synthesis Meets Machine Learning: Trading Exactness for Generalization
Dec 15, 2020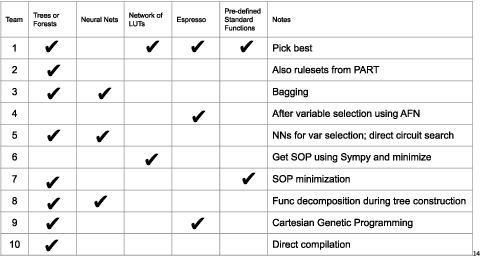
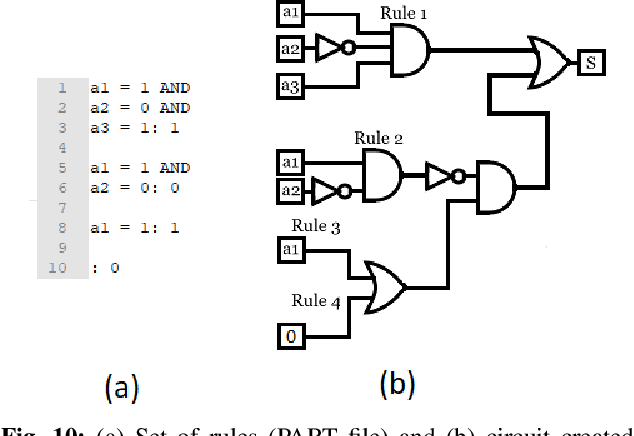
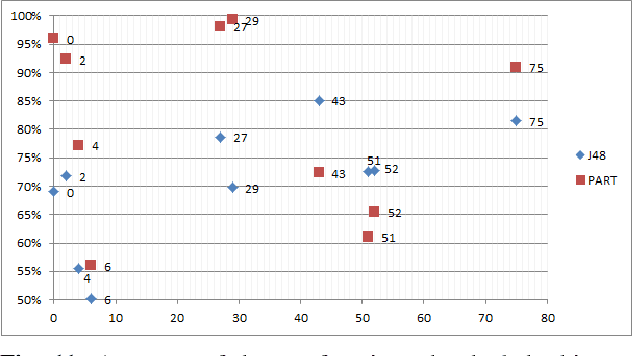
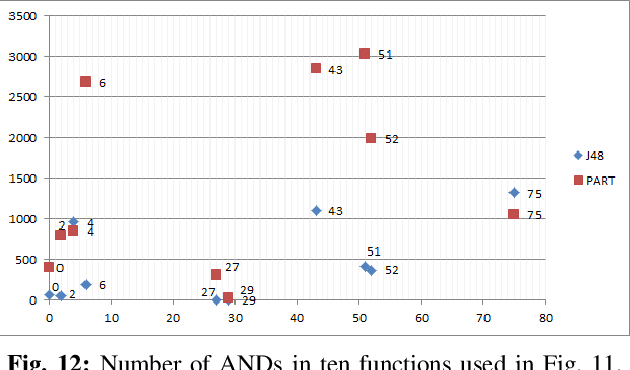
Logic synthesis is a fundamental step in hardware design whose goal is to find structural representations of Boolean functions while minimizing delay and area. If the function is completely-specified, the implementation accurately represents the function. If the function is incompletely-specified, the implementation has to be true only on the care set. While most of the algorithms in logic synthesis rely on SAT and Boolean methods to exactly implement the care set, we investigate learning in logic synthesis, attempting to trade exactness for generalization. This work is directly related to machine learning where the care set is the training set and the implementation is expected to generalize on a validation set. We present learning incompletely-specified functions based on the results of a competition conducted at IWLS 2020. The goal of the competition was to implement 100 functions given by a set of care minterms for training, while testing the implementation using a set of validation minterms sampled from the same function. We make this benchmark suite available and offer a detailed comparative analysis of the different approaches to learning