 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2LLM: Towards Efficient LLM Serving in Heterogeneous Edge/Fog Environments
Jun 02, 2026Large Language Models (LLMs) have become integral to modern applications, yet their deployment remains challenging. Beyond executing the models themselves, practical deployment must address cost efficiency, low latency, and optimal resource utilization. Conventional approaches typically assume that an entire model can be hosted on a single device, which does not hold in many real-world scenarios, particularly in Edge and Fog environments where device resources are constrained. In this paper, we introduce E2LLM, a framework designed to enable efficient LLM deployment in such resource limited settings. Rather than simply partitioning a single model across all available devices, E2LLM replicates the full model across multiple groups of devices (replicas) and applies model parallelism within each replica. Each replica is assigned a specialized role PREFILL or DECODER based on its efficiency in handling input and output tokens. This separation leverages the inherent differences between these two phases of LLM inference. To effectively organize devices, we utilize a Genetic Algorithm to form clusters that maximize system performance. Within each cluster, we apply Dynamic Programming to determine an optimal partitioning strategy that minimizes bottlenecks in model-parallel execution. Experimental results demonstrate that our approach adapts robustly to varying workloads, including scenarios with significant variation in input and output token lengths. Compared to the Splitwise baseline, E2LLM reduces average waiting time by over 50% under high-demand conditions
LLM Compression with Jointly Optimizing Architectural and Quantization choices
Jun 02, 2026Deploying large language models (LLMs) is challenging due to their significant memory and computational requirements. While some methods address this by developing small or tiny language models from scratch, these approaches demand extensive GPU training. Compressing pre-trained LLMs for edge devices offers a compelling alternative. Beyond pruning and quantization, Neural Architecture Search (NAS) enables effective compression, yet prior NAS approaches often limit the search space and decouple architecture from quantization. We introduce a differentiable NAS framework that explores the entire space and jointly optimizes architectural configurations alongside mixed-precision quantization for linear layers of LLMs. Experiments demonstrate superior accuracy-latency trade-offs: our models achieve up to 1.4x faster inference than sequential NAS-then-quantization baselines at comparable accuracy, or up to 6% higher average accuracy across seven reasoning tasks at equivalent latency.
Kernel-Level Energy-Efficient Neural Architecture Search for Tabular Dataset
Apr 11, 2025Many studies estimate energy consumption using proxy metrics like memory usage, FLOPs, and inference latency, with the assumption that reducing these metrics will also lower energy consumption in neural networks. This paper, however, takes a different approach by introducing an energy-efficient Neural Architecture Search (NAS) method that directly focuses on identifying architectures that minimize energy consumption while maintaining acceptable accuracy. Unlike previous methods that primarily target vision and language tasks, the approach proposed here specifically addresses tabular datasets. Remarkably, the optimal architecture suggested by this method can reduce energy consumption by up to 92% compared to architectures recommended by conventional NAS.
CDN-MEDAL: Two-stage Density and Difference Approximation Framework for Motion Analysis
Jun 07, 2021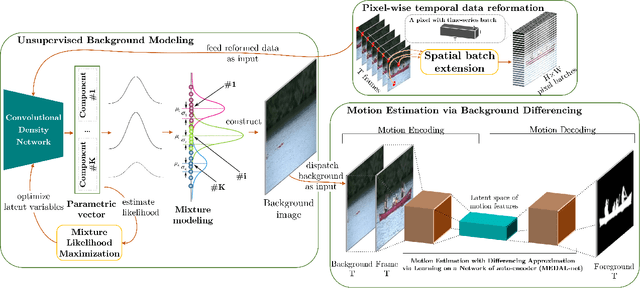
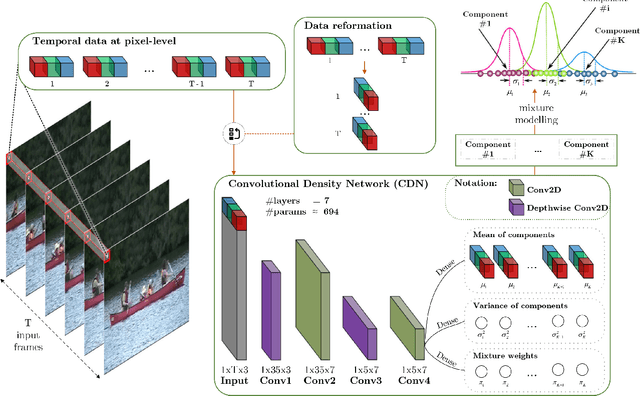
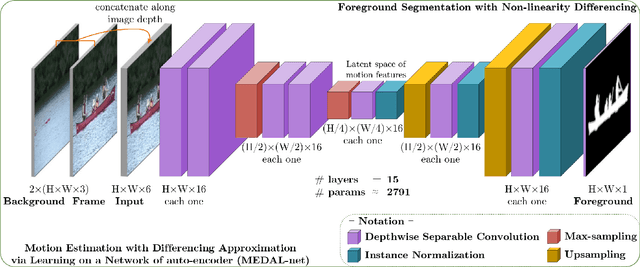

Background modeling is a promising research area in video analysis with a variety of video surveillance applications. Recent years have witnessed the proliferation of deep neural networks via effective learning-based approaches in motion analysis. However, these techniques only provide a limited description of the observed scenes' insufficient properties where a single-valued mapping is learned to approximate the temporal conditional averages of the target background. On the other hand, statistical learning in imagery domains has become one of the most prevalent approaches with high adaptation to dynamic context transformation, notably Gaussian Mixture Models, combined with a foreground extraction step. In this work, we propose a novel, two-stage method of change detection with two convolutional neural networks. The first architecture is grounded on the unsupervised Gaussian mixtures statistical learning to describe the scenes' salient features. The second one implements a light-weight pipeline of foreground detection. Our two-stage framework contains approximately 3.5K parameters in total but still maintains rapid convergence to intricate motion patterns. Our experiments on publicly available datasets show that our proposed networks are not only capable of generalizing regions of moving objects in unseen cases with promising results but also are competitive in performance efficiency and effectiveness regarding foreground segmentation.