 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACZero: PAC-Private Fine-Tuning of Language Models via Sign Quantization
May 07, 2026We introduce PACZero, a family of PAC-private zeroth-order mechanisms for fine-tuning large language models that delivers usable utility at $I(S^*; Y_{1:T})=0$. This privacy regime bounds the membership-inference attack (MIA) posterior success rate at the prior, an MIA-resistance level the DP framework matches only at $\varepsilon=0$ and infinite noise. All DP-ZO comparisons below are matched at the MIA posterior level. The key insight is that PAC Privacy charges mutual information only when the release depends on which candidate subset is the secret. Sign-quantizing subset-aggregated zeroth-order gradients creates frequent unanimity, steps at which every candidate subset agrees on the update direction; at these steps the released sign costs zero conditional mutual information. We propose two variants that span the privacy-utility trade-off: PACZero-MI (budgeted MI via exact calibration on the binary release) and PACZero-ZPL ($I=0$ via a uniform coin flip on disagreement steps). We evaluate on SST-2 and SQuAD with OPT-1.3B and OPT-6.7B in both LoRA and full-parameter tracks. On SST-2 OPT-1.3B full fine-tuning at $I=0$, PACZero-ZPL reaches ${88.99\pm0.91}$, within $2.1$pp of the non-private MeZO baseline ($91.1$ FT). No prior method produces usable utility in the high-privacy regime $\varepsilon<1$, and PACZero-ZPL obtains competitive SST-2 accuracy and nontrivial SQuAD F1 across OPT-1.3B and OPT-6.7B at $I=0$.
Beyond Anonymization: Object Scrubbing for Privacy-Preserving 2D and 3D Vision Tasks
Apr 23, 2025We introduce ROAR (Robust Object Removal and Re-annotation), a scalable framework for privacy-preserving dataset obfuscation that eliminates sensitive objects instead of modifying them. Our method integrates instance segmentation with generative inpainting to remove identifiable entities while preserving scene integrity. Extensive evaluations on 2D COCO-based object detection show that ROAR achieves 87.5% of the baseline detection average precision (AP), whereas image dropping achieves only 74.2% of the baseline AP, highlighting the advantage of scrubbing in preserving dataset utility. The degradation is even more severe for small objects due to occlusion and loss of fine-grained details. Furthermore, in NeRF-based 3D reconstruction, our method incurs a PSNR loss of at most 1.66 dB while maintaining SSIM and improving LPIPS, demonstrating superior perceptual quality. Our findings establish object removal as an effective privacy framework, achieving strong privacy guarantees with minimal performance trade-offs. The results highlight key challenges in generative inpainting, occlusion-robust segmentation, and task-specific scrubbing, setting the foundation for future advancements in privacy-preserving vision systems.
Batch Clipping and Adaptive Layerwise Clipping for Differential Private Stochastic Gradient Descent
Jul 21, 2023Each round in Differential Private Stochastic Gradient Descent (DPSGD) transmits a sum of clipped gradients obfuscated with Gaussian noise to a central server which uses this to update a global model which often represents a deep neural network. Since the clipped gradients are computed separately, which we call Individual Clipping (IC), deep neural networks like resnet-18 cannot use Batch Normalization Layers (BNL) which is a crucial component in deep neural networks for achieving a high accuracy. To utilize BNL, we introduce Batch Clipping (BC) where, instead of clipping single gradients as in the orginal DPSGD, we average and clip batches of gradients. Moreover, the model entries of different layers have different sensitivities to the added Gaussian noise. Therefore, Adaptive Layerwise Clipping methods (ALC), where each layer has its own adaptively finetuned clipping constant, have been introduced and studied, but so far without rigorous DP proofs. In this paper, we propose {\em a new ALC and provide rigorous DP proofs for both BC and ALC}. Experiments show that our modified DPSGD with BC and ALC for CIFAR-$10$ with resnet-$18$ converges while DPSGD with IC and ALC does not.
Considerations on the Theory of Training Models with Differential Privacy
Mar 08, 2023In federated learning collaborative learning takes place by a set of clients who each want to remain in control of how their local training data is used, in particular, how can each client's local training data remain private? Differential privacy is one method to limit privacy leakage. We provide a general overview of its framework and provable properties, adopt the more recent hypothesis based definition called Gaussian DP or $f$-DP, and discuss Differentially Private Stochastic Gradient Descent (DP-SGD). We stay at a meta level and attempt intuitive explanations and insights \textit{in this book chapter}.
Generalizing DP-SGD with Shuffling and Batching Clipping
Dec 12, 2022Classical differential private DP-SGD implements individual clipping with random subsampling, which forces a mini-batch SGD approach. We provide a general differential private algorithmic framework that goes beyond DP-SGD and allows any possible first order optimizers (e.g., classical SGD and momentum based SGD approaches) in combination with batch clipping, which clips an aggregate of computed gradients rather than summing clipped gradients (as is done in individual clipping). The framework also admits sampling techniques beyond random subsampling such as shuffling. Our DP analysis follows the $f$-DP approach and introduces a new proof technique which allows us to also analyse group privacy. In particular, for $E$ epochs work and groups of size $g$, we show a $\sqrt{g E}$ DP dependency for batch clipping with shuffling. This is much better than the previously anticipated linear dependency in $g$ and is much better than the previously expected square root dependency on the total number of rounds within $E$ epochs which is generally much more than $\sqrt{E}$.
Differential Private Hogwild! over Distributed Local Data Sets
Feb 17, 2021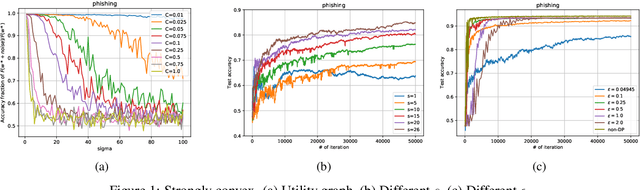

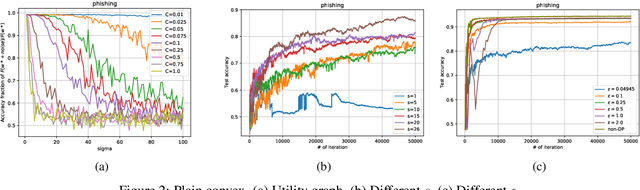
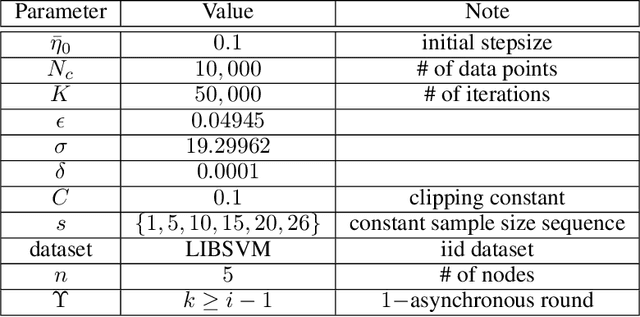
We consider the Hogwild! setting where clients use local SGD iterations with Gaussian based Differential Privacy (DP) for their own local data sets with the aim of (1) jointly converging to a global model (by interacting at a round to round basis with a centralized server that aggregates local SGD updates into a global model) while (2) keeping each local data set differentially private with respect to the outside world (this includes all other clients who can monitor client-server interactions). We show for a broad class of sample size sequences (this defines the number of local SGD iterations for each round) that a local data set is $(\epsilon,\delta)$-DP if the standard deviation $\sigma$ of the added Gaussian noise per round interaction with the centralized server is at least $\sqrt{2(\epsilon+ \ln(1/\delta))/\epsilon}$.
Hogwild! over Distributed Local Data Sets with Linearly Increasing Mini-Batch Sizes
Oct 27, 2020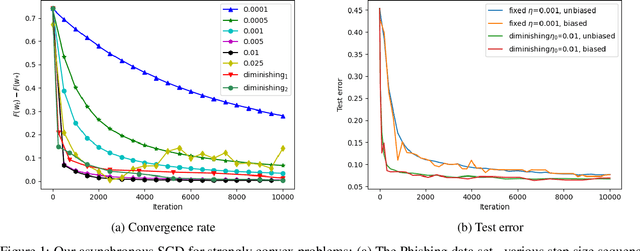

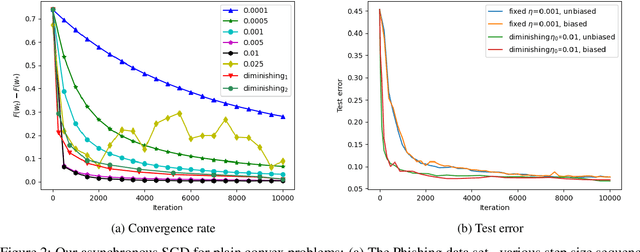
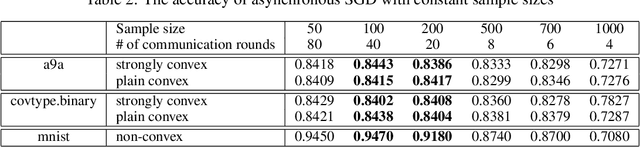
Hogwild! implements asynchronous Stochastic Gradient Descent (SGD) where multiple threads in parallel access a common repository containing training data, perform SGD iterations and update shared state that represents a jointly learned (global) model. We consider big data analysis where training data is distributed among local data sets -- and we wish to move SGD computations to local compute nodes where local data resides. The results of these local SGD computations are aggregated by a central "aggregator" which mimics Hogwild!. We show how local compute nodes can start choosing small mini-batch sizes which increase to larger ones in order to reduce communication cost (round interaction with the aggregator). We prove a tight and novel non-trivial convergence analysis for strongly convex problems which does not use the bounded gradient assumption as seen in many existing publications. The tightness is a consequence of our proofs for lower and upper bounds of the convergence rate, which show a constant factor difference. We show experimental results for plain convex and non-convex problems for biased and unbiased local data sets.
Asynchronous Federated Learning with Reduced Number of Rounds and with Differential Privacy from Less Aggregated Gaussian Noise
Jul 17, 2020

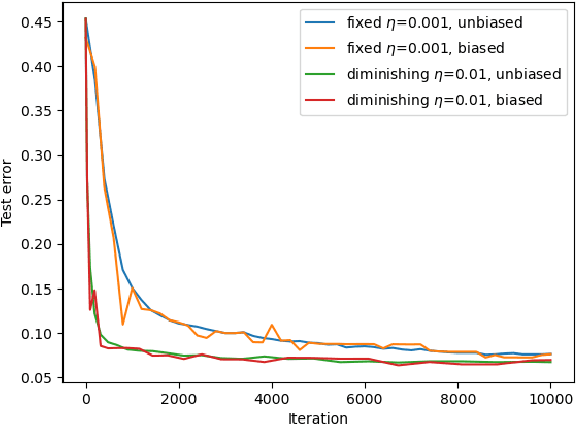

The feasibility of federated learning is highly constrained by the server-clients infrastructure in terms of network communication. Most newly launched smartphones and IoT devices are equipped with GPUs or sufficient computing hardware to run powerful AI models. However, in case of the original synchronous federated learning, client devices suffer waiting times and regular communication between clients and server is required. This implies more sensitivity to local model training times and irregular or missed updates, hence, less or limited scalability to large numbers of clients and convergence rates measured in real time will suffer. We propose a new algorithm for asynchronous federated learning which eliminates waiting times and reduces overall network communication - we provide rigorous theoretical analysis for strongly convex objective functions and provide simulation results. By adding Gaussian noise we show how our algorithm can be made differentially private -- new theorems show how the aggregated added Gaussian noise is significantly reduced.
Beware the Black-Box: on the Robustness of Recent Defenses to Adversarial Examples
Jun 18, 2020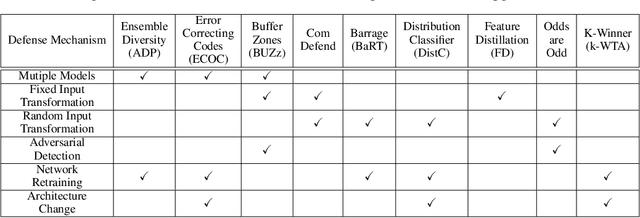
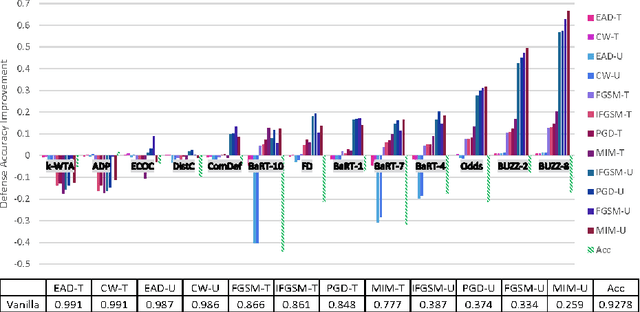
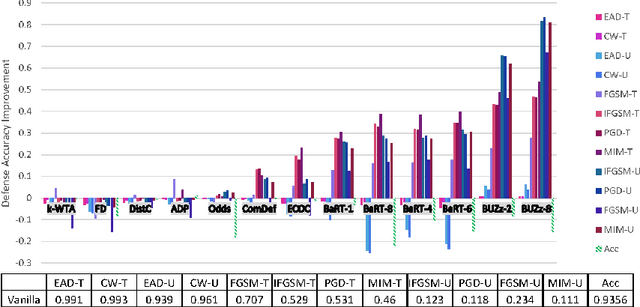
Recent defenses published at venues like NIPS, ICML, ICLR and CVPR are mainly focused on mitigating white-box attacks. These defenses do not properly consider adaptive adversaries. In this paper, we expand the scope of these defenses to include adaptive black-box adversaries. Our evaluation is done on nine defenses including Barrage of Random Transforms, ComDefend, Ensemble Diversity, Feature Distillation, The Odds are Odd, Error Correcting Codes, Distribution Classifier Defense, K-Winner Take All and Buffer Zones. Our investigation is done using two black-box adversarial models and six widely studied adversarial attacks for CIFAR-10 and Fashion-MNIST datasets. Our analyses show most recent defenses provide only marginal improvements in security, as compared to undefended networks. Based on these results, we propose new standards for properly evaluating defenses to black-box adversaries. We provide this security framework to assist researchers in developing future black-box resistant models.
A Hybrid Stochastic Policy Gradient Algorithm for Reinforcement Learning
Mar 01, 2020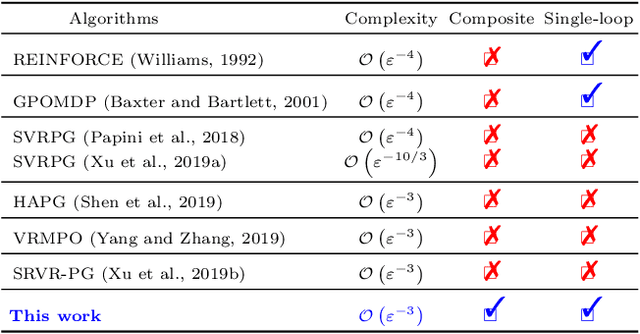
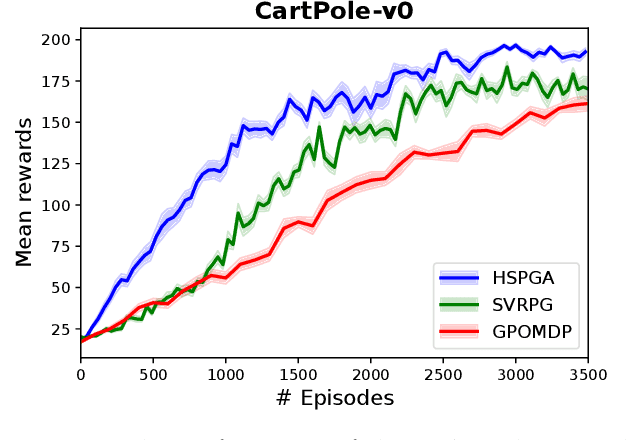
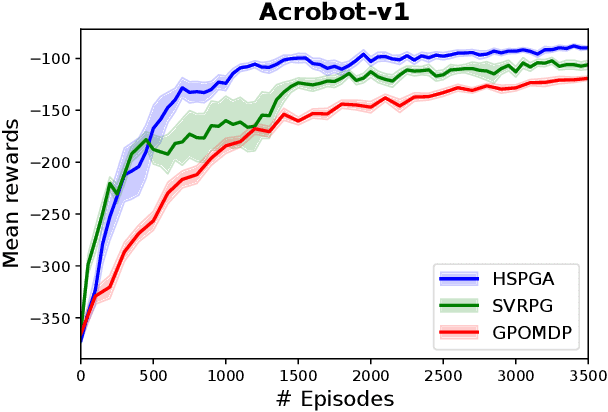
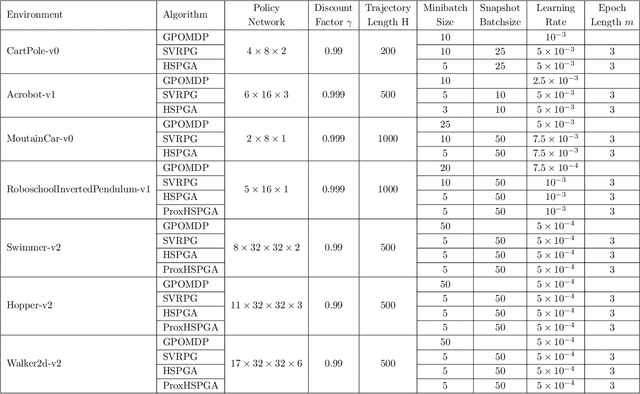
We propose a novel hybrid stochastic policy gradient estimator by combining an unbiased policy gradient estimator, the REINFORCE estimator, with another biased one, an adapted SARAH estimator for policy optimization. The hybrid policy gradient estimator is shown to be biased, but has variance reduced property. Using this estimator, we develop a new Proximal Hybrid Stochastic Policy Gradient Algorithm (ProxHSPGA) to solve a composite policy optimization problem that allows us to handle constraints or regularizers on the policy parameters. We first propose a single-looped algorithm then introduce a more practical restarting variant. We prove that both algorithms can achieve the best-known trajectory complexity $\mathcal{O}\left(\varepsilon^{-3}\right)$ to attain a first-order stationary point for the composite problem which is better than existing REINFORCE/GPOMDP $\mathcal{O}\left(\varepsilon^{-4}\right)$ and SVRPG $\mathcal{O}\left(\varepsilon^{-10/3}\right)$ in the non-composite setting. We evaluate the performance of our algorithm on several well-known examples in reinforcement learning. Numerical results show that our algorithm outperforms two existing methods on these examples. Moreover, the composite settings indeed have some advantages compared to the non-composite ones on certain problems.