 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimensional hierarchical dictionary search for large MIMO-OFDM systems
May 18, 2026Sparse recovery algorithms are of utmost importance for estimation processes in wireless communications. However, communication systems such as massive multiple input multiple output (MIMO) systems are rapidly growing in dimension, which consequently increases the computational complexity of these algorithms. This work proposes a low-complexity strategy for the efficient implementation of the ''atom selection step'' in these greedy sparse recovery algorithms, based on the structural features of these systems. A theoretical justification is presented along with tests using realistic channel data, to demonstrate the computational gain induced by the proposed approach and compare it to the classical sparse recovery approach.
Physically constrained unfolded multi-dimensional OMP for large MIMO systems
Jan 15, 2026Sparse recovery methods are essential for channel estimation and localization in modern communication systems, but their reliability relies on accurate physical models, which are rarely perfectly known. Their computational complexity also grows rapidly with the dictionary dimensions in large MIMO systems. In this paper, we propose MOMPnet, a novel unfolded sparse recovery framework that addresses both the reliability and complexity challenges of traditional methods. By integrating deep unfolding with data-driven dictionary learning, MOMPnet mitigates hardware impairments while preserving interpretability. Instead of a single large dictionary, multiple smaller, independent dictionaries are employed, enabling a low-complexity multidimensional Orthogonal Matching Pursuit algorithm. The proposed unfolded network is evaluated on realistic channel data against multiple baselines, demonstrating its strong performance and potential.
Model-based learning for joint channel estimationand hybrid MIMO precoding
May 07, 2025Hybrid precoding is a key ingredient of cost-effective massive multiple-input multiple-output transceivers. However, setting jointly digital and analog precoders to optimally serve multiple users is a difficult optimization problem. Moreover, it relies heavily on precise knowledge of the channels, which is difficult to obtain, especially when considering realistic systems comprising hardware impairments. In this paper, a joint channel estimation and hybrid precoding method is proposed, which consists in an end-to-end architecture taking received pilots as inputs and outputting precoders. The resulting neural network is fully model-based, making it lightweight and interpretable with very few learnable parameters. The channel estimation step is performed using the unfolded matching pursuit algorithm, accounting for imperfect knowledge of the antenna system, while the precoding step is done via unfolded projected gradient ascent. The great potential of the proposed method is empirically demonstrated on realistic synthetic channels.
Reinforcement Learning for Physical Layer Communications
Jul 01, 2021

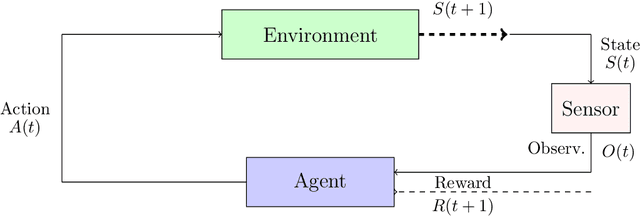
In this chapter, we will give comprehensive examples of applying RL in optimizing the physical layer of wireless communications by defining different class of problems and the possible solutions to handle them. In Section 9.2, we present all the basic theory needed to address a RL problem, i.e. Markov decision process (MDP), Partially observable Markov decision process (POMDP), but also two very important and widely used algorithms for RL, i.e. the Q-learning and SARSA algorithms. We also introduce the deep reinforcement learning (DRL) paradigm and the section ends with an introduction to the multi-armed bandits (MAB) framework. Section 9.3 focuses on some toy examples to illustrate how the basic concepts of RL are employed in communication systems. We present applications extracted from literature with simplified system models using similar notation as in Section 9.2 of this Chapter. In Section 9.3, we also focus on modeling RL problems, i.e. how action and state spaces and rewards are chosen. The Chapter is concluded in Section 9.4 with a prospective thought on RL trends and it ends with a review of a broader state of the art in Section 9.5.