 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal-domain representation of symbolic music for learning embedding spaces
Sep 08, 2021

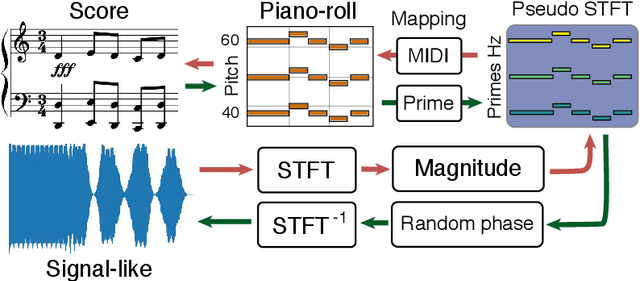
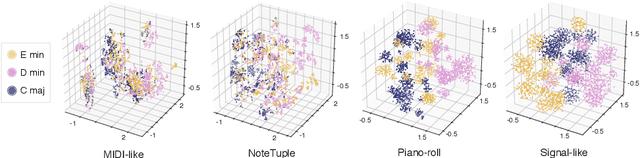
A key aspect of machine learning models lies in their ability to learn efficient intermediate features. However, the input representation plays a crucial role in this process, and polyphonic musical scores remain a particularly complex type of information. In this paper, we introduce a novel representation of symbolic music data, which transforms a polyphonic score into a continuous signal. We evaluate the ability to learn meaningful features from this representation from a musical point of view. Hence, we introduce an evaluation method relying on principled generation of synthetic data. Finally, to test our proposed representation we conduct an extensive benchmark against recent polyphonic symbolic representations. We show that our signal-like representation leads to better reconstruction and disentangled features. This improvement is reflected in the metric properties and in the generation ability of the space learned from our signal-like representation according to music theory properties.
A Multi-Objective Approach for Sustainable Generative Audio Models
Jul 06, 2021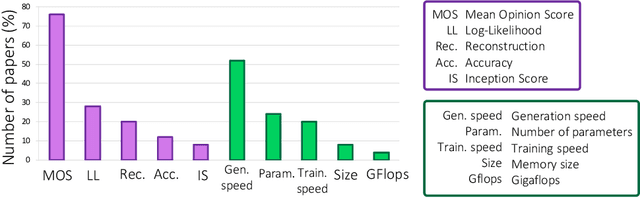


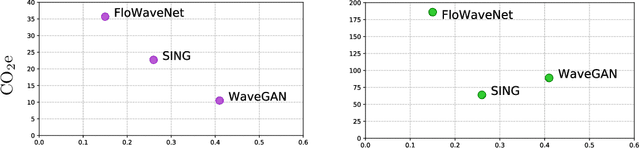
In recent years, the deep learning community has largely focused on the accuracy of deep generative models, resulting in impressive improvements in several research fields. However, this scientific race for quality comes at a tremendous computational cost, which incurs vast energy consumption and greenhouse gas emissions. If the current exponential growth of computational consumption persists, Artificial Intelligence (AI) will sadly become a considerable contributor to global warming. At the heart of this problem are the measures that we use as a scientific community to evaluate our work. Currently, researchers in the field of AI judge scientific works mostly based on the improvement in accuracy, log-likelihood, reconstruction or opinion scores, all of which entirely obliterates the actual computational cost of generative models. In this paper, we introduce the idea of relying on a multi-objective measure based on Pareto optimality, which simultaneously integrates the models accuracy, as well as the environmental impact of their training. By applying this measure on the current state-of-the-art in generative audio models, we show that this measure drastically changes the perceived significance of the results in the field, encouraging optimal training techniques and resource allocation. We hope that this type of measure will be widely adopted, in order to help the community to better evaluate the significance of their work, while bringing computational cost -- and in fine carbon emissions -- in the spotlight of AI research.
Spectrogram Inpainting for Interactive Generation of Instrument Sounds
Apr 15, 2021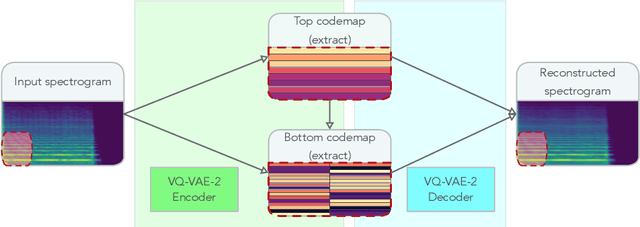
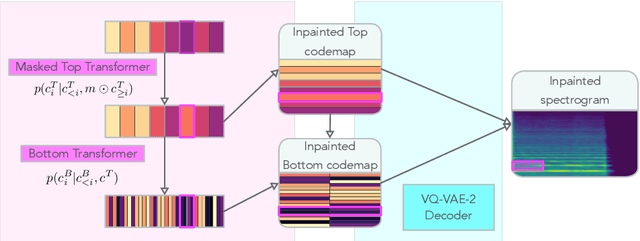
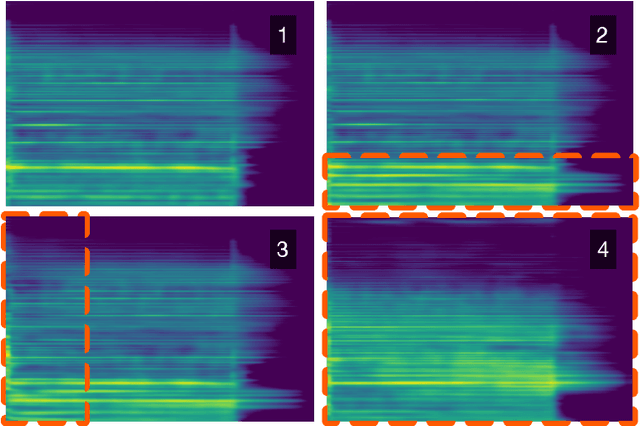
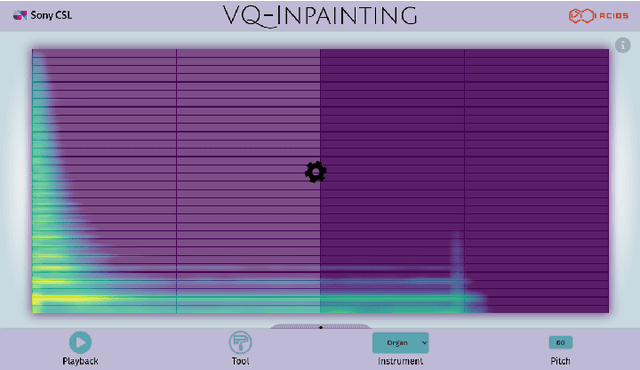
Modern approaches to sound synthesis using deep neural networks are hard to control, especially when fine-grained conditioning information is not available, hindering their adoption by musicians. In this paper, we cast the generation of individual instrumental notes as an inpainting-based task, introducing novel and unique ways to iteratively shape sounds. To this end, we propose a two-step approach: first, we adapt the VQ-VAE-2 image generation architecture to spectrograms in order to convert real-valued spectrograms into compact discrete codemaps, we then implement token-masked Transformers for the inpainting-based generation of these codemaps. We apply the proposed architecture on the NSynth dataset on masked resampling tasks. Most crucially, we open-source an interactive web interface to transform sounds by inpainting, for artists and practitioners alike, opening up to new, creative uses.
* 8 pages + references + appendices. 4 figures. Published as a conference paper at the The 2020 Joint Conference on AI Music Creativity, October 19-23, 2020, organized and hosted virtually by the Royal Institute of Technology (KTH), Stockholm, Sweden
Neural Granular Sound Synthesis
Aug 31, 2020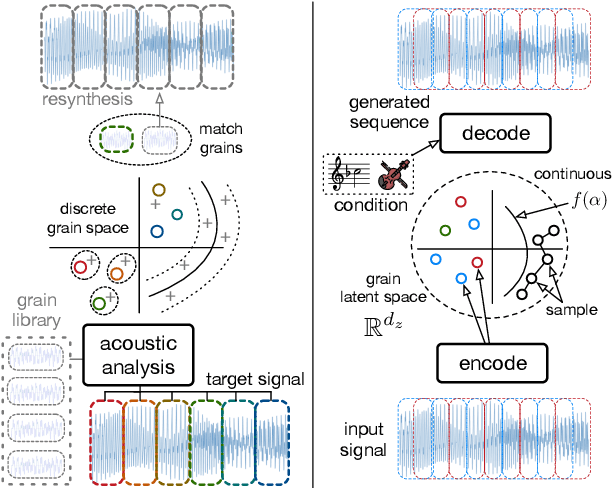
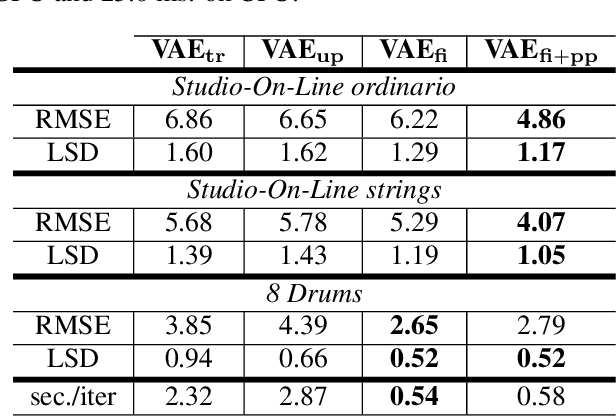
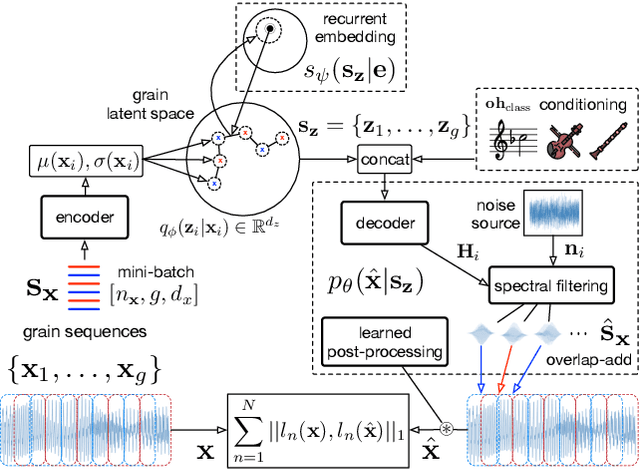
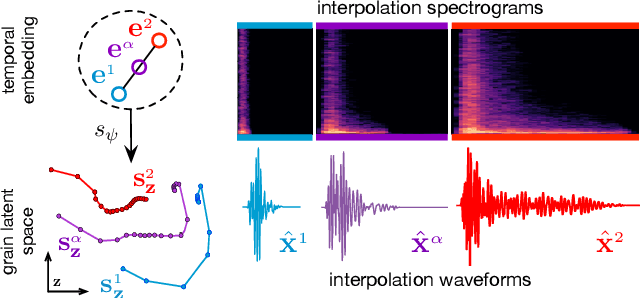
Granular sound synthesis is a popular audio generation technique based on rearranging sequences of small waveform windows. In order to control the synthesis, all grains in a given corpus are analyzed through a set of acoustic descriptors. This provides a representation reflecting some form of local similarities across the grains. However, the quality of this grain space is bound by that of the descriptors. Its traversal is not continuously invertible to signal and does not render any structured temporality. We demonstrate that generative neural networks can implement granular synthesis while alleviating most of its shortcomings. We efficiently replace its audio descriptor basis by a probabilistic latent space learned with a Variational Auto-Encoder. A major advantage of our proposal is that the resulting grain space is invertible, meaning that we can continuously synthesize sound when traversing its dimensions. It also implies that original grains are not stored for synthesis. To learn structured paths inside this latent space, we add a higher-level temporal embedding trained on arranged grain sequences. The model can be applied to many types of libraries, including pitched notes or unpitched drums and environmental noises. We experiment with the common granular synthesis processes and enable new ones.
Timbre latent space: exploration and creative aspects
Aug 17, 2020
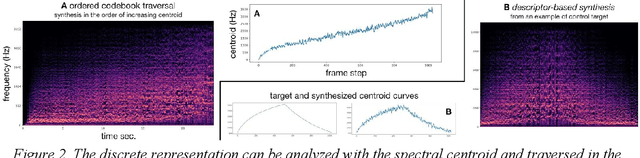
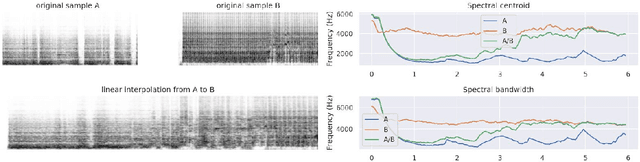
Recent studies show the ability of unsupervised models to learn invertible audio representations using Auto-Encoders. They enable high-quality sound synthesis but a limited control since the latent spaces do not disentangle timbre properties. The emergence of disentangled representations was studied in Variational Auto-Encoders (VAEs), and has been applied to audio. Using an additional perceptual regularization can align such latent representation with the previously established multi-dimensional timbre spaces, while allowing continuous inference and synthesis. Alternatively, some specific sound attributes can be learned as control variables while unsupervised dimensions account for the remaining features. New possibilities for timbre manipulations are enabled with generative neural networks, although the exploration and the creative use of their representations remain little. The following experiments are led in cooperation with two composers and propose new creative directions to explore latent sound synthesis of musical timbres, using specifically designed interfaces (Max/MSP, Pure Data) or mappings for descriptor-based synthesis.
Creativity in the era of artificial intelligence
Aug 13, 2020Creativity is a deeply debated topic, as this concept is arguably quintessential to our humanity. Across different epochs, it has been infused with an extensive variety of meanings relevant to that era. Along these, the evolution of technology have provided a plurality of novel tools for creative purposes. Recently, the advent of Artificial Intelligence (AI), through deep learning approaches, have seen proficient successes across various applications. The use of such technologies for creativity appear in a natural continuity to the artistic trend of this century. However, the aura of a technological artefact labeled as intelligent has unleashed passionate and somewhat unhinged debates on its implication for creative endeavors. In this paper, we aim to provide a new perspective on the question of creativity at the era of AI, by blurring the frontier between social and computational sciences. To do so, we rely on reflections from social science studies of creativity to view how current AI would be considered through this lens. As creativity is a highly context-prone concept, we underline the limits and deficiencies of current AI, requiring to move towards artificial creativity. We argue that the objective of trying to purely mimic human creative traits towards a self-contained ex-nihilo generative machine would be highly counterproductive, putting us at risk of not harnessing the almost unlimited possibilities offered by the sheer computational power of artificial agents.
Ultra-light deep MIR by trimming lottery tickets
Jul 31, 2020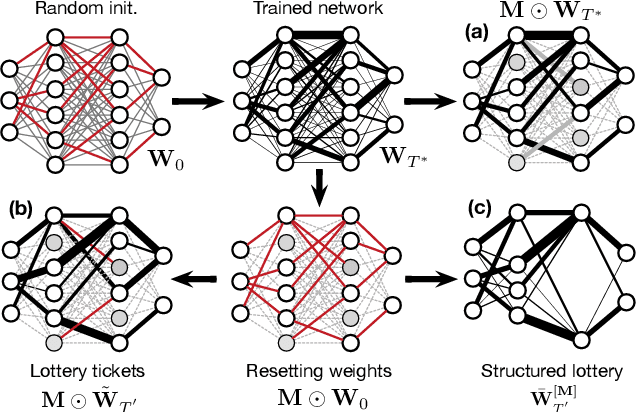
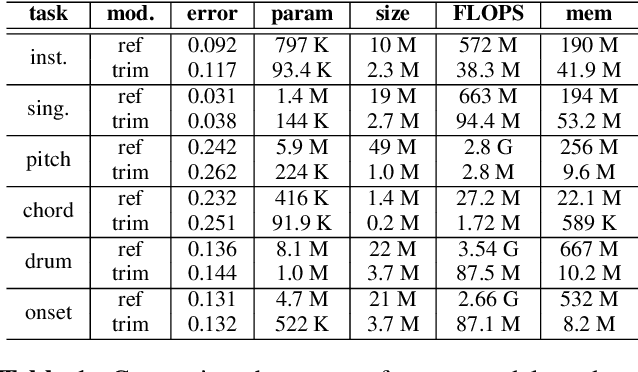
Current state-of-the-art results in Music Information Retrieval are largely dominated by deep learning approaches. These provide unprecedented accuracy across all tasks. However, the consistently overlooked downside of these models is their stunningly massive complexity, which seems concomitantly crucial to their success. In this paper, we address this issue by proposing a model pruning method based on the lottery ticket hypothesis. We modify the original approach to allow for explicitly removing parameters, through structured trimming of entire units, instead of simply masking individual weights. This leads to models which are effectively lighter in terms of size, memory and number of operations. We show that our proposal can remove up to 90% of the model parameters without loss of accuracy, leading to ultra-light deep MIR models. We confirm the surprising result that, at smaller compression ratios (removing up to 85% of a network), lighter models consistently outperform their heavier counterparts. We exhibit these results on a large array of MIR tasks including audio classification, pitch recognition, chord extraction, drum transcription and onset estimation. The resulting ultra-light deep learning models for MIR can run on CPU, and can even fit on embedded devices with minimal degradation of accuracy.
Diet deep generative audio models with structured lottery
Jul 31, 2020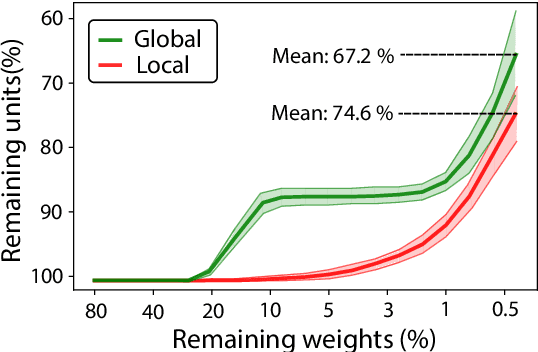
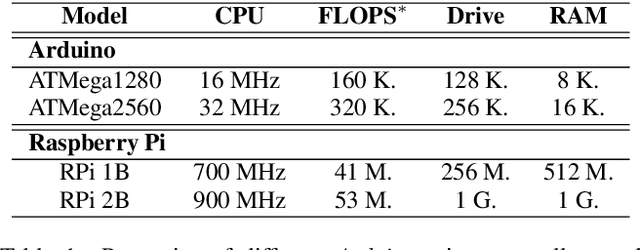
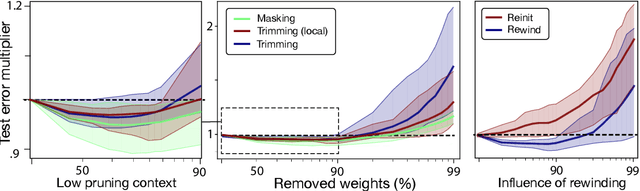
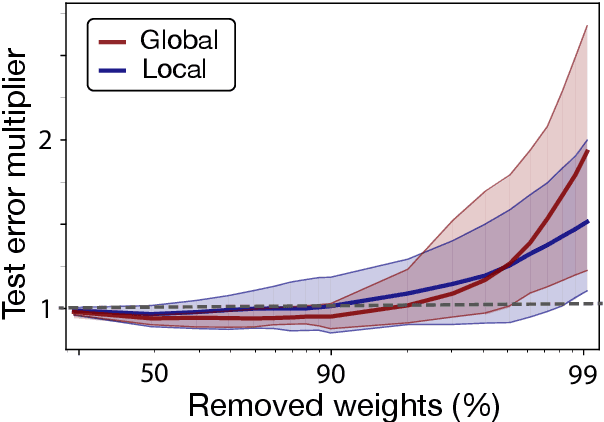
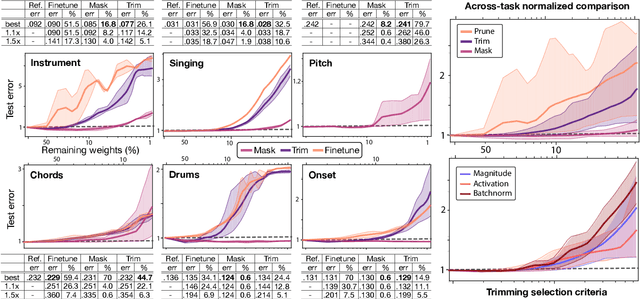
Deep learning models have provided extremely successful solutions in most audio application fields. However, the high accuracy of these models comes at the expense of a tremendous computation cost. This aspect is almost always overlooked in evaluating the quality of proposed models. However, models should not be evaluated without taking into account their complexity. This aspect is especially critical in audio applications, which heavily relies on specialized embedded hardware with real-time constraints. In this paper, we build on recent observations that deep models are highly overparameterized, by studying the lottery ticket hypothesis on deep generative audio models. This hypothesis states that extremely efficient small sub-networks exist in deep models and would provide higher accuracy than larger models if trained in isolation. However, lottery tickets are found by relying on unstructured masking, which means that resulting models do not provide any gain in either disk size or inference time. Instead, we develop here a method aimed at performing structured trimming. We show that this requires to rely on global selection and introduce a specific criterion based on mutual information. First, we confirm the surprising result that smaller models provide higher accuracy than their large counterparts. We further show that we can remove up to 95% of the model weights without significant degradation in accuracy. Hence, we can obtain very light models for generative audio across popular methods such as Wavenet, SING or DDSP, that are up to 100 times smaller with commensurate accuracy. We study the theoretical bounds for embedding these models on Raspberry Pi and Arduino, and show that we can obtain generative models on CPU with equivalent quality as large GPU models. Finally, we discuss the possibility of implementing deep generative audio models on embedded platforms.
Vector-Quantized Timbre Representation
Jul 13, 2020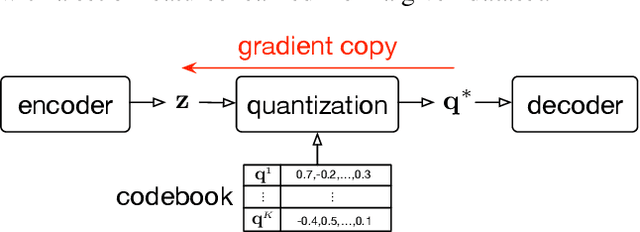
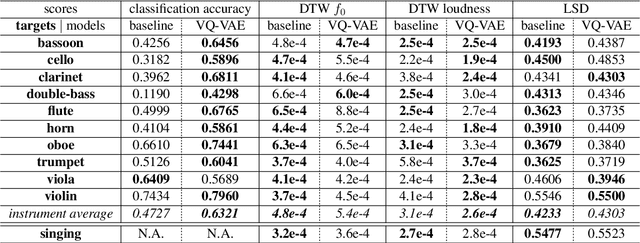

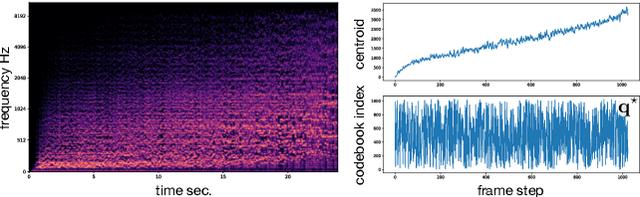
Timbre is a set of perceptual attributes that identifies different types of sound sources. Although its definition is usually elusive, it can be seen from a signal processing viewpoint as all the spectral features that are perceived independently from pitch and loudness. Some works have studied high-level timbre synthesis by analyzing the feature relationships of different instruments, but acoustic properties remain entangled and generation bound to individual sounds. This paper targets a more flexible synthesis of an individual timbre by learning an approximate decomposition of its spectral properties with a set of generative features. We introduce an auto-encoder with a discrete latent space that is disentangled from loudness in order to learn a quantized representation of a given timbre distribution. Timbre transfer can be performed by encoding any variable-length input signals into the quantized latent features that are decoded according to the learned timbre. We detail results for translating audio between orchestral instruments and singing voice, as well as transfers from vocal imitations to instruments as an intuitive modality to drive sound synthesis. Furthermore, we can map the discrete latent space to acoustic descriptors and directly perform descriptor-based synthesis.
Cross-modal variational inference for bijective signal-symbol translation
Feb 10, 2020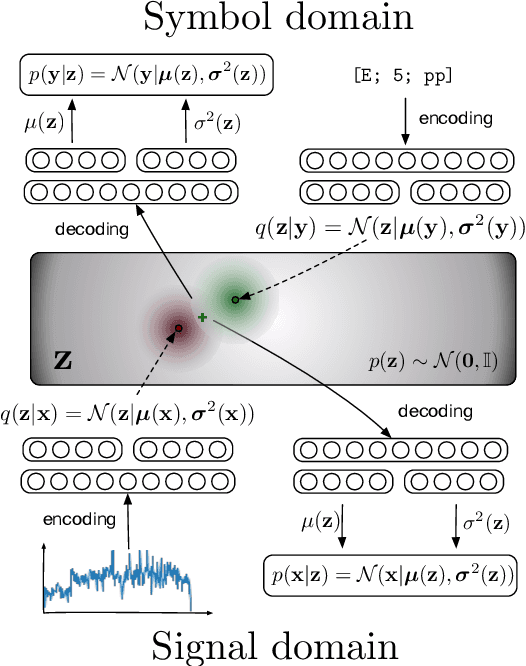
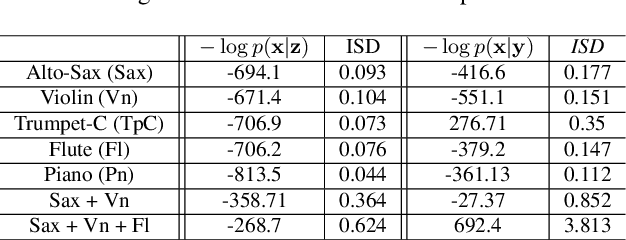
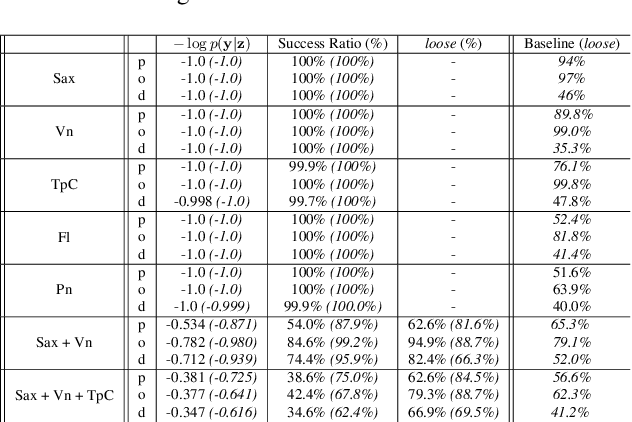
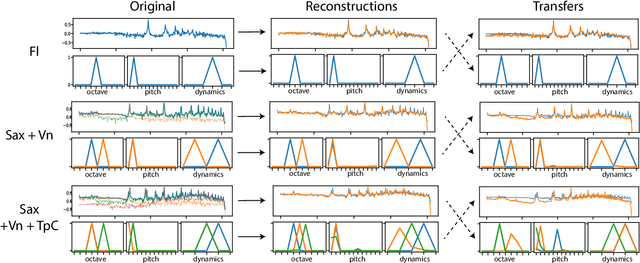
Extraction of symbolic information from signals is an active field of research enabling numerous applications especially in the Musical Information Retrieval domain. This complex task, that is also related to other topics such as pitch extraction or instrument recognition, is a demanding subject that gave birth to numerous approaches, mostly based on advanced signal processing-based algorithms. However, these techniques are often non-generic, allowing the extraction of definite physical properties of the signal (pitch, octave), but not allowing arbitrary vocabularies or more general annotations. On top of that, these techniques are one-sided, meaning that they can extract symbolic data from an audio signal, but cannot perform the reverse process and make symbol-to-signal generation. In this paper, we propose an bijective approach for signal/symbol translation by turning this problem into a density estimation task over signal and symbolic domains, considered both as related random variables. We estimate this joint distribution with two different variational auto-encoders, one for each domain, whose inner representations are forced to match with an additive constraint, allowing both models to learn and generate separately while allowing signal-to-symbol and symbol-to-signal inference. In this article, we test our models on pitch, octave and dynamics symbols, which comprise a fundamental step towards music transcription and label-constrained audio generation. In addition to its versatility, this system is rather light during training and generation while allowing several interesting creative uses that we outline at the end of the article.