 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Distributed Equilibria in Linear-Quadratic Stochastic Differential Games: An $α$-Potential Approach
Feb 18, 2026We analyze independent policy-gradient (PG) learning in $N$-player linear-quadratic (LQ) stochastic differential games. Each player employs a distributed policy that depends only on its own state and updates the policy independently using the gradient of its own objective. We establish global linear convergence of these methods to an equilibrium by showing that the LQ game admits an $α$-potential structure, with $α$ determined by the degree of pairwise interaction asymmetry. For pairwise-symmetric interactions, we construct an affine distributed equilibrium by minimizing the potential function and show that independent PG methods converge globally to this equilibrium, with complexity scaling linearly in the population size and logarithmically in the desired accuracy. For asymmetric interactions, we prove that independent projected PG algorithms converge linearly to an approximate equilibrium, with suboptimality proportional to the degree of asymmetry. Numerical experiments confirm the theoretical results across both symmetric and asymmetric interaction networks.
The More the Merrier: Running Multiple Neuromorphic Components On-Chip for Robotic Control
Feb 14, 2026It has long been realized that neuromorphic hardware offers benefits for the domain of robotics such as low energy, low latency, as well as unique methods of learning. In aiming for more complex tasks, especially those incorporating multimodal data, one hurdle continuing to prevent their realization is an inability to orchestrate multiple networks on neuromorphic hardware without resorting to off-chip process management logic. To address this, we show a first example of a pipeline for vision-based robot control in which numerous complex networks can be run entirely on hardware via the use of a spiking neural state machine for process orchestration. The pipeline is validated on the Intel Loihi 2 research chip. We show that all components can run concurrently on-chip in the milli Watt regime at latencies competitive with the state-of-the-art. An equivalent network on simulated hardware is shown to accomplish robotic arm plug insertion in simulation, and the core elements of the pipeline are additionally tested on a real robotic arm.
Policy Optimization for Continuous-time Linear-Quadratic Graphon Mean Field Games
Jun 06, 2025



Multi-agent reinforcement learning, despite its popularity and empirical success, faces significant scalability challenges in large-population dynamic games. Graphon mean field games (GMFGs) offer a principled framework for approximating such games while capturing heterogeneity among players. In this paper, we propose and analyze a policy optimization framework for continuous-time, finite-horizon linear-quadratic GMFGs. Exploiting the structural properties of GMFGs, we design an efficient policy parameterization in which each player's policy is represented as an affine function of their private state, with a shared slope function and player-specific intercepts. We develop a bilevel optimization algorithm that alternates between policy gradient updates for best-response computation under a fixed population distribution, and distribution updates using the resulting policies. We prove linear convergence of the policy gradient steps to best-response policies and establish global convergence of the overall algorithm to the Nash equilibrium. The analysis relies on novel landscape characterizations over infinite-dimensional policy spaces. Numerical experiments demonstrate the convergence and robustness of the proposed algorithm under varying graphon structures, noise levels, and action frequencies.
A Long Short-Term Memory for AI Applications in Spike-based Neuromorphic Hardware
Jul 08, 2021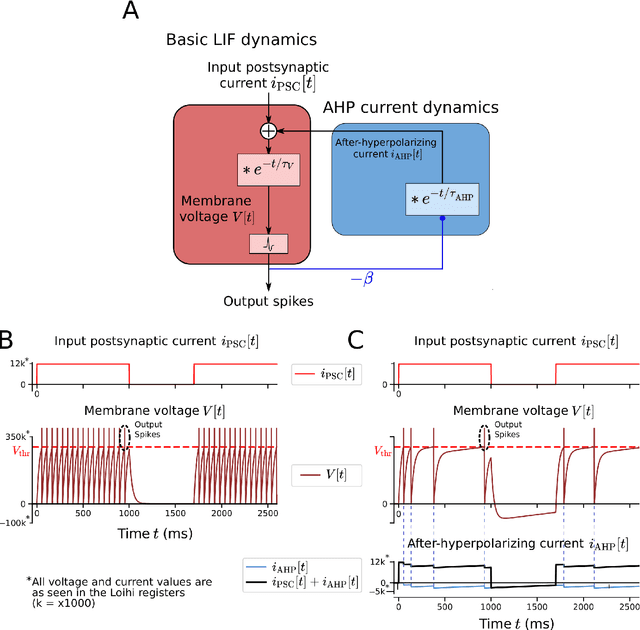
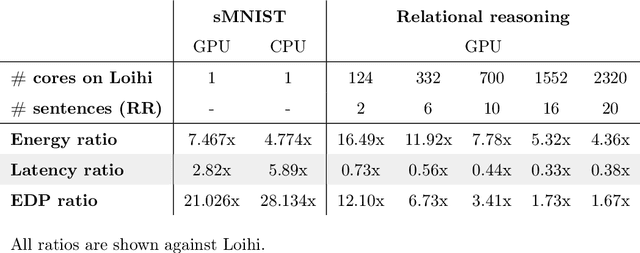
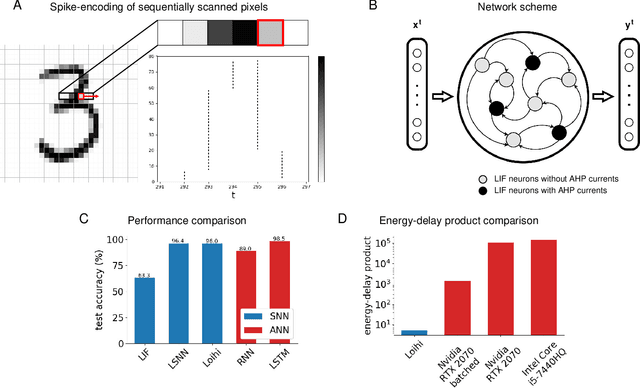
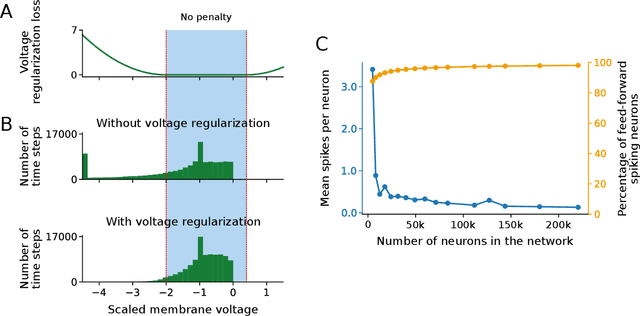
In spite of intensive efforts it has remained an open problem to what extent current Artificial Intelligence (AI) methods that employ Deep Neural Networks (DNNs) can be implemented more energy-efficiently on spike-based neuromorphic hardware. This holds in particular for AI methods that solve sequence processing tasks, a primary application target for spike-based neuromorphic hardware. One difficulty is that DNNs for such tasks typically employ Long Short-Term Memory (LSTM) units. Yet an efficient emulation of these units in spike-based hardware has been missing. We present a biologically inspired solution that solves this problem. This solution enables us to implement a major class of DNNs for sequence processing tasks such as time series classification and question answering with substantial energy savings on neuromorphic hardware. In fact, the Relational Network for reasoning about relations between objects that we use for question answering is the first example of a large DNN that carries out a sequence processing task with substantial energy-saving on neuromorphic hardware.