 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage as a Latent Variable: Discrete Generative Models for Sentence Compression
Oct 14, 2016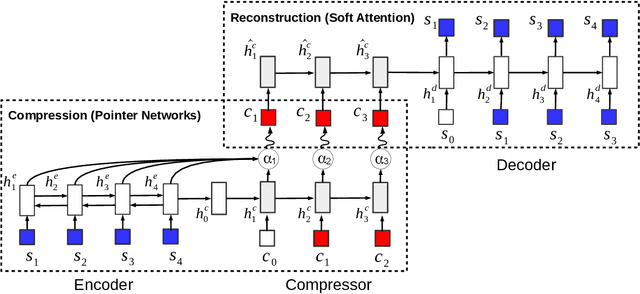
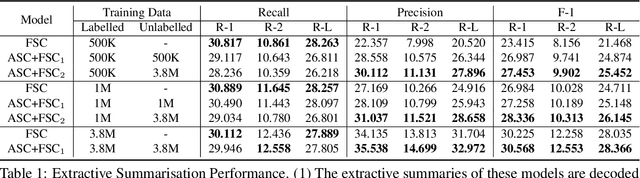
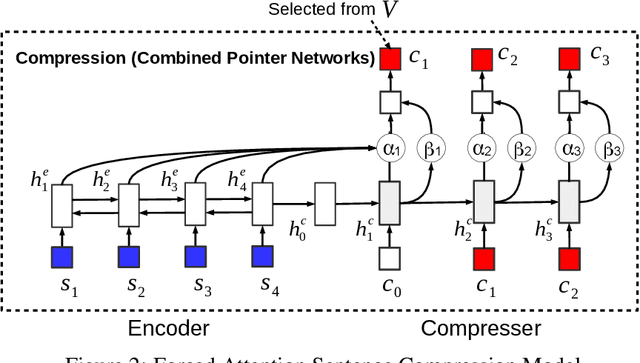
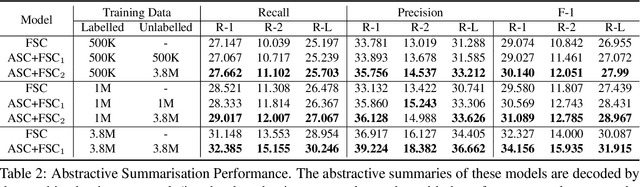
In this work we explore deep generative models of text in which the latent representation of a document is itself drawn from a discrete language model distribution. We formulate a variational auto-encoder for inference in this model and apply it to the task of compressing sentences. In this application the generative model first draws a latent summary sentence from a background language model, and then subsequently draws the observed sentence conditioned on this latent summary. In our empirical evaluation we show that generative formulations of both abstractive and extractive compression yield state-of-the-art results when trained on a large amount of supervised data. Further, we explore semi-supervised compression scenarios where we show that it is possible to achieve performance competitive with previously proposed supervised models while training on a fraction of the supervised data.
Semantic Parsing with Semi-Supervised Sequential Autoencoders
Sep 29, 2016

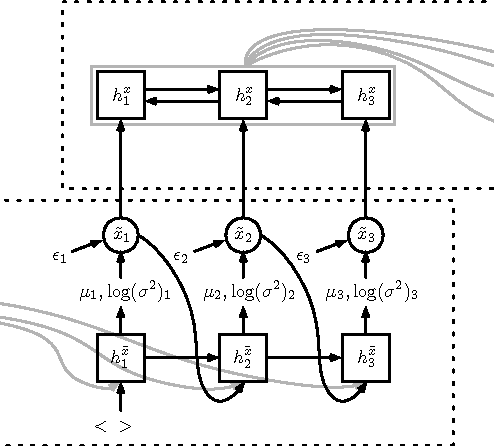
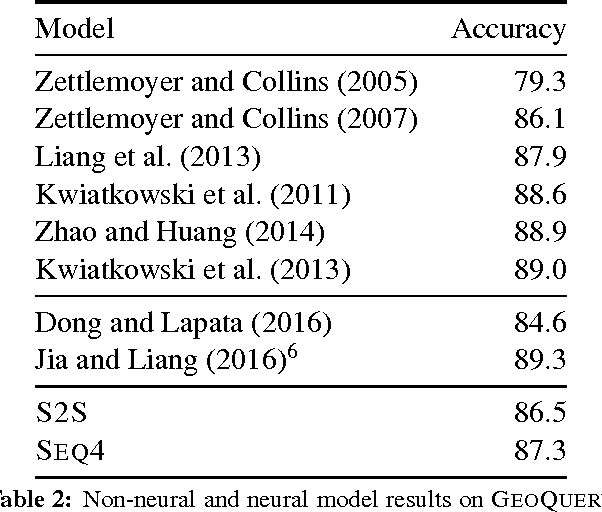
We present a novel semi-supervised approach for sequence transduction and apply it to semantic parsing. The unsupervised component is based on a generative model in which latent sentences generate the unpaired logical forms. We apply this method to a number of semantic parsing tasks focusing on domains with limited access to labelled training data and extend those datasets with synthetically generated logical forms.
Online Segment to Segment Neural Transduction
Sep 26, 2016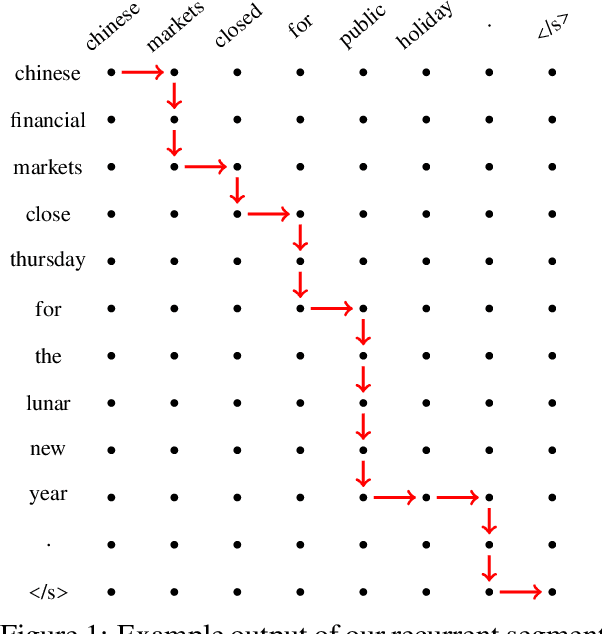
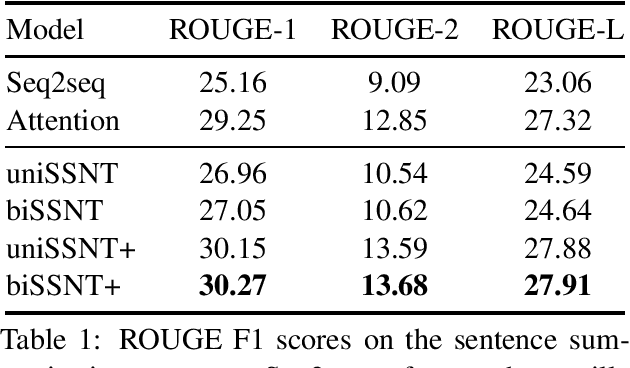
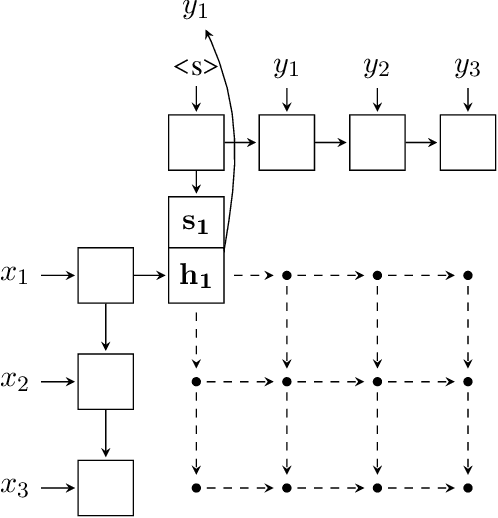
We introduce an online neural sequence to sequence model that learns to alternate between encoding and decoding segments of the input as it is read. By independently tracking the encoding and decoding representations our algorithm permits exact polynomial marginalization of the latent segmentation during training, and during decoding beam search is employed to find the best alignment path together with the predicted output sequence. Our model tackles the bottleneck of vanilla encoder-decoders that have to read and memorize the entire input sequence in their fixed-length hidden states before producing any output. It is different from previous attentive models in that, instead of treating the attention weights as output of a deterministic function, our model assigns attention weights to a sequential latent variable which can be marginalized out and permits online generation. Experiments on abstractive sentence summarization and morphological inflection show significant performance gains over the baseline encoder-decoders.
Latent Predictor Networks for Code Generation
Jun 08, 2016
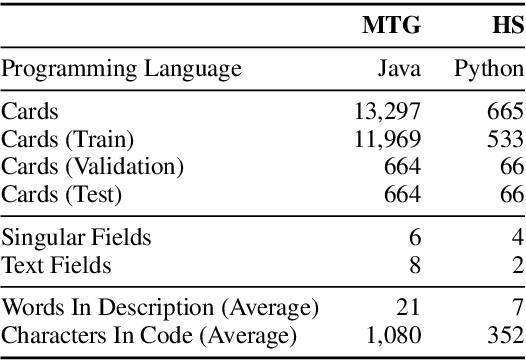


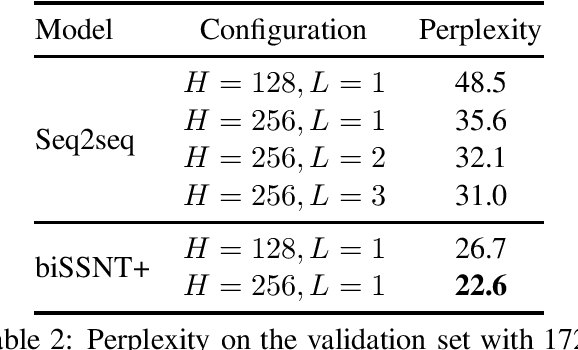
Many language generation tasks require the production of text conditioned on both structured and unstructured inputs. We present a novel neural network architecture which generates an output sequence conditioned on an arbitrary number of input functions. Crucially, our approach allows both the choice of conditioning context and the granularity of generation, for example characters or tokens, to be marginalised, thus permitting scalable and effective training. Using this framework, we address the problem of generating programming code from a mixed natural language and structured specification. We create two new data sets for this paradigm derived from the collectible trading card games Magic the Gathering and Hearthstone. On these, and a third preexisting corpus, we demonstrate that marginalising multiple predictors allows our model to outperform strong benchmarks.
Neural Variational Inference for Text Processing
Jun 04, 2016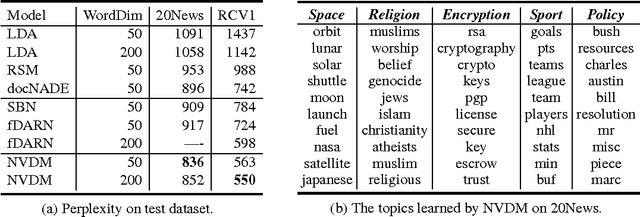
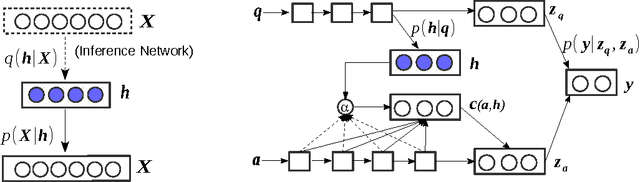
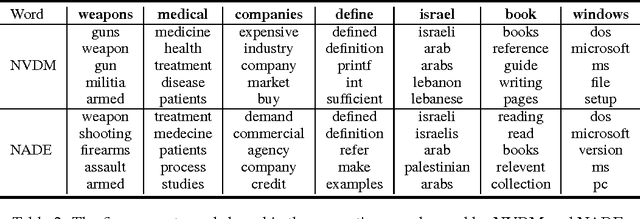
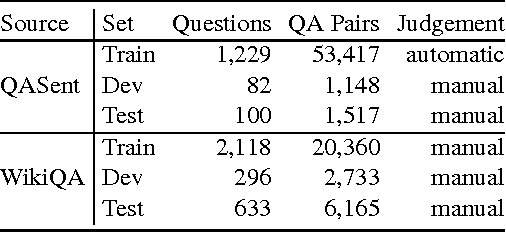
Recent advances in neural variational inference have spawned a renaissance in deep latent variable models. In this paper we introduce a generic variational inference framework for generative and conditional models of text. While traditional variational methods derive an analytic approximation for the intractable distributions over latent variables, here we construct an inference network conditioned on the discrete text input to provide the variational distribution. We validate this framework on two very different text modelling applications, generative document modelling and supervised question answering. Our neural variational document model combines a continuous stochastic document representation with a bag-of-words generative model and achieves the lowest reported perplexities on two standard test corpora. The neural answer selection model employs a stochastic representation layer within an attention mechanism to extract the semantics between a question and answer pair. On two question answering benchmarks this model exceeds all previous published benchmarks.
Optimizing Performance of Recurrent Neural Networks on GPUs
Apr 07, 2016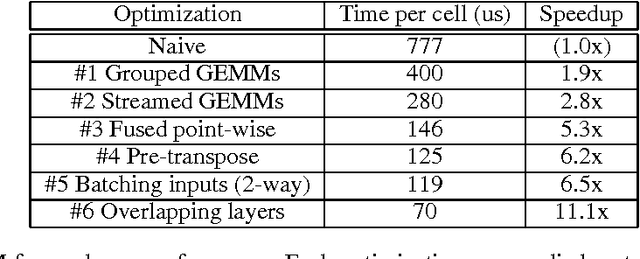
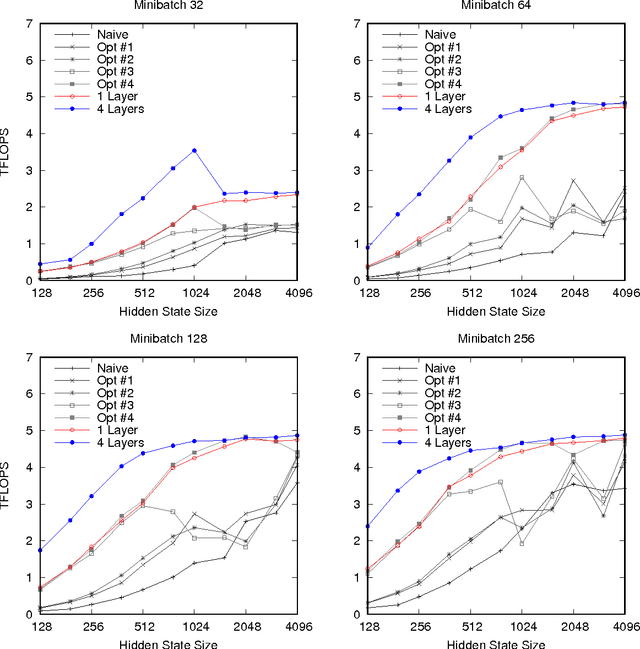
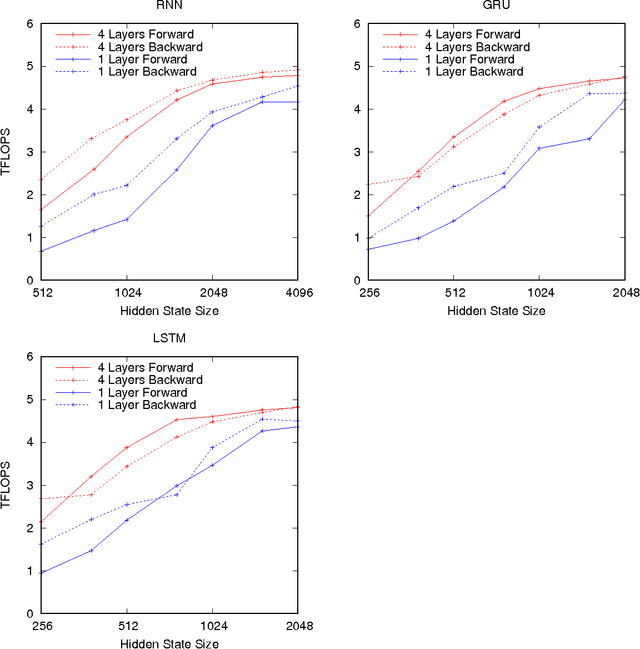
As recurrent neural networks become larger and deeper, training times for single networks are rising into weeks or even months. As such there is a significant incentive to improve the performance and scalability of these networks. While GPUs have become the hardware of choice for training and deploying recurrent models, the implementations employed often make use of only basic optimizations for these architectures. In this article we demonstrate that by exposing parallelism between operations within the network, an order of magnitude speedup across a range of network sizes can be achieved over a naive implementation. We describe three stages of optimization that have been incorporated into the fifth release of NVIDIA's cuDNN: firstly optimizing a single cell, secondly a single layer, and thirdly the entire network.
Reasoning about Entailment with Neural Attention
Mar 01, 2016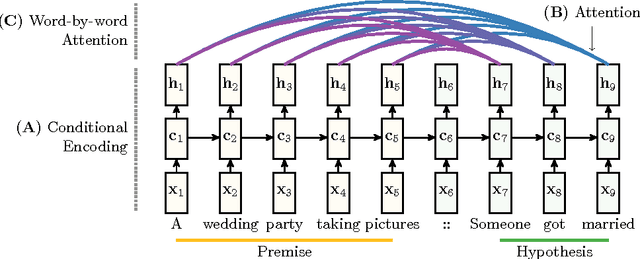
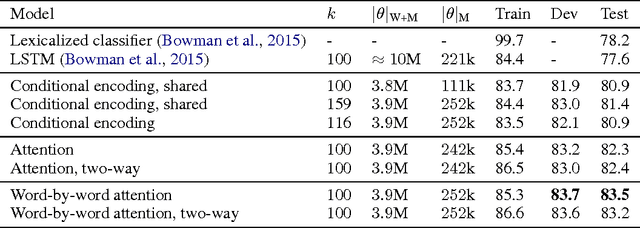
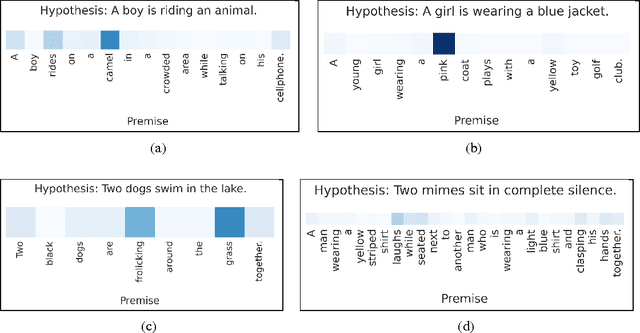
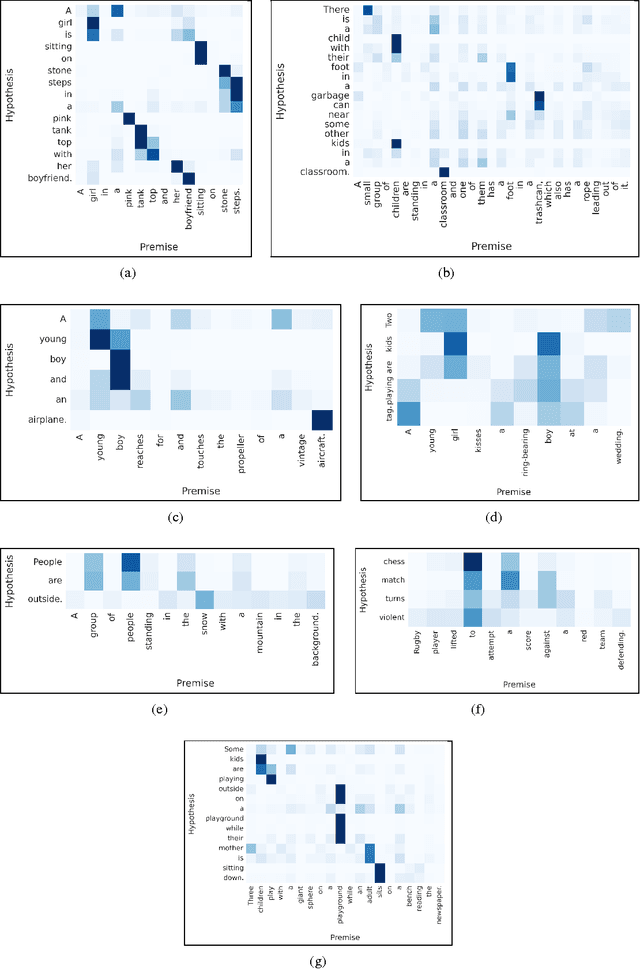
While most approaches to automatically recognizing entailment relations have used classifiers employing hand engineered features derived from complex natural language processing pipelines, in practice their performance has been only slightly better than bag-of-word pair classifiers using only lexical similarity. The only attempt so far to build an end-to-end differentiable neural network for entailment failed to outperform such a simple similarity classifier. In this paper, we propose a neural model that reads two sentences to determine entailment using long short-term memory units. We extend this model with a word-by-word neural attention mechanism that encourages reasoning over entailments of pairs of words and phrases. Furthermore, we present a qualitative analysis of attention weights produced by this model, demonstrating such reasoning capabilities. On a large entailment dataset this model outperforms the previous best neural model and a classifier with engineered features by a substantial margin. It is the first generic end-to-end differentiable system that achieves state-of-the-art accuracy on a textual entailment dataset.
Stochastic Collapsed Variational Inference for Sequential Data
Dec 05, 2015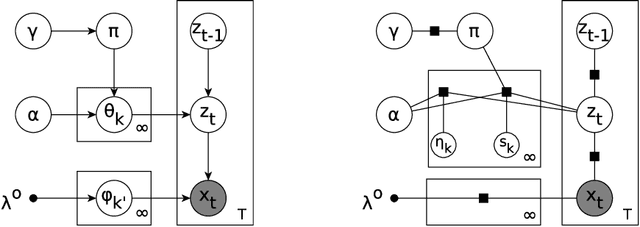
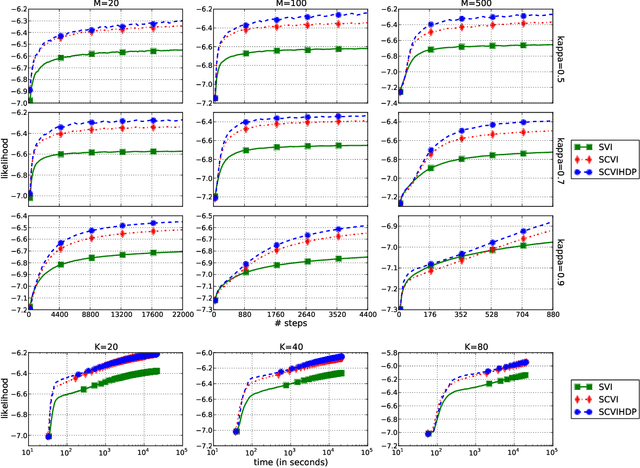
Stochastic variational inference for collapsed models has recently been successfully applied to large scale topic modelling. In this paper, we propose a stochastic collapsed variational inference algorithm in the sequential data setting. Our algorithm is applicable to both finite hidden Markov models and hierarchical Dirichlet process hidden Markov models, and to any datasets generated by emission distributions in the exponential family. Our experiment results on two discrete datasets show that our inference is both more efficient and more accurate than its uncollapsed version, stochastic variational inference.
Stochastic Collapsed Variational Inference for Hidden Markov Models
Dec 05, 2015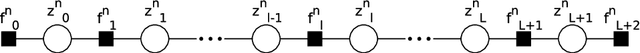
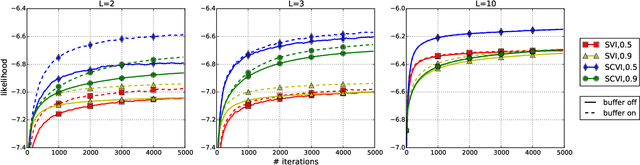
Stochastic variational inference for collapsed models has recently been successfully applied to large scale topic modelling. In this paper, we propose a stochastic collapsed variational inference algorithm for hidden Markov models, in a sequential data setting. Given a collapsed hidden Markov Model, we break its long Markov chain into a set of short subchains. We propose a novel sum-product algorithm to update the posteriors of the subchains, taking into account their boundary transitions due to the sequential dependencies. Our experiments on two discrete datasets show that our collapsed algorithm is scalable to very large datasets, memory efficient and significantly more accurate than the existing uncollapsed algorithm.
Teaching Machines to Read and Comprehend
Nov 19, 2015
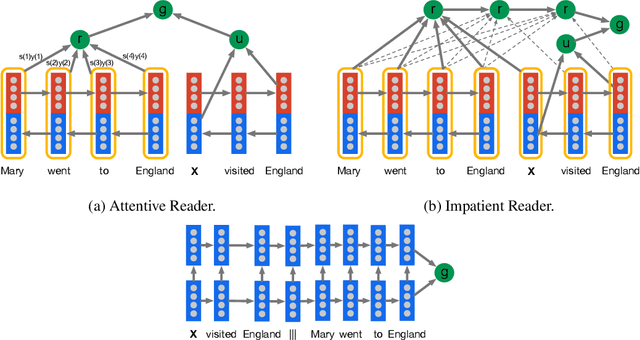
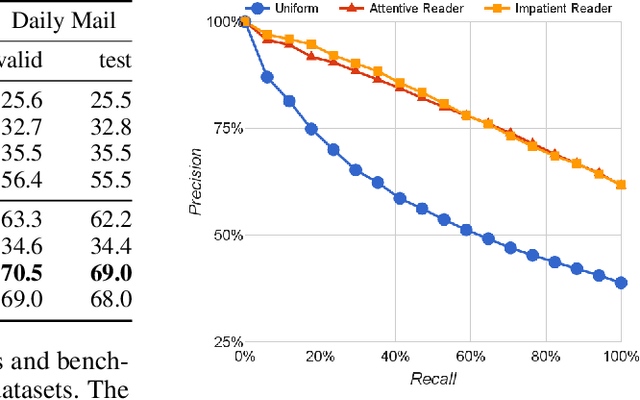

Teaching machines to read natural language documents remains an elusive challenge. Machine reading systems can be tested on their ability to answer questions posed on the contents of documents that they have seen, but until now large scale training and test datasets have been missing for this type of evaluation. In this work we define a new methodology that resolves this bottleneck and provides large scale supervised reading comprehension data. This allows us to develop a class of attention based deep neural networks that learn to read real documents and answer complex questions with minimal prior knowledge of language structure.