Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Using Pre-trained BERT Models for Vietnamese Relation Extraction Task at VLSP 2020
Paper and Code
Jan 28, 2021
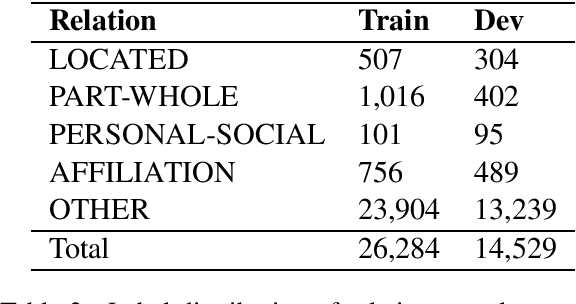


In this paper, we present an empirical study of using pre-trained BERT models for the relation extraction task at the VLSP 2020 Evaluation Campaign. We applied two state-of-the-art BERT-based models: R-BERT and BERT model with entity starts. For each model, we compared two pre-trained BERT models: FPTAI/vibert and NlpHUST/vibert4news. We found that NlpHUST/vibert4news model significantly outperforms FPTAI/vibert for the Vietnamese relation extraction task. Finally, we proposed an ensemble model that combines R-BERT and BERT with entity starts. Our proposed ensemble model slightly improved against two single models on the development data and the test data provided by the task organizers.
* 6 pages, VLSP 2020 Workshop, Camera Ready version
View paper on