 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing while preserving monotonicity in comparison-based preference learning models
Jun 10, 2025If you tell a learning model that you prefer an alternative $a$ over another alternative $b$, then you probably expect the model to be monotone, that is, the valuation of $a$ increases, and that of $b$ decreases. Yet, perhaps surprisingly, many widely deployed comparison-based preference learning models, including large language models, fail to have this guarantee. Until now, the only comparison-based preference learning algorithms that were proved to be monotone are the Generalized Bradley-Terry models. Yet, these models are unable to generalize to uncompared data. In this paper, we advance the understanding of the set of models with generalization ability that are monotone. Namely, we propose a new class of Linear Generalized Bradley-Terry models with Diffusion Priors, and identify sufficient conditions on alternatives' embeddings that guarantee monotonicity. Our experiments show that this monotonicity is far from being a general guarantee, and that our new class of generalizing models improves accuracy, especially when the dataset is limited.
Byzantine-Tolerant Machine Learning
Mar 08, 2017
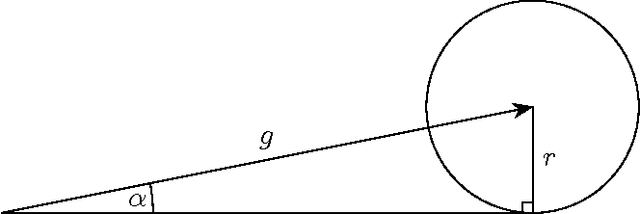
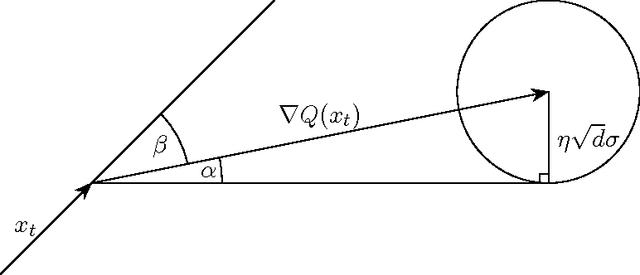
The growth of data, the need for scalability and the complexity of models used in modern machine learning calls for distributed implementations. Yet, as of today, distributed machine learning frameworks have largely ignored the possibility of arbitrary (i.e., Byzantine) failures. In this paper, we study the robustness to Byzantine failures at the fundamental level of stochastic gradient descent (SGD), the heart of most machine learning algorithms. Assuming a set of $n$ workers, up to $f$ of them being Byzantine, we ask how robust can SGD be, without limiting the dimension, nor the size of the parameter space. We first show that no gradient descent update rule based on a linear combination of the vectors proposed by the workers (i.e, current approaches) tolerates a single Byzantine failure. We then formulate a resilience property of the update rule capturing the basic requirements to guarantee convergence despite $f$ Byzantine workers. We finally propose Krum, an update rule that satisfies the resilience property aforementioned. For a $d$-dimensional learning problem, the time complexity of Krum is $O(n^2 \cdot (d + \log n))$.