 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Affective Representations of Music-Induced EEG through Multimodal Supervision and latent Domain Adaptation
Feb 20, 2022


The study of Music Cognition and neural responses to music has been invaluable in understanding human emotions. Brain signals, though, manifest a highly complex structure that makes processing and retrieving meaningful features challenging, particularly of abstract constructs like affect. Moreover, the performance of learning models is undermined by the limited amount of available neuronal data and their severe inter-subject variability. In this paper we extract efficient, personalized affective representations from EEG signals during music listening. To this end, we employ music signals as a supervisory modality to EEG, aiming to project their semantic correspondence onto a common representation space. We utilize a bi-modal framework by combining an LSTM-based attention model to process EEG and a pre-trained model for music tagging, along with a reverse domain discriminator to align the distributions of the two modalities, further constraining the learning process with emotion tags. The resulting framework can be utilized for emotion recognition both directly, by performing supervised predictions from either modality, and indirectly, by providing relevant music samples to EEG input queries. The experimental findings show the potential of enhancing neuronal data through stimulus information for recognition purposes and yield insights into the distribution and temporal variance of music-induced affective features.
Neural Emotion Director: Speech-preserving semantic control of facial expressions in "in-the-wild" videos
Dec 01, 2021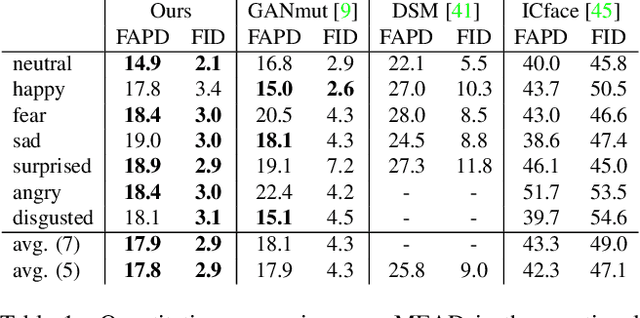
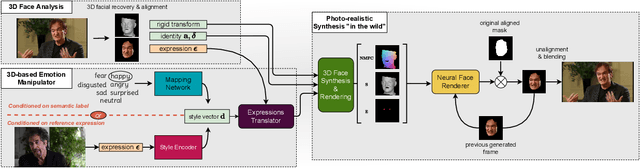


In this paper, we introduce a novel deep learning method for photo-realistic manipulation of the emotional state of actors in "in-the-wild" videos. The proposed method is based on a parametric 3D face representation of the actor in the input scene that offers a reliable disentanglement of the facial identity from the head pose and facial expressions. It then uses a novel deep domain translation framework that alters the facial expressions in a consistent and plausible manner, taking into account their dynamics. Finally, the altered facial expressions are used to photo-realistically manipulate the facial region in the input scene based on an especially-designed neural face renderer. To the best of our knowledge, our method is the first to be capable of controlling the actor's facial expressions by even using as a sole input the semantic labels of the manipulated emotions, while at the same time preserving the speech-related lip movements. We conduct extensive qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and the especially promising results that we obtain. Our method opens a plethora of new possibilities for useful applications of neural rendering technologies, ranging from movie post-production and video games to photo-realistic affective avatars.
An audiovisual and contextual approach for categorical and continuous emotion recognition in-the-wild
Jul 10, 2021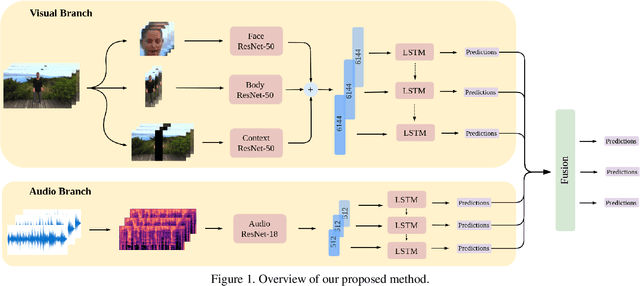
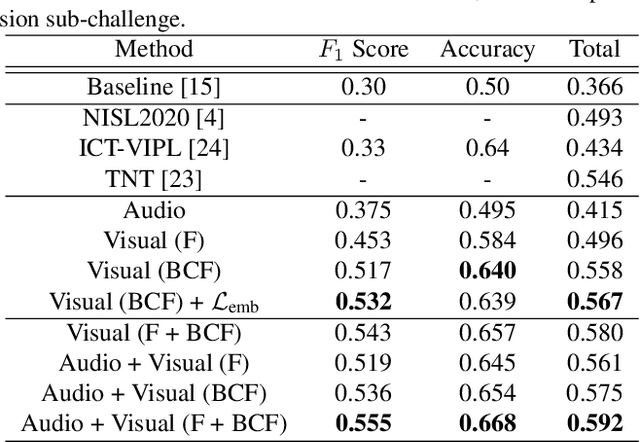
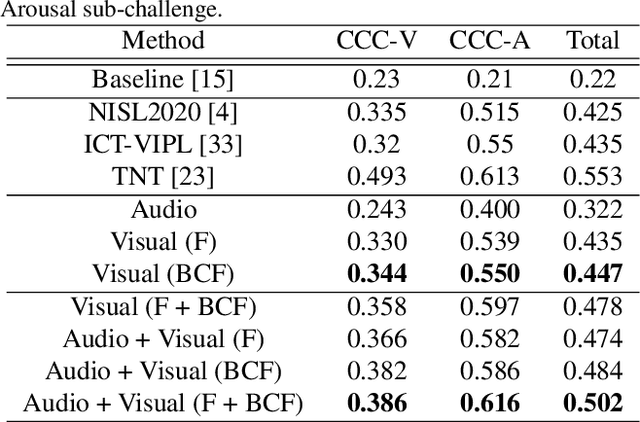
In this work we tackle the task of video-based audio-visual emotion recognition, within the premises of the 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Poor illumination conditions, head/body orientation and low image resolution constitute factors that can potentially hinder performance in case of methodologies that solely rely on the extraction and analysis of facial features. In order to alleviate this problem, we leverage bodily as well as contextual features, as part of a broader emotion recognition framework. We choose to use a standard CNN-RNN cascade as the backbone of our proposed model for sequence-to-sequence (seq2seq) learning. Apart from learning through the RGB input modality, we construct an aural stream which operates on sequences of extracted mel-spectrograms. Our extensive experiments on the challenging and newly assembled Affect-in-the-wild-2 (Aff-Wild2) dataset verify the superiority of our methods over existing approaches, while by properly incorporating all of the aforementioned modules in a network ensemble, we manage to surpass the previous best published recognition scores, in the official validation set. All the code was implemented using PyTorch\footnote{\url{https://pytorch.org/}} and is publicly available\footnote{\url{https://github.com/PanosAntoniadis/NTUA-ABAW2021}}.
Exploring Temporal Context and Human Movement Dynamics for Online Action Detection in Videos
Jun 26, 2021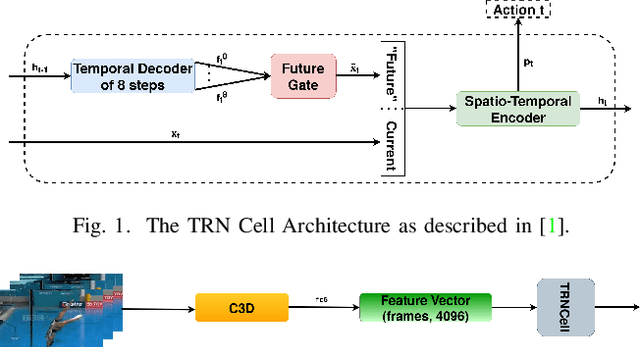
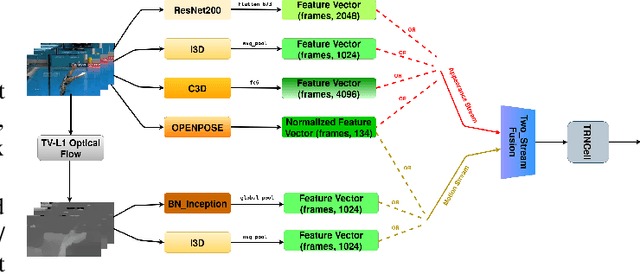
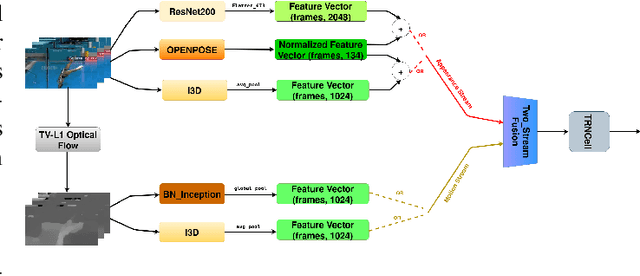

Nowadays, the interaction between humans and robots is constantly expanding, requiring more and more human motion recognition applications to operate in real time. However, most works on temporal action detection and recognition perform these tasks in offline manner, i.e. temporally segmented videos are classified as a whole. In this paper, based on the recently proposed framework of Temporal Recurrent Networks, we explore how temporal context and human movement dynamics can be effectively employed for online action detection. Our approach uses various state-of-the-art architectures and appropriately combines the extracted features in order to improve action detection. We evaluate our method on a challenging but widely used dataset for temporal action localization, THUMOS'14. Our experiments show significant improvement over the baseline method, achieving state-of-the art results on THUMOS'14.
Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition
Jun 07, 2021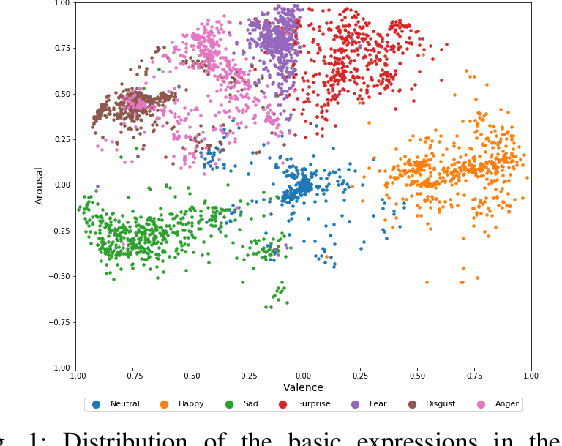
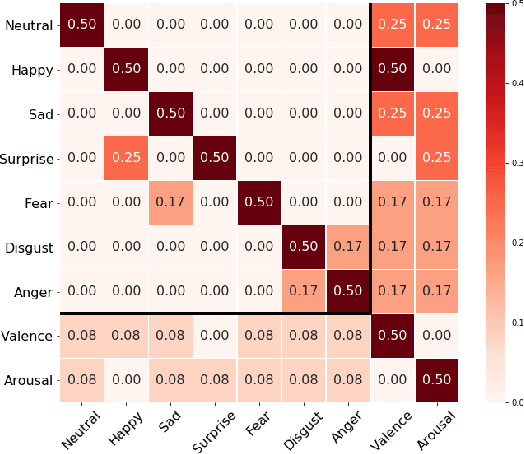
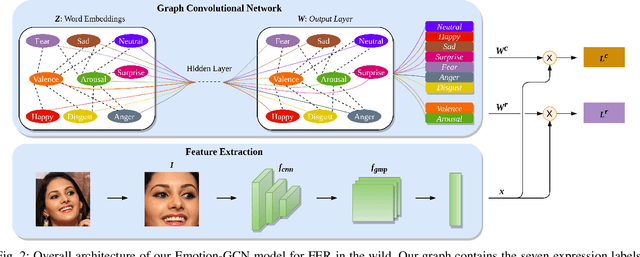
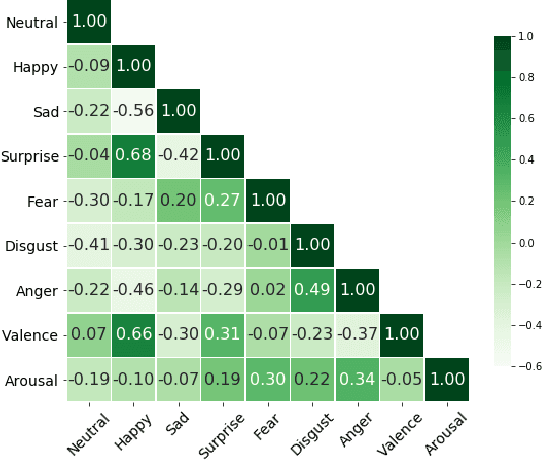
Over the past few years, deep learning methods have shown remarkable results in many face-related tasks including automatic facial expression recognition (FER) in-the-wild. Meanwhile, numerous models describing the human emotional states have been proposed by the psychology community. However, we have no clear evidence as to which representation is more appropriate and the majority of FER systems use either the categorical or the dimensional model of affect. Inspired by recent work in multi-label classification, this paper proposes a novel multi-task learning (MTL) framework that exploits the dependencies between these two models using a Graph Convolutional Network (GCN) to recognize facial expressions in-the-wild. Specifically, a shared feature representation is learned for both discrete and continuous recognition in a MTL setting. Moreover, the facial expression classifiers and the valence-arousal regressors are learned through a GCN that explicitly captures the dependencies between them. To evaluate the performance of our method under real-world conditions we train our models on AffectNet dataset. The results of our experiments show that our method outperforms the current state-of-the-art methods on discrete FER.
Leveraging Semantic Scene Characteristics and Multi-Stream Convolutional Architectures in a Contextual Approach for Video-Based Visual Emotion Recognition in the Wild
May 16, 2021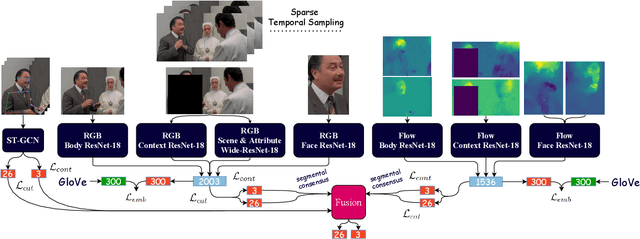

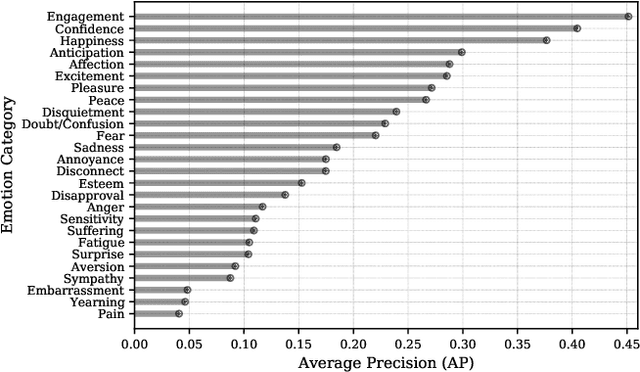
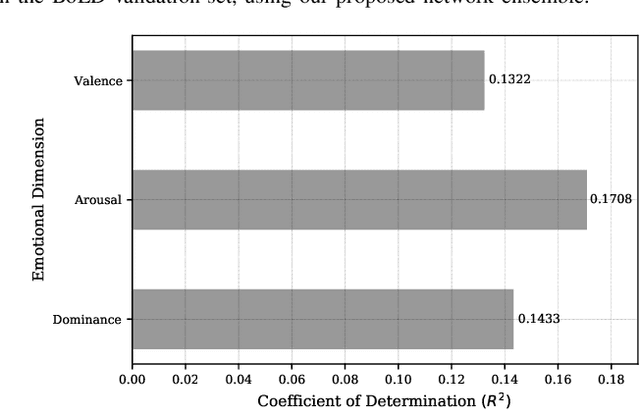
In this work we tackle the task of video-based visual emotion recognition in the wild. Standard methodologies that rely solely on the extraction of bodily and facial features often fall short of accurate emotion prediction in cases where the aforementioned sources of affective information are inaccessible due to head/body orientation, low resolution and poor illumination. We aspire to alleviate this problem by leveraging visual context in the form of scene characteristics and attributes, as part of a broader emotion recognition framework. Temporal Segment Networks (TSN) constitute the backbone of our proposed model. Apart from the RGB input modality, we make use of dense Optical Flow, following an intuitive multi-stream approach for a more effective encoding of motion. Furthermore, we shift our attention towards skeleton-based learning and leverage action-centric data as means of pre-training a Spatial-Temporal Graph Convolutional Network (ST-GCN) for the task of emotion recognition. Our extensive experiments on the challenging Body Language Dataset (BoLD) verify the superiority of our methods over existing approaches, while by properly incorporating all of the aforementioned modules in a network ensemble, we manage to surpass the previous best published recognition scores, by a large margin.
HTMD-Net: A Hybrid Masking-Denoising Approach to Time-Domain Monaural Singing Voice Separation
Mar 07, 2021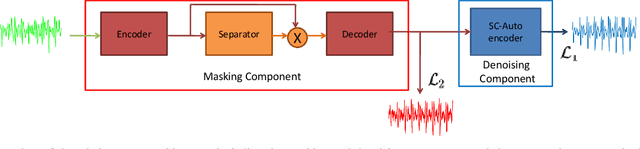
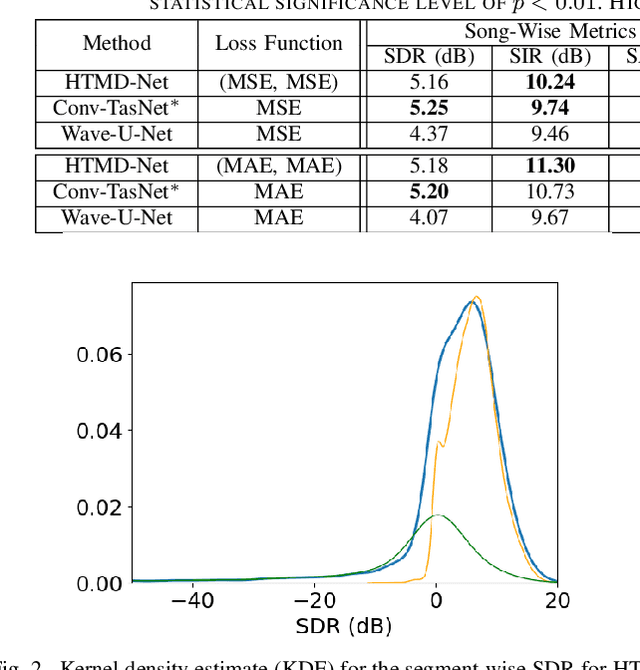
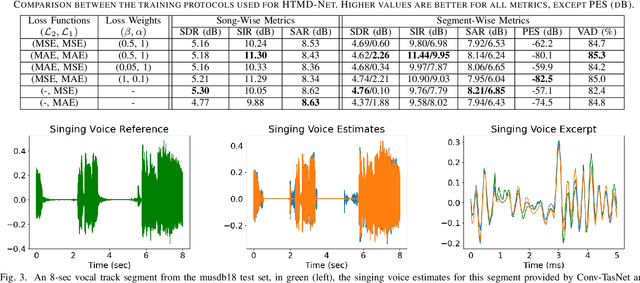

The advent of deep learning has led to the prevalence of deep neural network architectures for monaural music source separation, with end-to-end approaches that operate directly on the waveform level increasingly receiving research attention. Among these approaches, transformation of the input mixture to a learned latent space, and multiplicative application of a soft mask to the latent mixture, achieves the best performance, but is prone to the introduction of artifacts to the source estimate. To alleviate this problem, in this paper we propose a hybrid time-domain approach, termed the HTMD-Net, combining a lightweight masking component and a denoising module, based on skip connections, in order to refine the source estimated by the masking procedure. Evaluation of our approach in the task of monaural singing voice separation in the musdb18 dataset indicates that our proposed method achieves competitive performance compared to methods based purely on masking when trained under the same conditions, especially regarding the behavior during silent segments, while achieving higher computational efficiency.
Deep Convolutional and Recurrent Networks for Polyphonic Instrument Classification from Monophonic Raw Audio Waveforms
Feb 13, 2021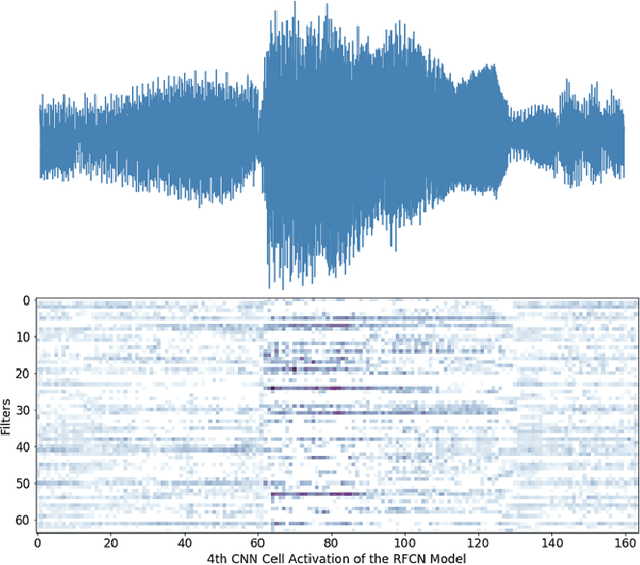
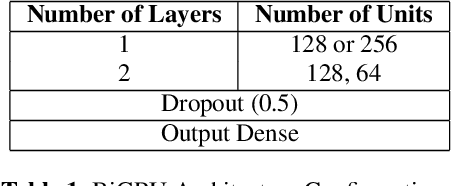
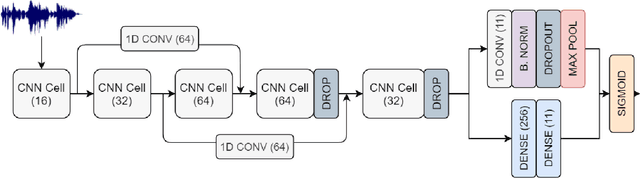

Sound Event Detection and Audio Classification tasks are traditionally addressed through time-frequency representations of audio signals such as spectrograms. However, the emergence of deep neural networks as efficient feature extractors has enabled the direct use of audio signals for classification purposes. In this paper, we attempt to recognize musical instruments in polyphonic audio by only feeding their raw waveforms into deep learning models. Various recurrent and convolutional architectures incorporating residual connections are examined and parameterized in order to build end-to-end classi-fiers with low computational cost and only minimal preprocessing. We obtain competitive classification scores and useful instrument-wise insight through the IRMAS test set, utilizing a parallel CNN-BiGRU model with multiple residual connections, while maintaining a significantly reduced number of trainable parameters.
Enhancing Handwritten Text Recognition with N-gram sequence decomposition and Multitask Learning
Dec 28, 2020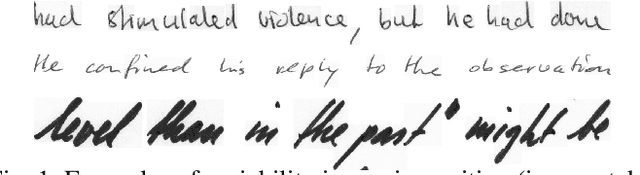
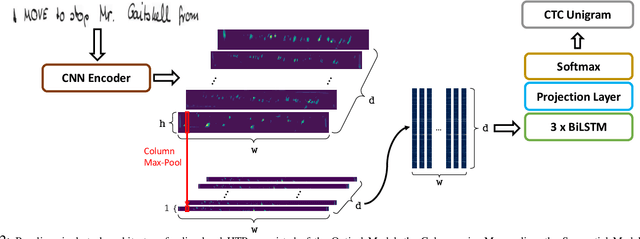
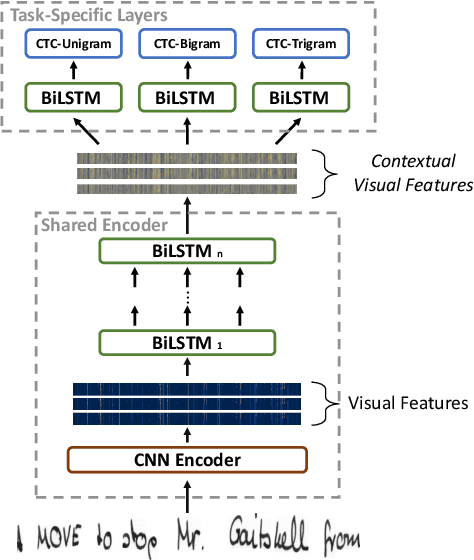
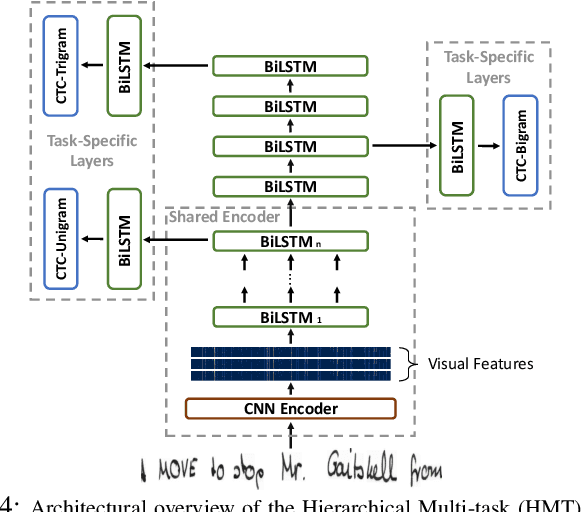
Current state-of-the-art approaches in the field of Handwritten Text Recognition are predominately single task with unigram, character level target units. In our work, we utilize a Multi-task Learning scheme, training the model to perform decompositions of the target sequence with target units of different granularity, from fine to coarse. We consider this method as a way to utilize n-gram information, implicitly, in the training process, while the final recognition is performed using only the unigram output. % in order to highlight the difference of the internal Unigram decoding of such a multi-task approach highlights the capability of the learned internal representations, imposed by the different n-grams at the training step. We select n-grams as our target units and we experiment from unigrams to fourgrams, namely subword level granularities. These multiple decompositions are learned from the network with task-specific CTC losses. Concerning network architectures, we propose two alternatives, namely the Hierarchical and the Block Multi-task. Overall, our proposed model, even though evaluated only on the unigram task, outperforms its counterpart single-task by absolute 2.52\% WER and 1.02\% CER, in the greedy decoding, without any computational overhead during inference, hinting towards successfully imposing an implicit language model.
Independent Sign Language Recognition with 3D Body, Hands, and Face Reconstruction
Nov 24, 2020
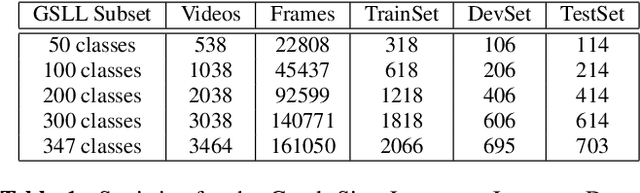
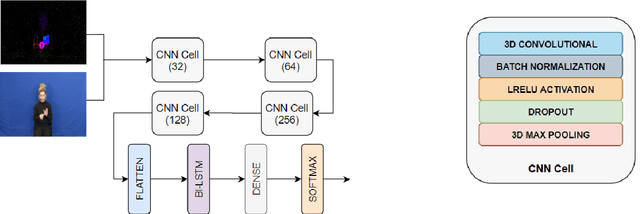

Independent Sign Language Recognition is a complex visual recognition problem that combines several challenging tasks of Computer Vision due to the necessity to exploit and fuse information from hand gestures, body features and facial expressions. While many state-of-the-art works have managed to deeply elaborate on these features independently, to the best of our knowledge, no work has adequately combined all three information channels to efficiently recognize Sign Language. In this work, we employ SMPL-X, a contemporary parametric model that enables joint extraction of 3D body shape, face and hands information from a single image. We use this holistic 3D reconstruction for SLR, demonstrating that it leads to higher accuracy than recognition from raw RGB images and their optical flow fed into the state-of-the-art I3D-type network for 3D action recognition and from 2D Openpose skeletons fed into a Recurrent Neural Network. Finally, a set of experiments on the body, face and hand features showed that neglecting any of these, significantly reduces the classification accuracy, proving the importance of jointly modeling body shape, facial expression and hand pose for Sign Language Recognition.