 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotorealistic and Identity-Preserving Image-Based Emotion Manipulation with Latent Diffusion Models
Aug 06, 2023



In this paper, we investigate the emotion manipulation capabilities of diffusion models with "in-the-wild" images, a rather unexplored application area relative to the vast and rapidly growing literature for image-to-image translation tasks. Our proposed method encapsulates several pieces of prior work, with the most important being Latent Diffusion models and text-driven manipulation with CLIP latents. We conduct extensive qualitative and quantitative evaluations on AffectNet, demonstrating the superiority of our approach in terms of image quality and realism, while achieving competitive results relative to emotion translation compared to a variety of GAN-based counterparts. Code is released as a publicly available repo.
Revisiting Tropical Polynomial Division: Theory, Algorithms and Application to Neural Networks
Jun 27, 2023Tropical geometry has recently found several applications in the analysis of neural networks with piecewise linear activation functions. This paper presents a new look at the problem of tropical polynomial division and its application to the simplification of neural networks. We analyze tropical polynomials with real coefficients, extending earlier ideas and methods developed for polynomials with integer coefficients. We first prove the existence of a unique quotient-remainder pair and characterize the quotient in terms of the convex bi-conjugate of a related function. Interestingly, the quotient of tropical polynomials with integer coefficients does not necessarily have integer coefficients. Furthermore, we develop a relationship of tropical polynomial division with the computation of the convex hull of unions of convex polyhedra and use it to derive an exact algorithm for tropical polynomial division. An approximate algorithm is also presented, based on an alternation between data partition and linear programming. We also develop special techniques to divide composite polynomials, described as sums or maxima of simpler ones. Finally, we present some numerical results to illustrate the efficiency of the algorithms proposed, using the MNIST handwritten digit and CIFAR-10 datasets.
ViDaS Video Depth-aware Saliency Network
May 19, 2023



We introduce ViDaS, a two-stream, fully convolutional Video, Depth-Aware Saliency network to address the problem of attention modeling ``in-the-wild", via saliency prediction in videos. Contrary to existing visual saliency approaches using only RGB frames as input, our network employs also depth as an additional modality. The network consists of two visual streams, one for the RGB frames, and one for the depth frames. Both streams follow an encoder-decoder approach and are fused to obtain a final saliency map. The network is trained end-to-end and is evaluated in a variety of different databases with eye-tracking data, containing a wide range of video content. Although the publicly available datasets do not contain depth, we estimate it using three different state-of-the-art methods, to enable comparisons and a deeper insight. Our method outperforms in most cases state-of-the-art models and our RGB-only variant, which indicates that depth can be beneficial to accurately estimating saliency in videos displayed on a 2D screen. Depth has been widely used to assist salient object detection problems, where it has been proven to be very beneficial. Our problem though differs significantly from salient object detection, since it is not restricted to specific salient objects, but predicts human attention in a more general aspect. These two problems not only have different objectives, but also different ground truth data and evaluation metrics. To our best knowledge, this is the first competitive deep learning video saliency estimation approach that combines both RGB and Depth features to address the general problem of saliency estimation ``in-the-wild". The code will be publicly released.
OVeNet: Offset Vector Network for Semantic Segmentation
Mar 25, 2023Semantic segmentation is a fundamental task in visual scene understanding. We focus on the supervised setting, where ground-truth semantic annotations are available. Based on knowledge about the high regularity of real-world scenes, we propose a method for improving class predictions by learning to selectively exploit information from neighboring pixels. In particular, our method is based on the prior that for each pixel, there is a seed pixel in its close neighborhood sharing the same prediction with the former. Motivated by this prior, we design a novel two-head network, named Offset Vector Network (OVeNet), which generates both standard semantic predictions and a dense 2D offset vector field indicating the offset from each pixel to the respective seed pixel, which is used to compute an alternative, seed-based semantic prediction. The two predictions are adaptively fused at each pixel using a learnt dense confidence map for the predicted offset vector field. We supervise offset vectors indirectly via optimizing the seed-based prediction and via a novel loss on the confidence map. Compared to the baseline state-of-the-art architectures HRNet and HRNet+OCR on which OVeNet is built, the latter achieves significant performance gains on two prominent benchmarks for semantic segmentation of driving scenes, namely Cityscapes and ACDC. Code is available at https://github.com/stamatisalex/OVeNet
Medical Face Masks and Emotion Recognition from the Body: Insights from a Deep Learning Perspective
Feb 20, 2023The COVID-19 pandemic has undoubtedly changed the standards and affected all aspects of our lives, especially social life. It has forced people to extensively wear medical face masks, in order to prevent transmission. This face occlusion can strongly irritate emotional reading from the face and urges us to incorporate the whole body for emotion recognition, as it needs to play a more major role, despite its complementary nature. In this paper, we want to conduct insightful studies about the effect of face occlusion on emotion recognition performance, and showcase the superiority of full body input over plain masked face. We utilize a deep learning model based on the Temporal Segment Network framework and aspire to fully overcome the consequences of the face mask. Although single RGB stream models can adapt and learn both facial and bodily features, this may lead to irrelevant information confusion. By processing those features separately and fusing their preliminary prediction scores with a late fusion scheme, we are more effectively taking advantage of both modalities. This architecture can also naturally support temporal modeling, by mingling information among neighboring segment frames. Experimental results suggest that spatial structure plays a more important role for an emotional expression, while temporal structure is complementary.
Multi-Source Contrastive Learning from Musical Audio
Feb 14, 2023Contrastive learning constitutes an emerging branch of self-supervised learning that leverages large amounts of unlabeled data, by learning a latent space, where pairs of different views of the same sample are associated. In this paper, we propose musical source association as a pair generation strategy in the context of contrastive music representation learning. To this end, we modify COLA, a widely used contrastive learning audio framework, to learn to associate a song excerpt with a stochastically selected and automatically extracted vocal or instrumental source. We further introduce a novel modification to the contrastive loss to incorporate information about the existence or absence of specific sources. Our experimental evaluation in three different downstream tasks (music auto-tagging, instrument classification and music genre classification) using the publicly available Magna-Tag-A-Tune (MTAT) as a source dataset yields competitive results to existing literature methods, as well as faster network convergence. The results also show that this pre-training method can be steered towards specific features, according to the selected musical source, while also being dependent on the quality of the separated sources.
VP-SLAM: A Monocular Real-time Visual SLAM with Points, Lines and Vanishing Points
Oct 28, 2022Traditional monocular Visual Simultaneous Localization and Mapping (vSLAM) systems can be divided into three categories: those that use features, those that rely on the image itself, and hybrid models. In the case of feature-based methods, new research has evolved to incorporate more information from their environment using geometric primitives beyond points, such as lines and planes. This is because in many environments, which are man-made environments, characterized as Manhattan world, geometric primitives such as lines and planes occupy most of the space in the environment. The exploitation of these schemes can lead to the introduction of algorithms capable of optimizing the trajectory of a Visual SLAM system and also helping to construct an exuberant map. Thus, we present a real-time monocular Visual SLAM system that incorporates real-time methods for line and VP extraction, as well as two strategies that exploit vanishing points to estimate the robot's translation and improve its rotation.Particularly, we build on ORB-SLAM2, which is considered the current state-of-the-art solution in terms of both accuracy and efficiency, and extend its formulation to handle lines and VPs to create two strategies the first optimize the rotation and the second refine the translation part from the known rotation. First, we extract VPs using a real-time method and use them for a global rotation optimization strategy. Second, we present a translation estimation method that takes advantage of last-stage rotation optimization to model a linear system. Finally, we evaluate our system on the TUM RGB-D benchmark and demonstrate that the proposed system achieves state-of-the-art results and runs in real time, and its performance remains close to the original ORB-SLAM2 system
3D Neural Sculpting (3DNS): Editing Neural Signed Distance Functions
Sep 28, 2022
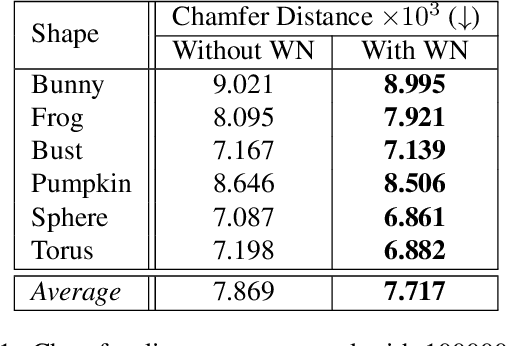
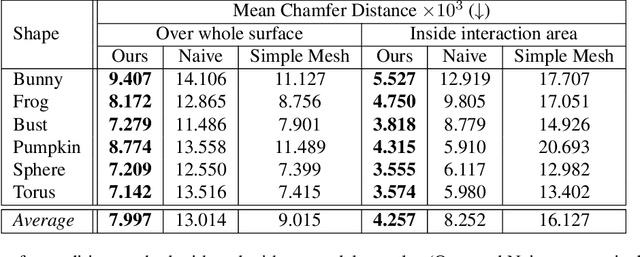
In recent years, implicit surface representations through neural networks that encode the signed distance have gained popularity and have achieved state-of-the-art results in various tasks (e.g. shape representation, shape reconstruction, and learning shape priors). However, in contrast to conventional shape representations such as polygon meshes, the implicit representations cannot be easily edited and existing works that attempt to address this problem are extremely limited. In this work, we propose the first method for efficient interactive editing of signed distance functions expressed through neural networks, allowing free-form editing. Inspired by 3D sculpting software for meshes, we use a brush-based framework that is intuitive and can in the future be used by sculptors and digital artists. In order to localize the desired surface deformations, we regulate the network by using a copy of it to sample the previously expressed surface. We introduce a novel framework for simulating sculpting-style surface edits, in conjunction with interactive surface sampling and efficient adaptation of network weights. We qualitatively and quantitatively evaluate our method in various different 3D objects and under many different edits. The reported results clearly show that our method yields high accuracy, in terms of achieving the desired edits, while at the same time preserving the geometry outside the interaction areas.
Neural Sign Reenactor: Deep Photorealistic Sign Language Retargeting
Sep 03, 2022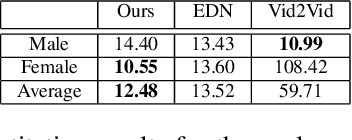
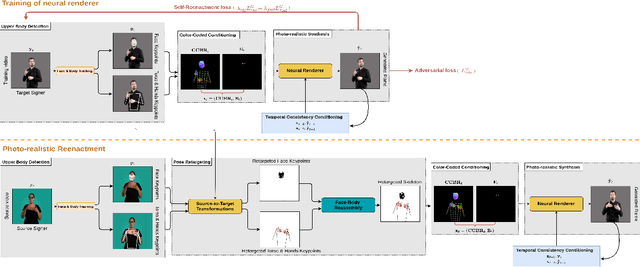

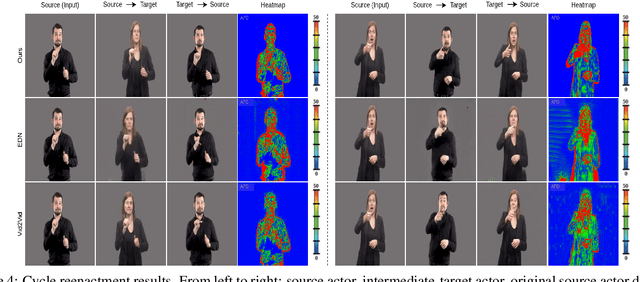
In this paper, we introduce a neural rendering pipeline for transferring the facial expressions, head pose and body movements of one person in a source video to another in a target video. We apply our method to the challenging case of Sign Language videos: given a source video of a sign language user, we can faithfully transfer the performed manual (e.g. handshape, palm orientation, movement, location) and non-manual (e.g. eye gaze, facial expressions, head movements) signs to a target video in a photo-realistic manner. To effectively capture the aforementioned cues, which are crucial for sign language communication, we build upon an effective combination of the most robust and reliable deep learning methods for body, hand and face tracking that have been introduced lately. Using a 3D-aware representation, the estimated motions of the body parts are combined and retargeted to the target signer. They are then given as conditional input to our Video Rendering Network, which generates temporally consistent and photo-realistic videos. We conduct detailed qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and its advantages over existing approaches. Our method yields promising results of unprecedented realism and can be used for Sign Language Anonymization. In addition, it can be readily applicable to reenactment of other types of full body activities (dancing, acting performance, exercising, etc.), as well as to the synthesis module of Sign Language Production systems.
Visual Speech-Aware Perceptual 3D Facial Expression Reconstruction from Videos
Jul 22, 2022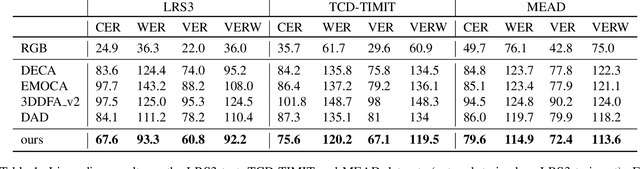
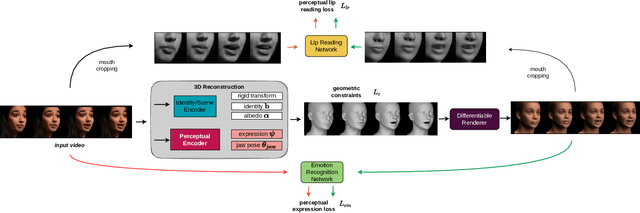


The recent state of the art on monocular 3D face reconstruction from image data has made some impressive advancements, thanks to the advent of Deep Learning. However, it has mostly focused on input coming from a single RGB image, overlooking the following important factors: a) Nowadays, the vast majority of facial image data of interest do not originate from single images but rather from videos, which contain rich dynamic information. b) Furthermore, these videos typically capture individuals in some form of verbal communication (public talks, teleconferences, audiovisual human-computer interactions, interviews, monologues/dialogues in movies, etc). When existing 3D face reconstruction methods are applied in such videos, the artifacts in the reconstruction of the shape and motion of the mouth area are often severe, since they do not match well with the speech audio. To overcome the aforementioned limitations, we present the first method for visual speech-aware perceptual reconstruction of 3D mouth expressions. We do this by proposing a "lipread" loss, which guides the fitting process so that the elicited perception from the 3D reconstructed talking head resembles that of the original video footage. We demonstrate that, interestingly, the lipread loss is better suited for 3D reconstruction of mouth movements compared to traditional landmark losses, and even direct 3D supervision. Furthermore, the devised method does not rely on any text transcriptions or corresponding audio, rendering it ideal for training in unlabeled datasets. We verify the efficiency of our method through exhaustive objective evaluations on three large-scale datasets, as well as subjective evaluation with two web-based user studies.