 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Augmented Neural Networks for Patient Note De-identification
Oct 30, 2016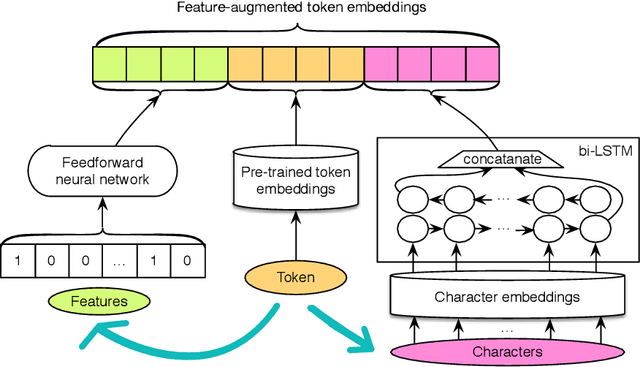


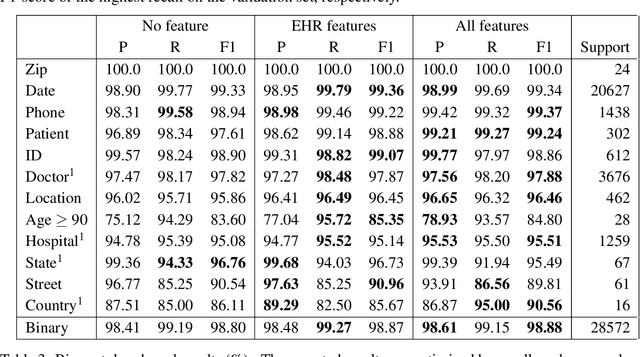
Patient notes contain a wealth of information of potentially great interest to medical investigators. However, to protect patients' privacy, Protected Health Information (PHI) must be removed from the patient notes before they can be legally released, a process known as patient note de-identification. The main objective for a de-identification system is to have the highest possible recall. Recently, the first neural-network-based de-identification system has been proposed, yielding state-of-the-art results. Unlike other systems, it does not rely on human-engineered features, which allows it to be quickly deployed, but does not leverage knowledge from human experts or from electronic health records (EHRs). In this work, we explore a method to incorporate human-engineered features as well as features derived from EHRs to a neural-network-based de-identification system. Our results show that the addition of features, especially the EHR-derived features, further improves the state-of-the-art in patient note de-identification, including for some of the most sensitive PHI types such as patient names. Since in a real-life setting patient notes typically come with EHRs, we recommend developers of de-identification systems to leverage the information EHRs contain.
De-identification of Patient Notes with Recurrent Neural Networks
Jun 10, 2016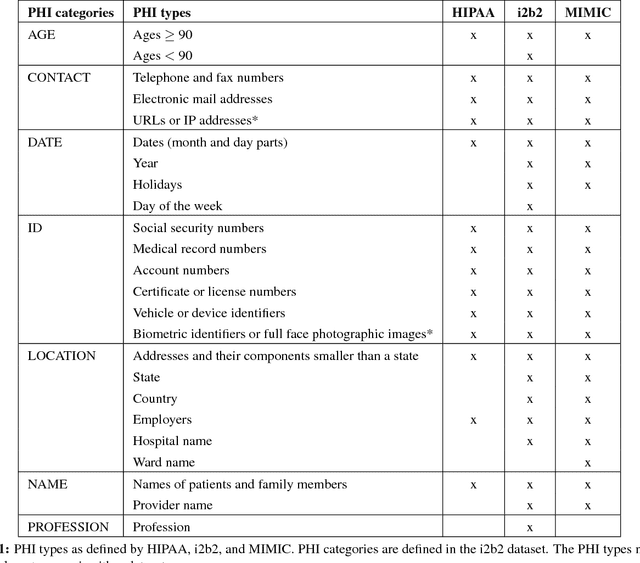
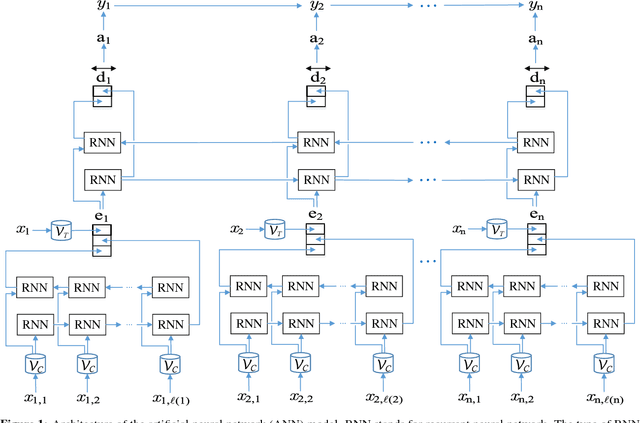
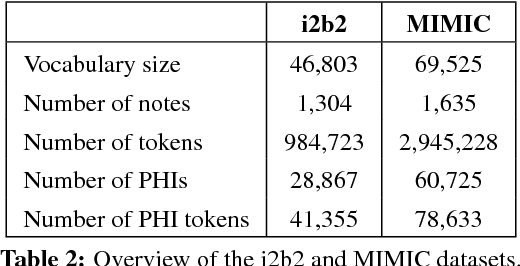
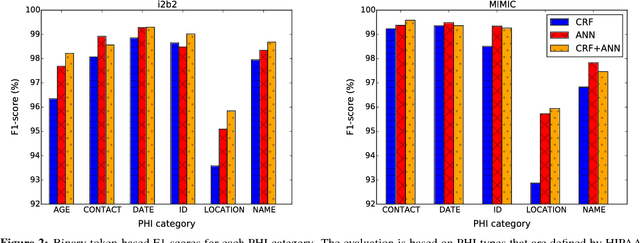
Objective: Patient notes in electronic health records (EHRs) may contain critical information for medical investigations. However, the vast majority of medical investigators can only access de-identified notes, in order to protect the confidentiality of patients. In the United States, the Health Insurance Portability and Accountability Act (HIPAA) defines 18 types of protected health information (PHI) that needs to be removed to de-identify patient notes. Manual de-identification is impractical given the size of EHR databases, the limited number of researchers with access to the non-de-identified notes, and the frequent mistakes of human annotators. A reliable automated de-identification system would consequently be of high value. Materials and Methods: We introduce the first de-identification system based on artificial neural networks (ANNs), which requires no handcrafted features or rules, unlike existing systems. We compare the performance of the system with state-of-the-art systems on two datasets: the i2b2 2014 de-identification challenge dataset, which is the largest publicly available de-identification dataset, and the MIMIC de-identification dataset, which we assembled and is twice as large as the i2b2 2014 dataset. Results: Our ANN model outperforms the state-of-the-art systems. It yields an F1-score of 97.85 on the i2b2 2014 dataset, with a recall 97.38 and a precision of 97.32, and an F1-score of 99.23 on the MIMIC de-identification dataset, with a recall 99.25 and a precision of 99.06. Conclusion: Our findings support the use of ANNs for de-identification of patient notes, as they show better performance than previously published systems while requiring no feature engineering.
Global Conditioning for Probabilistic Inference in Belief Networks
Feb 27, 2013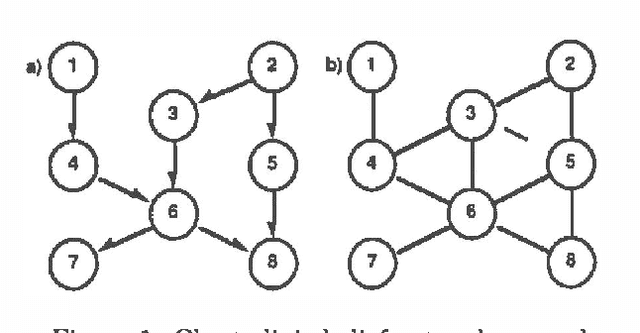
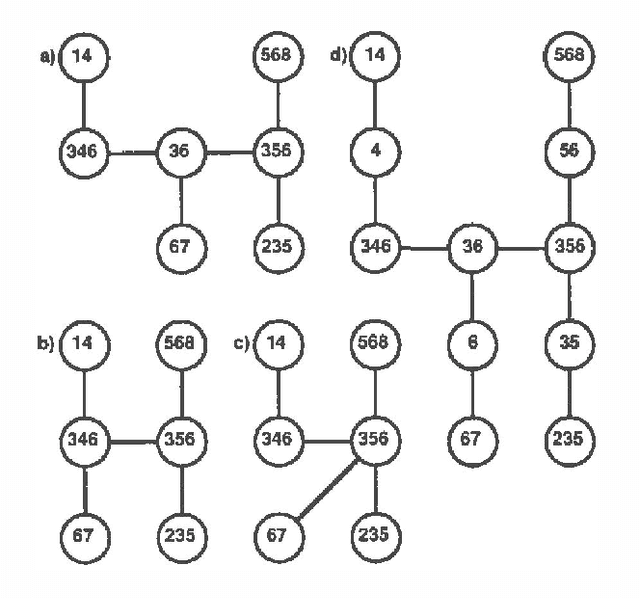
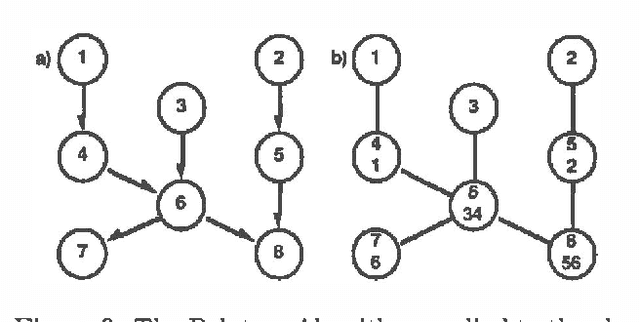
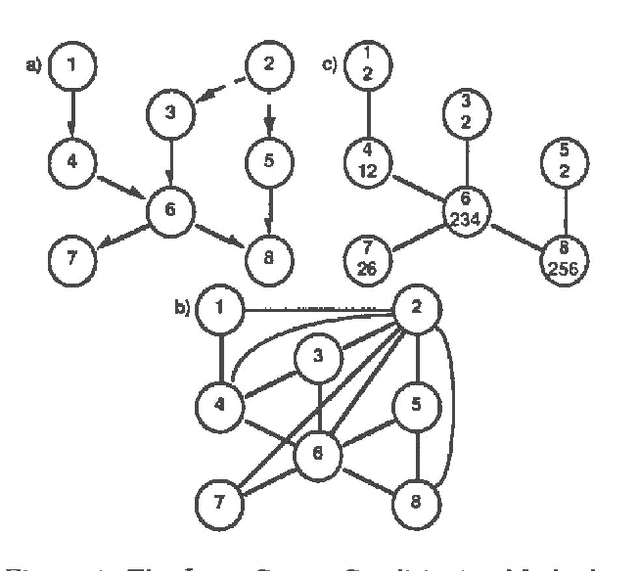
In this paper we propose a new approach to probabilistic inference on belief networks, global conditioning, which is a simple generalization of Pearl's (1986b) method of loopcutset conditioning. We show that global conditioning, as well as loop-cutset conditioning, can be thought of as a special case of the method of Lauritzen and Spiegelhalter (1988) as refined by Jensen et al (199Oa; 1990b). Nonetheless, this approach provides new opportunities for parallel processing and, in the case of sequential processing, a tradeoff of time for memory. We also show how a hybrid method (Suermondt and others 1990) combining loop-cutset conditioning with Jensen's method can be viewed within our framework. By exploring the relationships between these methods, we develop a unifying framework in which the advantages of each approach can be combined successfully.