 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Cooperative Decision Making in Multi-agent Multi-armed Bandits
Mar 03, 2020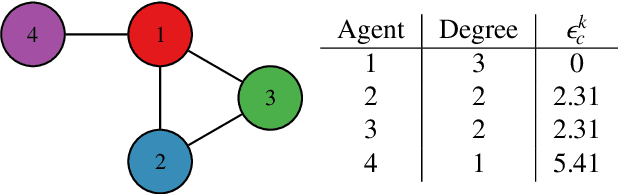
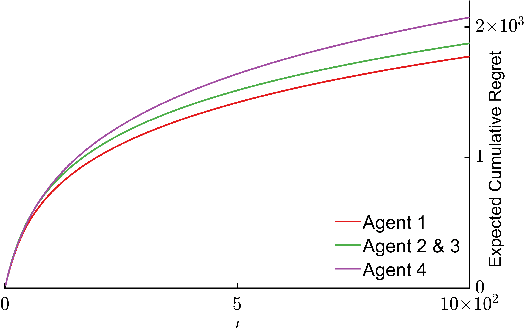
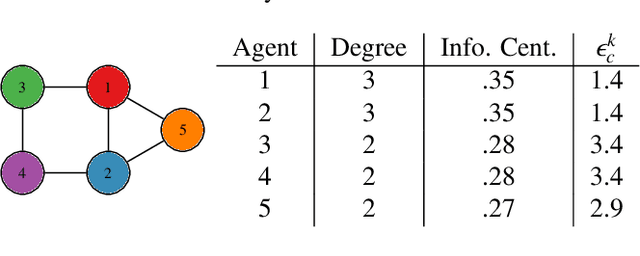
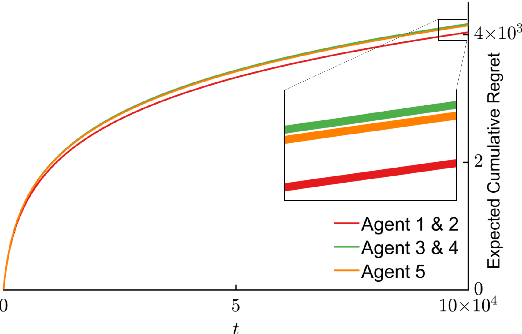
We study a distributed decision-making problem in which multiple agents face the same multi-armed bandit (MAB), and each agent makes sequential choices among arms to maximize its own individual reward. The agents cooperate by sharing their estimates over a fixed communication graph. We consider an unconstrained reward model in which two or more agents can choose the same arm and collect independent rewards. And we consider a constrained reward model in which agents that choose the same arm at the same time receive no reward. We design a dynamic, consensus-based, distributed estimation algorithm for cooperative estimation of mean rewards at each arm. We leverage the estimates from this algorithm to develop two distributed algorithms: coop-UCB2 and coop-UCB2-selective-learning, for the unconstrained and constrained reward models, respectively. We show that both algorithms achieve group performance close to the performance of a centralized fusion center. Further, we investigate the influence of the communication graph structure on performance. We propose a novel graph explore-exploit index that predicts the relative performance of groups in terms of the communication graph, and we propose a novel nodal explore-exploit centrality index that predicts the relative performance of agents in terms of the agent locations in the communication graph.
Distributed Cooperative Decision-Making in Multiarmed Bandits: Frequentist and Bayesian Algorithms
Sep 24, 2016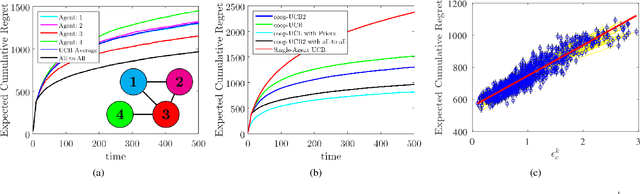
We study distributed cooperative decision-making under the explore-exploit tradeoff in the multiarmed bandit (MAB) problem. We extend the state-of-the-art frequentist and Bayesian algorithms for single-agent MAB problems to cooperative distributed algorithms for multi-agent MAB problems in which agents communicate according to a fixed network graph. We rely on a running consensus algorithm for each agent's estimation of mean rewards from its own rewards and the estimated rewards of its neighbors. We prove the performance of these algorithms and show that they asymptotically recover the performance of a centralized agent. Further, we rigorously characterize the influence of the communication graph structure on the decision-making performance of the group.
On Distributed Cooperative Decision-Making in Multiarmed Bandits
May 16, 2016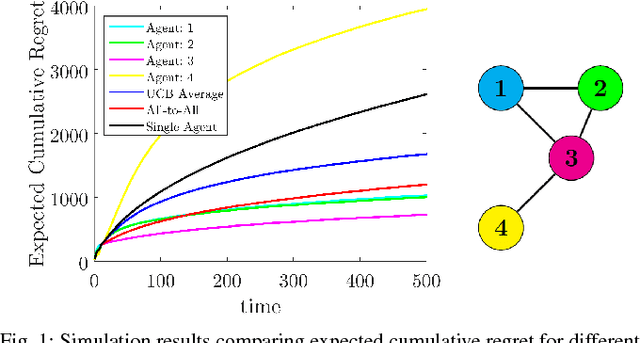
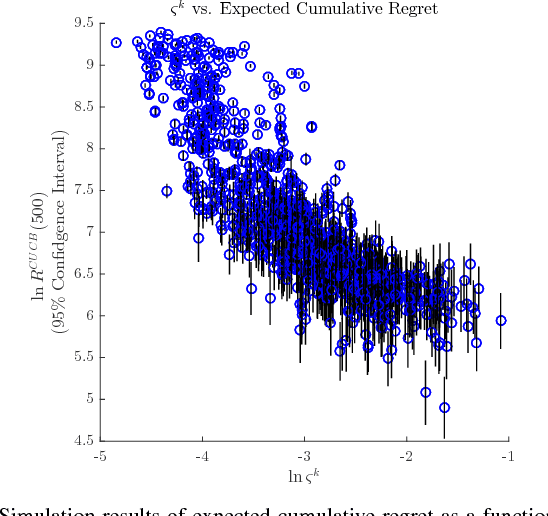

We study the explore-exploit tradeoff in distributed cooperative decision-making using the context of the multiarmed bandit (MAB) problem. For the distributed cooperative MAB problem, we design the cooperative UCB algorithm that comprises two interleaved distributed processes: (i) running consensus algorithms for estimation of rewards, and (ii) upper-confidence-bound-based heuristics for selection of arms. We rigorously analyze the performance of the cooperative UCB algorithm and characterize the influence of communication graph structure on the decision-making performance of the group.