 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Vulnerability of Backdoor Defenses for Federated Learning
Jan 19, 2023Federated Learning (FL) is a popular distributed machine learning paradigm that enables jointly training a global model without sharing clients' data. However, its repetitive server-client communication gives room for backdoor attacks with aim to mislead the global model into a targeted misprediction when a specific trigger pattern is presented. In response to such backdoor threats on federated learning, various defense measures have been proposed. In this paper, we study whether the current defense mechanisms truly neutralize the backdoor threats from federated learning in a practical setting by proposing a new federated backdoor attack method for possible countermeasures. Different from traditional training (on triggered data) and rescaling (the malicious client model) based backdoor injection, the proposed backdoor attack framework (1) directly modifies (a small proportion of) local model weights to inject the backdoor trigger via sign flips; (2) jointly optimize the trigger pattern with the client model, thus is more persistent and stealthy for circumventing existing defenses. In a case study, we examine the strength and weaknesses of recent federated backdoor defenses from three major categories and provide suggestions to the practitioners when training federated models in practice.
Loss Tolerant Federated Learning
May 08, 2021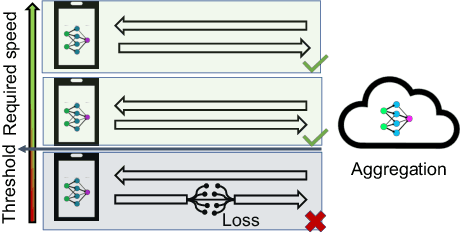
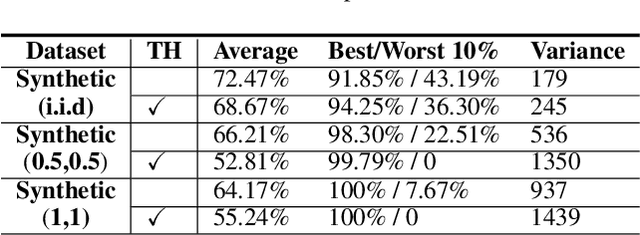
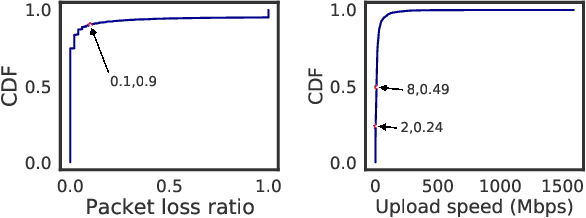
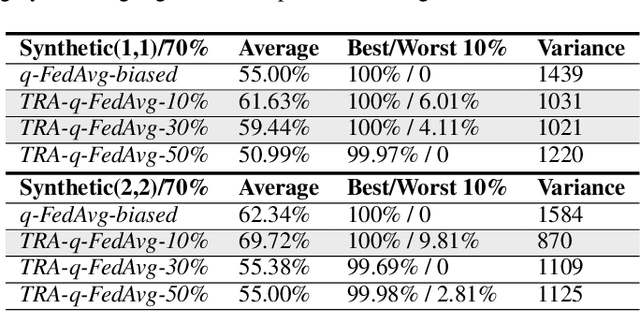
Federated learning has attracted attention in recent years for collaboratively training data on distributed devices with privacy-preservation. The limited network capacity of mobile and IoT devices has been seen as one of the major challenges for cross-device federated learning. Recent solutions have been focusing on threshold-based client selection schemes to guarantee the communication efficiency. However, we find this approach can cause biased client selection and results in deteriorated performance. Moreover, we find that the challenge of network limit may be overstated in some cases and the packet loss is not always harmful. In this paper, we explore the loss tolerant federated learning (LT-FL) in terms of aggregation, fairness, and personalization. We use ThrowRightAway (TRA) to accelerate the data uploading for low-bandwidth-devices by intentionally ignoring some packet losses. The results suggest that, with proper integration, TRA and other algorithms can together guarantee the personalization and fairness performance in the face of packet loss below a certain fraction (10%-30%).
FLFE: A Communication-Efficient and Privacy-Preserving Federated Feature Engineering Framework
Sep 05, 2020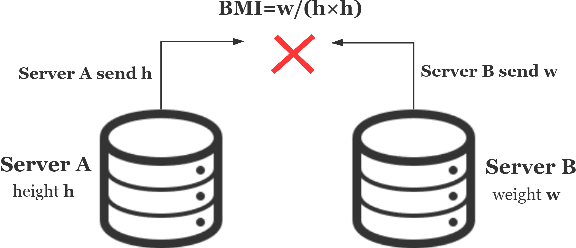
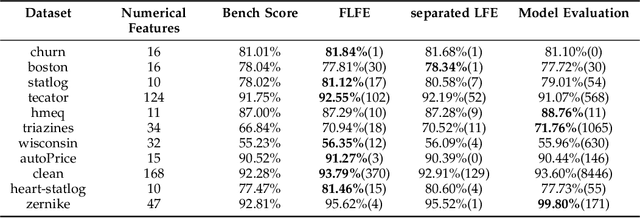


Feature engineering is the process of using domain knowledge to extract features from raw data via data mining techniques and is a key step to improve the performance of machine learning algorithms. In the multi-party feature engineering scenario (features are stored in many different IoT devices), direct and unlimited multivariate feature transformations will quickly exhaust memory, power, and bandwidth of devices, not to mention the security of information threatened. Given this, we present a framework called FLFE to conduct privacy-preserving and communication-preserving multi-party feature transformations. The framework pre-learns the pattern of the feature to directly judge the usefulness of the transformation on a feature. Explored the new useful feature, the framework forsakes the encryption-based algorithm for the well-designed feature exchange mechanism, which largely decreases the communication overhead under the premise of confidentiality. We made experiments on datasets of both open-sourced and real-world thus validating the comparable effectiveness of FLFE to evaluation-based approaches, along with the far more superior efficacy.