 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-RL with Shared Representations Enables Fast Adaptation in Energy Systems
Mar 09, 2026Meta-Reinforcement Learning addresses the critical limitations of conventional Reinforcement Learning in multi-task and non-stationary environments by enabling fast policy adaptation and improved generalization. We introduce a novel Meta-RL framework that integrates a bi-level optimization scheme with a hybrid actor-critic architecture specially designed to enhance sample efficiency and inter-task adaptability. To improve knowledge transfer, we meta-learn a shared state feature extractor jointly optimized across actor and critic networks, providing efficient representation learning and limiting overfitting to individual tasks or dominant profiles. Additionally, we propose a parameter-sharing mechanism between the outer- and inner-loop actor networks, to reduce redundant learning and accelerate adaptation during task revisitation. The approach is validated on a real-world Building Energy Management Systems dataset covering nearly a decade of temporal and structural variability, for which we propose a task preparation method to promote generalization. Experiments demonstrate effective task adaptation and better performance compared to conventional RL and Meta-RL methods.
Selecting Offline Reinforcement Learning Algorithms for Stochastic Network Control
Mar 04, 2026Offline Reinforcement Learning (RL) is a promising approach for next-generation wireless networks, where online exploration is unsafe and large amounts of operational data can be reused across the model lifecycle. However, the behavior of offline RL algorithms under genuinely stochastic dynamics -- inherent to wireless systems due to fading, noise, and traffic mobility -- remains insufficiently understood. We address this gap by evaluating Bellman-based (Conservative Q-Learning), sequence-based (Decision Transformers), and hybrid (Critic-Guided Decision Transformers) offline RL methods in an open-access stochastic telecom environment (mobile-env). Our results show that Conservative Q-Learning consistently produces more robust policies across different sources of stochasticity, making it a reliable default choice in lifecycle-driven AI management frameworks. Sequence-based methods remain competitive and can outperform Bellman-based approaches when sufficient high-return trajectories are available. These findings provide practical guidance for offline RL algorithm selection in AI-driven network control pipelines, such as O-RAN and future 6G functions, where robustness and data availability are key operational constraints.
Affinity-Based Hierarchical Learning of Dependent Concepts for Human Activity Recognition
Apr 11, 2021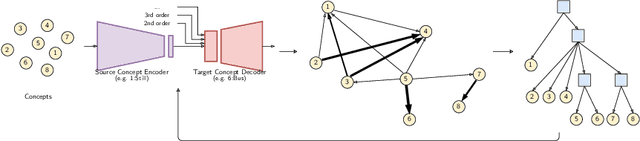
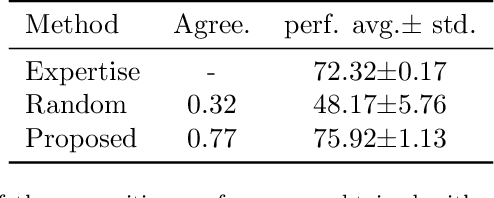
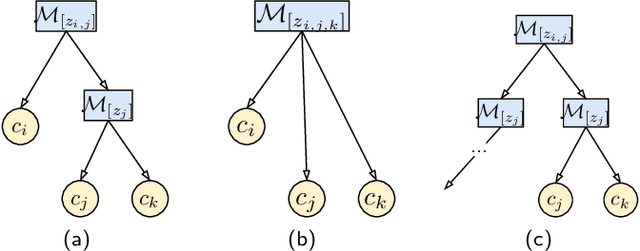
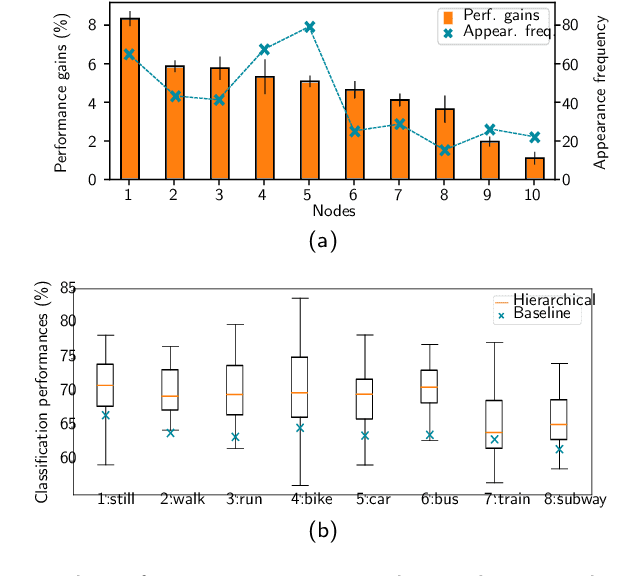
In multi-class classification tasks, like human activity recognition, it is often assumed that classes are separable. In real applications, this assumption becomes strong and generates inconsistencies. Besides, the most commonly used approach is to learn classes one-by-one against the others. This computational simplification principle introduces strong inductive biases on the learned theories. In fact, the natural connections among some classes, and not others, deserve to be taken into account. In this paper, we show that the organization of overlapping classes (multiple inheritances) into hierarchies considerably improves classification performances. This is particularly true in the case of activity recognition tasks featured in the SHL dataset. After theoretically showing the exponential complexity of possible class hierarchies, we propose an approach based on transfer affinity among the classes to determine an optimal hierarchy for the learning process. Extensive experiments show improved performances and a reduction in the number of examples needed to learn.