 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Machine Learning: Theory for Learning Under Variable Regimes
Mar 24, 2026We study learning under regime variation, where the learner, its memory state, and the evaluative conditions may evolve over time. This paper is a foundational and structural contribution: its goal is to define the core learning-theoretic objects required for such settings and to establish their first theorem-supporting consequences. The paper develops a regime-varying framework centered on admissible transport, protected-core preservation, and evaluator-aware learning evolution. It records the immediate closure consequences of admissibility, develops a structural obstruction argument for faithful fixed-ontology reduction in genuinely multi-regime settings, and introduces a protected-stability template together with explicit numerical and symbolic witnesses on controlled subclasses, including convex and deductive settings. It also establishes theorem-layer results on evaluator factorization, morphisms, composition, and partial kernel-level alignment across semantically commensurable layers. A worked two-regime example makes the admissibility certificate, protected evaluative core, and regime-variation cost explicit on a controlled subclass. The symbolic component is deliberately restricted in scope: the paper establishes a first kernel-level compatibility result together with a controlled monotonic deductive witness. The manuscript should therefore be read as introducing a structured learning-theoretic framework for regime-varying learning together with its first theorem-supporting layer, not as a complete quantitative theory of all learning systems.
Meta-RL with Shared Representations Enables Fast Adaptation in Energy Systems
Mar 09, 2026Meta-Reinforcement Learning addresses the critical limitations of conventional Reinforcement Learning in multi-task and non-stationary environments by enabling fast policy adaptation and improved generalization. We introduce a novel Meta-RL framework that integrates a bi-level optimization scheme with a hybrid actor-critic architecture specially designed to enhance sample efficiency and inter-task adaptability. To improve knowledge transfer, we meta-learn a shared state feature extractor jointly optimized across actor and critic networks, providing efficient representation learning and limiting overfitting to individual tasks or dominant profiles. Additionally, we propose a parameter-sharing mechanism between the outer- and inner-loop actor networks, to reduce redundant learning and accelerate adaptation during task revisitation. The approach is validated on a real-world Building Energy Management Systems dataset covering nearly a decade of temporal and structural variability, for which we propose a task preparation method to promote generalization. Experiments demonstrate effective task adaptation and better performance compared to conventional RL and Meta-RL methods.
SMGI: A Structural Theory of General Artificial Intelligence
Mar 09, 2026We introduce SMGI, a structural theory of general artificial intelligence, and recast the foundational problem of learning from the optimization of hypotheses within fixed environments to the controlled evolution of the learning interface itself. We formalize the Structural Model of General Intelligence (SMGI) via a typed meta-model $θ= (r,\mathcal H,Π,\mathcal L,\mathcal E,\mathcal M)$ that treats representational maps, hypothesis spaces, structural priors, multi-regime evaluators, and memory operators as explicitly typed, dynamic components. By enforcing a strict mathematical separation between this structural ontology ($θ$) and its induced behavioral semantics ($T_θ$), we define general artificial intelligence as a class of admissible coupled dynamics $(θ, T_θ)$ satisfying four obligations: structural closure under typed transformations, dynamical stability under certified evolution, bounded statistical capacity, and evaluative invariance across regime shifts. We prove a structural generalization bound that links sequential PAC-Bayes analysis and Lyapunov stability, providing sufficient conditions for capacity control and bounded drift under admissible task transformations. Furthermore, we establish a strict structural inclusion theorem demonstrating that classical empirical risk minimization, reinforcement learning, program-prior models (Solomonoff-style), and modern frontier agentic pipelines operate as structurally restricted instances of SMGI.
Meta-Decomposition: Dynamic Segmentation Approach Selection in IoT-based Activity Recognition
Apr 17, 2024



Internet of Things (IoT) devices generate heterogeneous data over time; and relying solely on individual data points is inadequate for accurate analysis. Segmentation is a common preprocessing step in many IoT applications, including IoT-based activity recognition, aiming to address the limitations of individual events and streamline the process. However, this step introduces at least two families of uncontrollable biases. The first is caused by the changes made by the segmentation process on the initial problem space, such as dividing the input data into 60 seconds windows. The second category of biases results from the segmentation process itself, including the fixation of the segmentation method and its parameters. To address these biases, we propose to redefine the segmentation problem as a special case of a decomposition problem, including three key components: a decomposer, resolutions, and a composer. The inclusion of the composer task in the segmentation process facilitates an assessment of the relationship between the original problem and the problem after the segmentation. Therefore, It leads to an improvement in the evaluation process and, consequently, in the selection of the appropriate segmentation method. Then, we formally introduce our novel meta-decomposition or learning-to-decompose approach. It reduces the segmentation biases by considering the segmentation as a hyperparameter to be optimized by the outer learning problem. Therefore, meta-decomposition improves the overall system performance by dynamically selecting the appropriate segmentation method without including the mentioned biases. Extensive experiments on four real-world datasets demonstrate the effectiveness of our proposal.
Boosting Medical Image Segmentation Performance with Adaptive Convolution Layer
Apr 17, 2024



Medical image segmentation plays a vital role in various clinical applications, enabling accurate delineation and analysis of anatomical structures or pathological regions. Traditional CNNs have achieved remarkable success in this field. However, they often rely on fixed kernel sizes, which can limit their performance and adaptability in medical images where features exhibit diverse scales and configurations due to variability in equipment, target sizes, and expert interpretations. In this paper, we propose an adaptive layer placed ahead of leading deep-learning models such as UCTransNet, which dynamically adjusts the kernel size based on the local context of the input image. By adaptively capturing and fusing features at multiple scales, our approach enhances the network's ability to handle diverse anatomical structures and subtle image details, even for recently performing architectures that internally implement intra-scale modules, such as UCTransnet. Extensive experiments are conducted on benchmark medical image datasets to evaluate the effectiveness of our proposal. It consistently outperforms traditional \glspl{CNN} with fixed kernel sizes with a similar number of parameters, achieving superior segmentation Accuracy, Dice, and IoU in popular datasets such as SegPC2021 and ISIC2018. The model and data are published in the open-source repository, ensuring transparency and reproducibility of our promising results.
On the Necessity of Metalearning: Learning Suitable Parameterizations for Learning Processes
Dec 31, 2023In this paper we will discuss metalearning and how we can go beyond the current classical learning paradigm. We will first address the importance of inductive biases in the learning process and what is at stake: the quantities of data necessary to learn. We will subsequently see the importance of choosing suitable parameterizations to end up with well-defined learning processes. Especially since in the context of real-world applications, we face numerous biases due, e.g., to the specificities of sensors, the heterogeneity of data sources, the multiplicity of points of view, etc. This will lead us to the idea of exploiting the structuring of the concepts to be learned in order to organize the learning process that we published previously. We conclude by discussing the perspectives around parameter-tying schemes and the emergence of universal aspects in the models thus learned.
Multi-Modal Evaluation Approach for Medical Image Segmentation
Feb 08, 2023



Manual segmentation of medical images (e.g., segmenting tumors in CT scans) is a high-effort task that can be accelerated with machine learning techniques. However, selecting the right segmentation approach depends on the evaluation function, particularly in medical image segmentation where we must deal with dependency between voxels. For instance, in contrast to classical systems where the predictions are either correct or incorrect, predictions in medical image segmentation may be partially correct and incorrect simultaneously. In this paper, we explore this expressiveness to extract the useful properties of these systems and formally define a novel multi-modal evaluation (MME) approach to measure the effectiveness of different segmentation methods. This approach improves the segmentation evaluation by introducing new relevant and interpretable characteristics, including detection property, boundary alignment, uniformity, total volume, and relative volume. Our proposed approach is open-source and publicly available for use. We have conducted several reproducible experiments, including the segmentation of pancreas, liver tumors, and multi-organs datasets, to show the applicability of the proposed approach.
Affinity-Based Hierarchical Learning of Dependent Concepts for Human Activity Recognition
Apr 11, 2021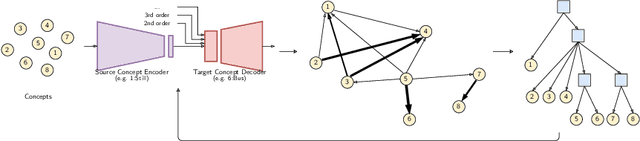
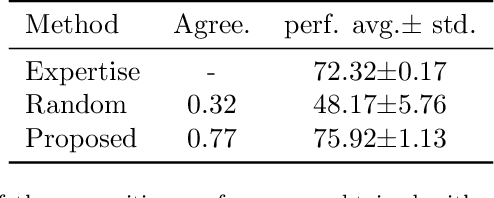
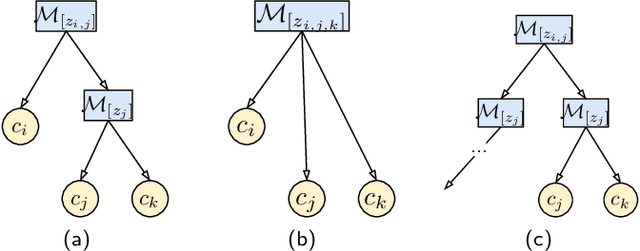
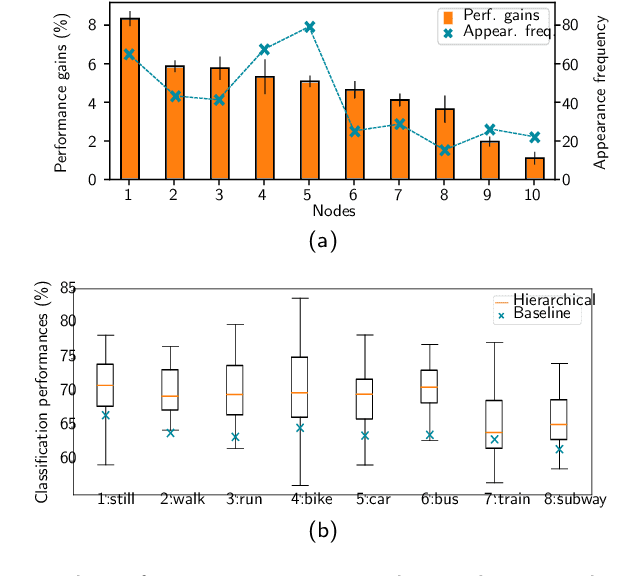
In multi-class classification tasks, like human activity recognition, it is often assumed that classes are separable. In real applications, this assumption becomes strong and generates inconsistencies. Besides, the most commonly used approach is to learn classes one-by-one against the others. This computational simplification principle introduces strong inductive biases on the learned theories. In fact, the natural connections among some classes, and not others, deserve to be taken into account. In this paper, we show that the organization of overlapping classes (multiple inheritances) into hierarchies considerably improves classification performances. This is particularly true in the case of activity recognition tasks featured in the SHL dataset. After theoretically showing the exponential complexity of possible class hierarchies, we propose an approach based on transfer affinity among the classes to determine an optimal hierarchy for the learning process. Extensive experiments show improved performances and a reduction in the number of examples needed to learn.
Description of Structural Biases and Associated Data in Sensor-Rich Environments
Apr 11, 2021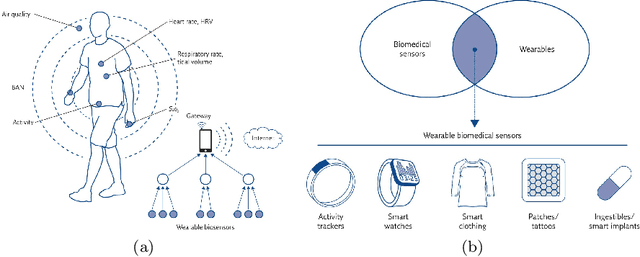
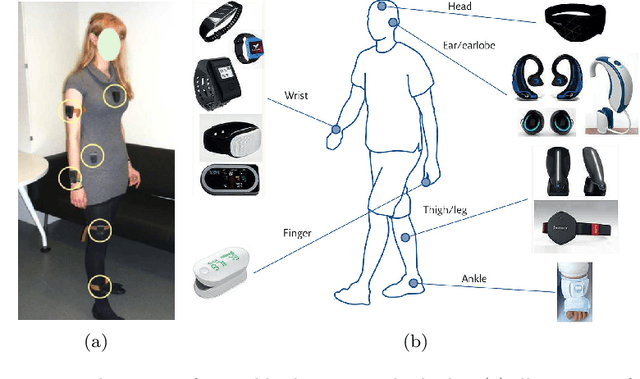
In this article, we study activity recognition in the context of sensor-rich environments. We address, in particular, the problem of inductive biases and their impact on the data collection process. To be effective and robust, activity recognition systems must take these biases into account at all levels and model them as hyperparameters by which they can be controlled. Whether it is a bias related to sensor measurement, transmission protocol, sensor deployment topology, heterogeneity, dynamicity, or stochastic effects, it is important to understand their substantial impact on the quality of activity recognition models. This study highlights the need to separate the different types of biases arising in real situations so that machine learning models, e.g., adapt to the dynamicity of these environments, resist to sensor failures, and follow the evolution of the sensors topology. We propose a metamodeling process in which the sensor data is structured in layers. The lower layers encode the various biases linked to transformations, transmissions, and topology of data. The upper layers encode biases related to the data itself. This way, it becomes easier to model hyperparameters and follow changes in the data acquisition infrastructure. We illustrate our approach on the SHL dataset which provides motion sensor data for a list of human activities collected under real conditions. The trade-offs exposed and the broader implications of our approach are discussed with alternative techniques to encode and incorporate knowledge into activity recognition models.