 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMALIA Technical Report: A Fully Open Source Large Language Model for European Portuguese
Mar 27, 2026Despite rapid progress in open large language models (LLMs), European Portuguese (pt-PT) remains underrepresented in both training data and native evaluation, with machine-translated benchmarks likely missing the variant's linguistic and cultural nuances. We introduce AMALIA, a fully open LLM that prioritizes pt-PT by using more high-quality pt-PT data during both the mid- and post-training stages. To evaluate pt-PT more faithfully, we release a suite of pt-PT benchmarks that includes translated standard tasks and four new datasets targeting pt-PT generation, linguistic competence, and pt-PT/pt-BR bias. Experiments show that AMALIA matches strong baselines on translated benchmarks while substantially improving performance on pt-PT-specific evaluations, supporting the case for targeted training and native benchmarking for European Portuguese.
AGAR: Attention Graph-RNN for Adaptative Motion Prediction of Point Clouds of Deformable Objects
Jul 19, 2023



This paper focuses on motion prediction for point cloud sequences in the challenging case of deformable 3D objects, such as human body motion. First, we investigate the challenges caused by deformable shapes and complex motions present in this type of representation, with the ultimate goal of understanding the technical limitations of state-of-the-art models. From this understanding, we propose an improved architecture for point cloud prediction of deformable 3D objects. Specifically, to handle deformable shapes, we propose a graph-based approach that learns and exploits the spatial structure of point clouds to extract more representative features. Then we propose a module able to combine the learned features in an adaptative manner according to the point cloud movements. The proposed adaptative module controls the composition of local and global motions for each point, enabling the network to model complex motions in deformable 3D objects more effectively. We tested the proposed method on the following datasets: MNIST moving digits, the Mixamo human bodies motions, JPEG and CWIPC-SXR real-world dynamic bodies. Simulation results demonstrate that our method outperforms the current baseline methods given its improved ability to model complex movements as well as preserve point cloud shape. Furthermore, we demonstrate the generalizability of the proposed framework for dynamic feature learning, by testing the framework for action recognition on the MSRAction3D dataset and achieving results on-par with state-of-the-art methods
Spatio-temporal Graph-RNN for Point Cloud Prediction
Feb 22, 2021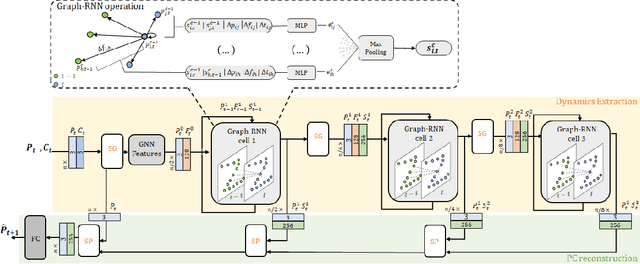
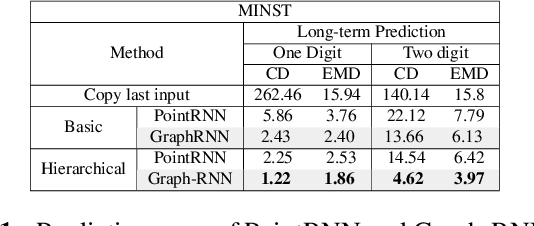

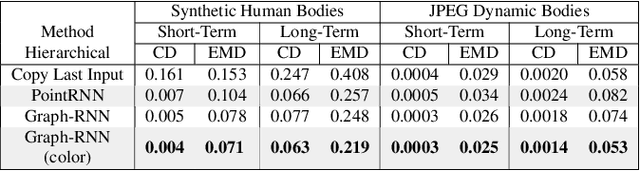
In this paper, we propose an end-to-end learning network to predict future frames in a point cloud sequence. As main novelty, an initial layer learns topological information of point clouds as geometric features, to form representative spatio-temporal neighborhoods. This module is followed by multiple Graph-RNN cells. Each cell learns points dynamics (i.e., RNN states) by processing each point jointly with the spatio-temporal neighbouring points. We tested the network performance with a MINST dataset of moving digits, a synthetic human bodies motions and JPEG dynamic bodies datasets. Simulation results demonstrate that our method outperforms baseline ones that neglect geometry features information.