 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExchangeable Variable Models
May 02, 2014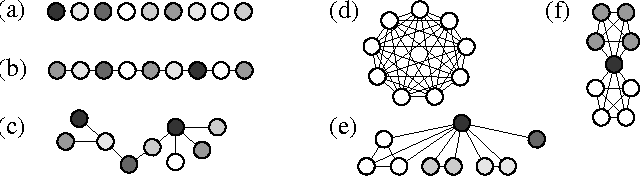
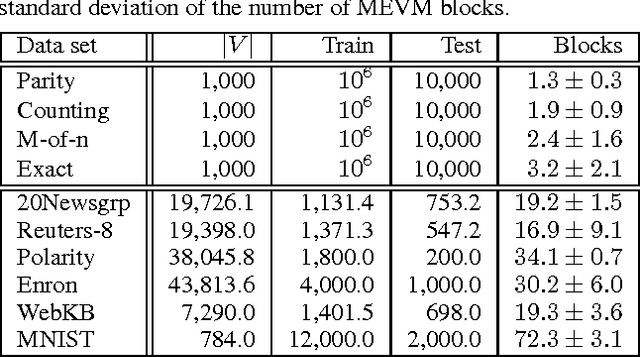
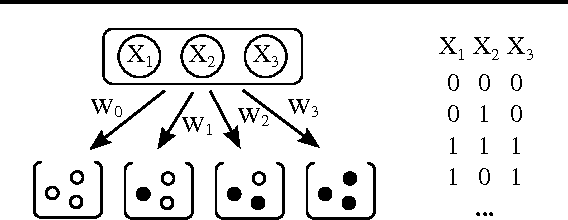
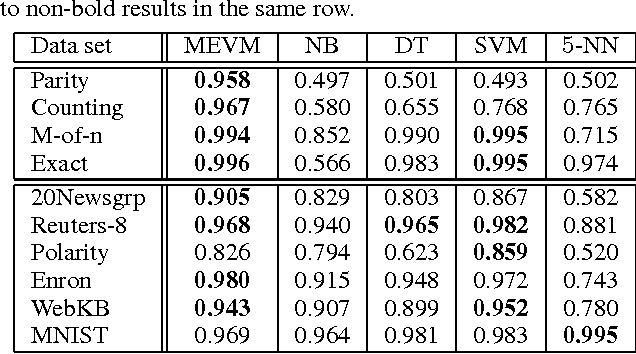
A sequence of random variables is exchangeable if its joint distribution is invariant under variable permutations. We introduce exchangeable variable models (EVMs) as a novel class of probabilistic models whose basic building blocks are partially exchangeable sequences, a generalization of exchangeable sequences. We prove that a family of tractable EVMs is optimal under zero-one loss for a large class of functions, including parity and threshold functions, and strictly subsumes existing tractable independence-based model families. Extensive experiments show that EVMs outperform state of the art classifiers such as SVMs and probabilistic models which are solely based on independence assumptions.
Structured Message Passing
Sep 26, 2013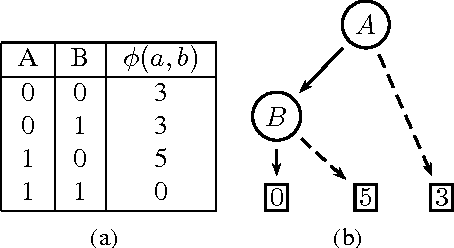
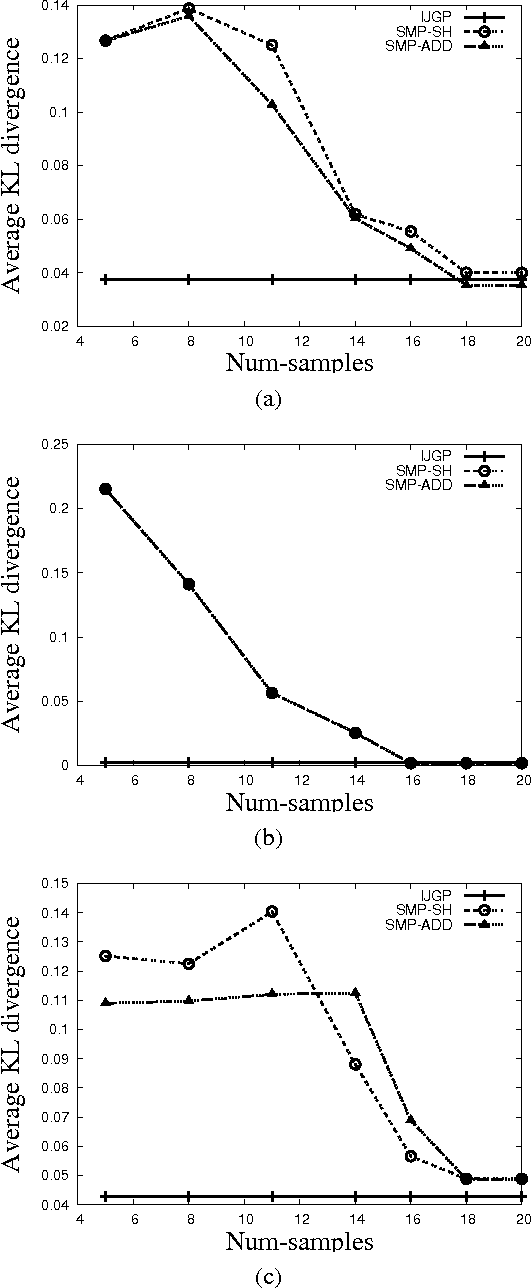
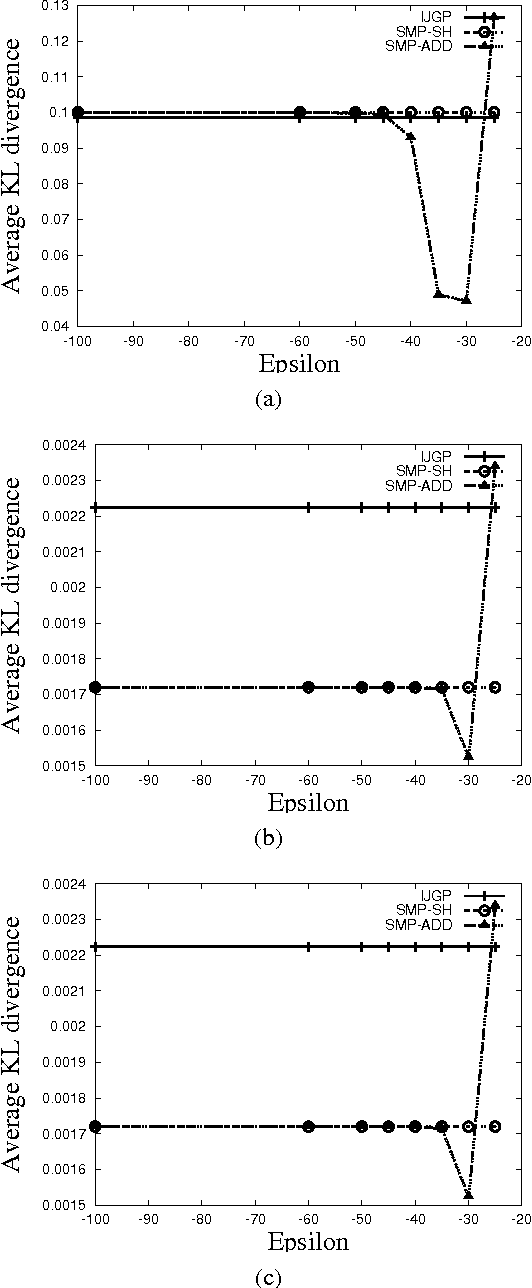
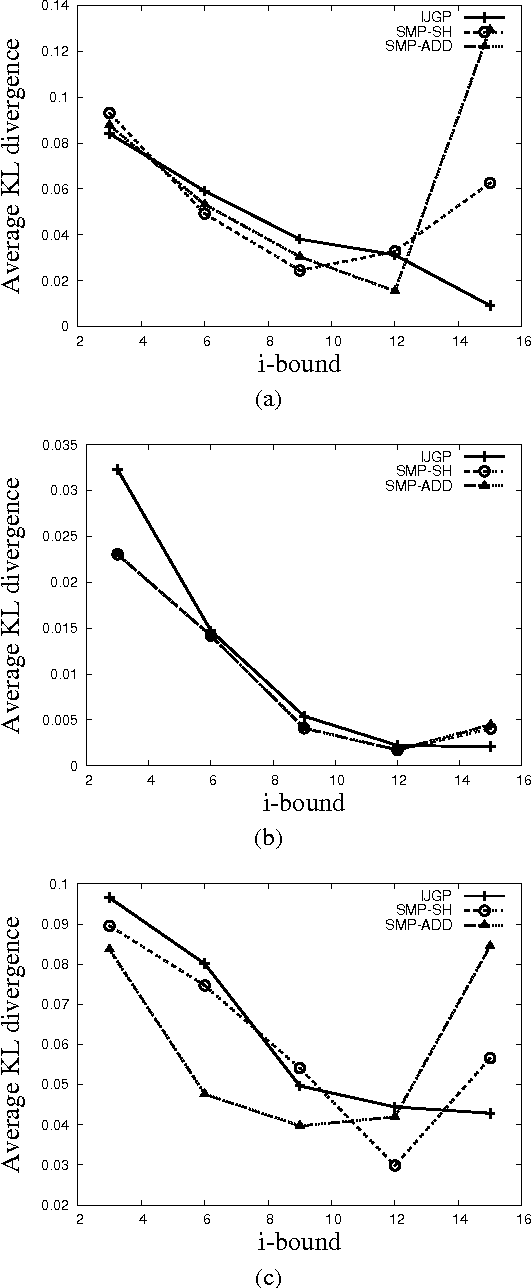
In this paper, we present structured message passing (SMP), a unifying framework for approximate inference algorithms that take advantage of structured representations such as algebraic decision diagrams and sparse hash tables. These representations can yield significant time and space savings over the conventional tabular representation when the message has several identical values (context-specific independence) or zeros (determinism) or both in its range. Therefore, in order to fully exploit the power of structured representations, we propose to artificially introduce context-specific independence and determinism in the messages. This yields a new class of powerful approximate inference algorithms which includes popular algorithms such as cluster-graph Belief propagation (BP), expectation propagation and particle BP as special cases. We show that our new algorithms introduce several interesting bias-variance trade-offs. We evaluate these trade-offs empirically and demonstrate that our new algorithms are more accurate and scalable than state-of-the-art techniques.
Markov Logic in Infinite Domains
Jun 20, 2012Combining first-order logic and probability has long been a goal of AI. Markov logic (Richardson & Domingos, 2006) accomplishes this by attaching weights to first-order formulas and viewing them as templates for features of Markov networks. Unfortunately, it does not have the full power of first-order logic, because it is only defined for finite domains. This paper extends Markov logic to infinite domains, by casting it in the framework of Gibbs measures (Georgii, 1988). We show that a Markov logic network (MLN) admits a Gibbs measure as long as each ground atom has a finite number of neighbors. Many interesting cases fall in this category. We also show that an MLN admits a unique measure if the weights of its non-unit clauses are small enough. We then examine the structure of the set of consistent measures in the non-unique case. Many important phenomena, including systems with phase transitions, are represented by MLNs with non-unique measures. We relate the problem of satisfiability in first-order logic to the properties of MLN measures, and discuss how Markov logic relates to previous infinite models.
Learning Arithmetic Circuits
Jun 13, 2012
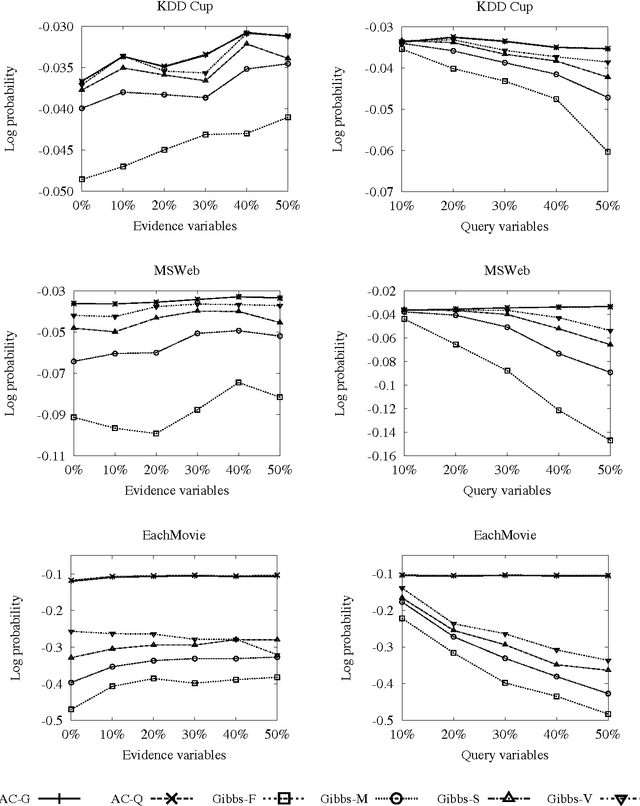

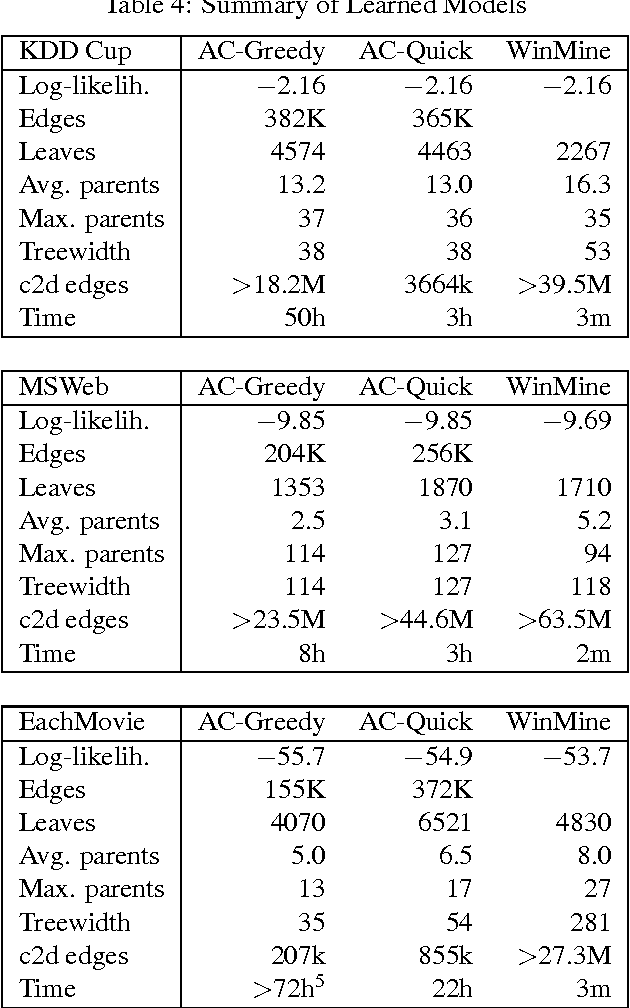
Graphical models are usually learned without regard to the cost of doing inference with them. As a result, even if a good model is learned, it may perform poorly at prediction, because it requires approximate inference. We propose an alternative: learning models with a score function that directly penalizes the cost of inference. Specifically, we learn arithmetic circuits with a penalty on the number of edges in the circuit (in which the cost of inference is linear). Our algorithm is equivalent to learning a Bayesian network with context-specific independence by greedily splitting conditional distributions, at each step scoring the candidates by compiling the resulting network into an arithmetic circuit, and using its size as the penalty. We show how this can be done efficiently, without compiling a circuit from scratch for each candidate. Experiments on several real-world domains show that our algorithm is able to learn tractable models with very large treewidth, and yields more accurate predictions than a standard context-specific Bayesian network learner, in far less time.
Formula-Based Probabilistic Inference
Mar 15, 2012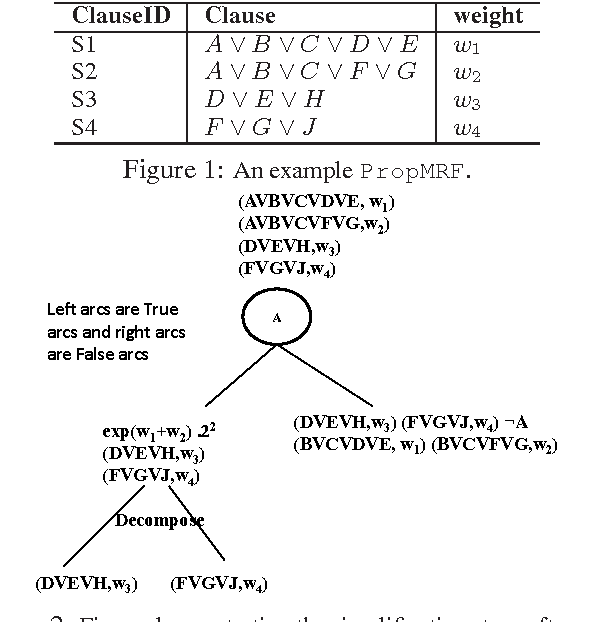
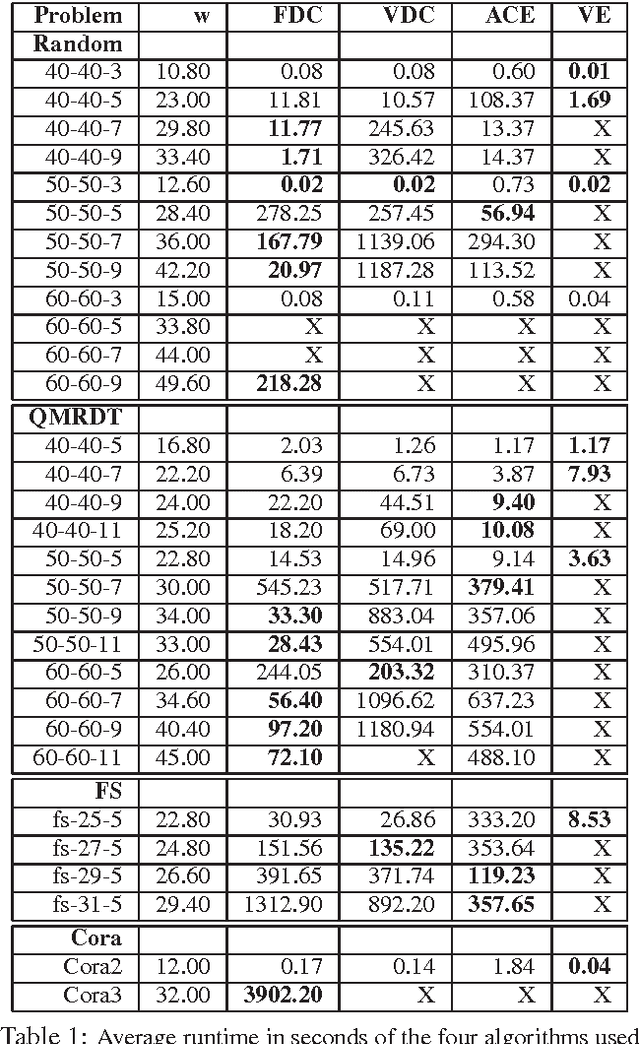
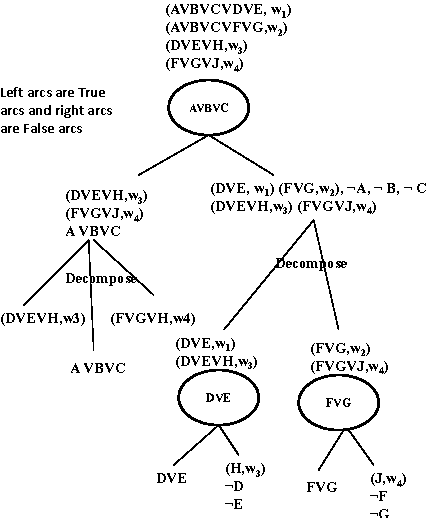
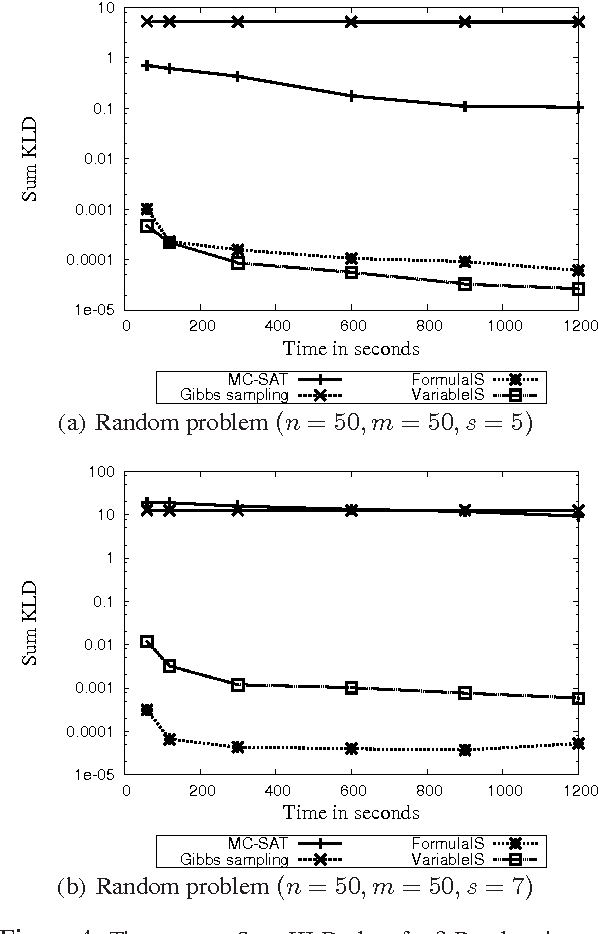
Computing the probability of a formula given the probabilities or weights associated with other formulas is a natural extension of logical inference to the probabilistic setting. Surprisingly, this problem has received little attention in the literature to date, particularly considering that it includes many standard inference problems as special cases. In this paper, we propose two algorithms for this problem: formula decomposition and conditioning, which is an exact method, and formula importance sampling, which is an approximate method. The latter is, to our knowledge, the first application of model counting to approximate probabilistic inference. Unlike conventional variable-based algorithms, our algorithms work in the dual realm of logical formulas. Theoretically, we show that our algorithms can greatly improve efficiency by exploiting the structural information in the formulas. Empirically, we show that they are indeed quite powerful, often achieving substantial performance gains over state-of-the-art schemes.
Sum-Product Networks: A New Deep Architecture
Feb 14, 2012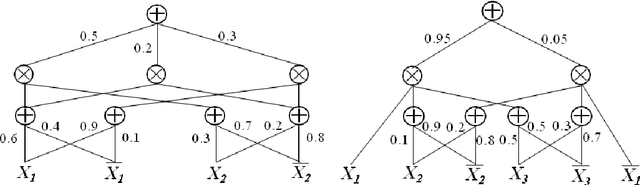
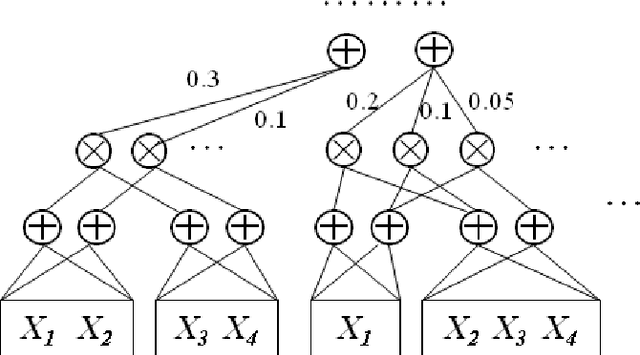

The key limiting factor in graphical model inference and learning is the complexity of the partition function. We thus ask the question: what are general conditions under which the partition function is tractable? The answer leads to a new kind of deep architecture, which we call sum-product networks (SPNs). SPNs are directed acyclic graphs with variables as leaves, sums and products as internal nodes, and weighted edges. We show that if an SPN is complete and consistent it represents the partition function and all marginals of some graphical model, and give semantics to its nodes. Essentially all tractable graphical models can be cast as SPNs, but SPNs are also strictly more general. We then propose learning algorithms for SPNs, based on backpropagation and EM. Experiments show that inference and learning with SPNs can be both faster and more accurate than with standard deep networks. For example, SPNs perform image completion better than state-of-the-art deep networks for this task. SPNs also have intriguing potential connections to the architecture of the cortex.
Probabilistic Theorem Proving
Feb 14, 2012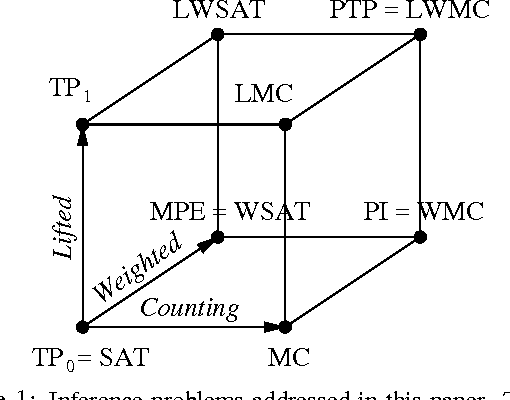
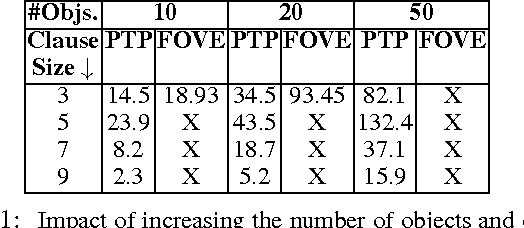
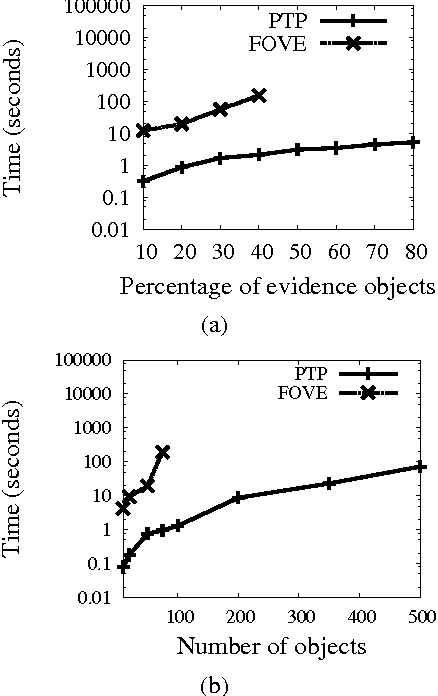
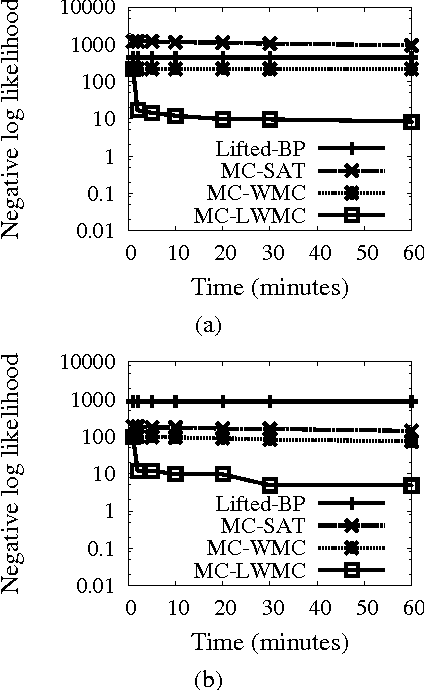
Many representation schemes combining first-order logic and probability have been proposed in recent years. Progress in unifying logical and probabilistic inference has been slower. Existing methods are mainly variants of lifted variable elimination and belief propagation, neither of which take logical structure into account. We propose the first method that has the full power of both graphical model inference and first-order theorem proving (in finite domains with Herbrand interpretations). We first define probabilistic theorem proving, their generalization, as the problem of computing the probability of a logical formula given the probabilities or weights of a set of formulas. We then show how this can be reduced to the problem of lifted weighted model counting, and develop an efficient algorithm for the latter. We prove the correctness of this algorithm, investigate its properties, and show how it generalizes previous approaches. Experiments show that it greatly outperforms lifted variable elimination when logical structure is present. Finally, we propose an algorithm for approximate probabilistic theorem proving, and show that it can greatly outperform lifted belief propagation.
Approximation by Quantization
Feb 14, 2012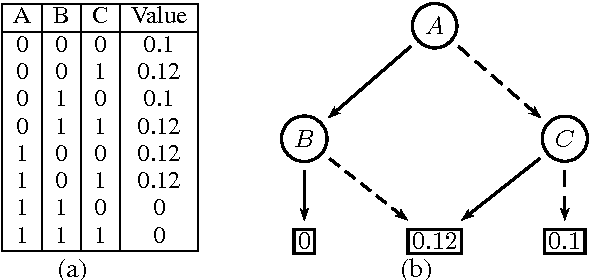
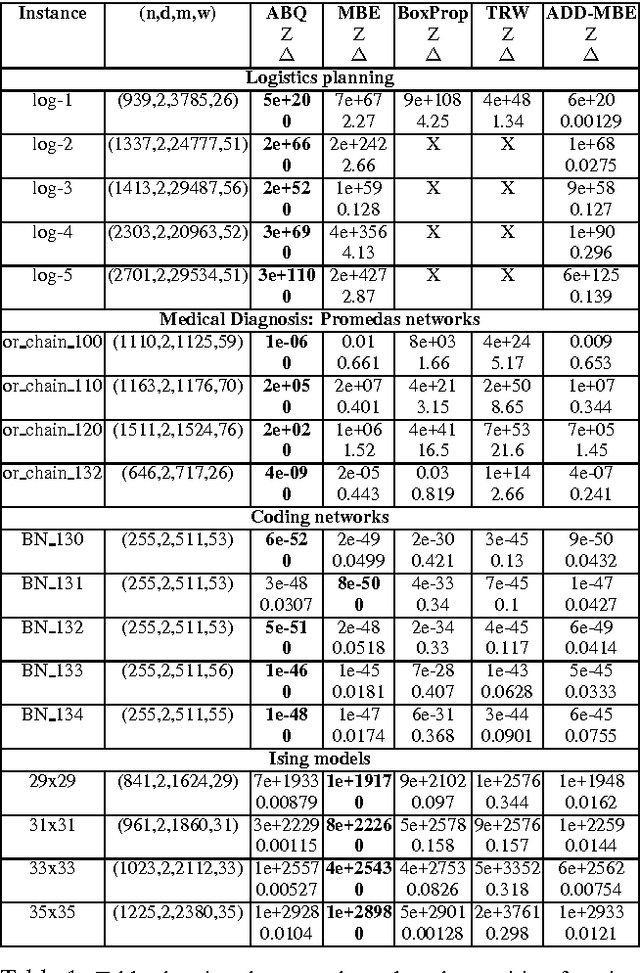
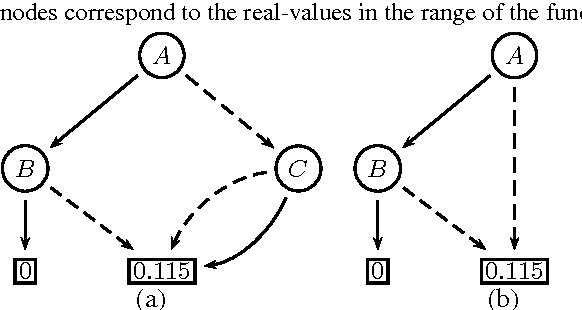
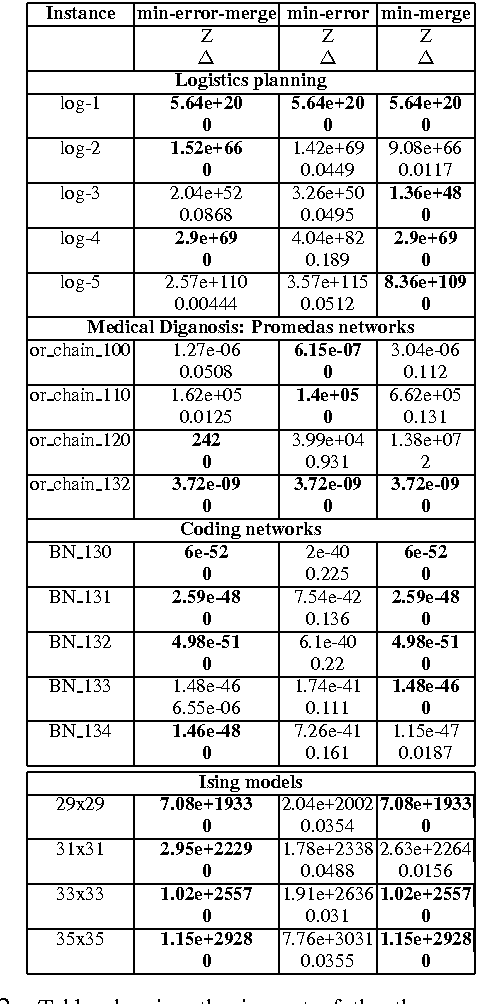
Inference in graphical models consists of repeatedly multiplying and summing out potentials. It is generally intractable because the derived potentials obtained in this way can be exponentially large. Approximate inference techniques such as belief propagation and variational methods combat this by simplifying the derived potentials, typically by dropping variables from them. We propose an alternate method for simplifying potentials: quantizing their values. Quantization causes different states of a potential to have the same value, and therefore introduces context-specific independencies that can be exploited to represent the potential more compactly. We use algebraic decision diagrams (ADDs) to do this efficiently. We apply quantization and ADD reduction to variable elimination and junction tree propagation, yielding a family of bounded approximate inference schemes. Our experimental tests show that our new schemes significantly outperform state-of-the-art approaches on many benchmark instances.