 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Approximation of Kernel functions
Mar 11, 2024Various methods in statistical learning build on kernels considered in reproducing kernel Hilbert spaces. In applications, the kernel is often selected based on characteristics of the problem and the data. This kernel is then employed to infer response variables at points, where no explanatory data were observed. The data considered here are located in compact sets in higher dimensions and the paper addresses approximations of the kernel itself. The new approach considers Taylor series approximations of radial kernel functions. For the Gauss kernel on the unit cube, the paper establishes an upper bound of the associated eigenfunctions, which grows only polynomially with respect to the index. The novel approach substantiates smaller regularization parameters than considered in the literature, overall leading to better approximations. This improvement confirms low rank approximation methods such as the Nystr\"om method.
A Bound on the Maximal Marginal Degrees of Freedom
Feb 20, 2024Common kernel ridge regression is expensive in memory allocation and computation time. This paper addresses low rank approximations and surrogates for kernel ridge regression, which bridge these difficulties. The fundamental contribution of the paper is a lower bound on the rank of the low dimensional approximation, which is required such that the prediction power remains reliable. The bound relates the effective dimension with the largest statistical leverage score. We characterize the effective dimension and its growth behavior with respect to the regularization parameter by involving the regularity of the kernel. This growth is demonstrated to be asymptotically logarithmic for suitably chosen kernels, justifying low-rank approximations as the Nystr\"om method.
Uniform Function Estimators in Reproducing Kernel Hilbert Spaces
Aug 16, 2021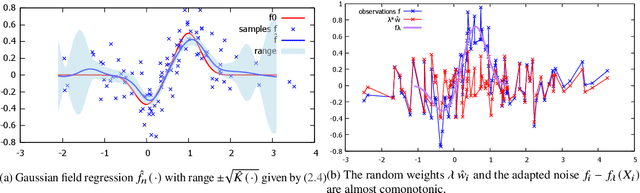
This paper addresses the problem of regression to reconstruct functions, which are observed with superimposed errors at random locations. We address the problem in reproducing kernel Hilbert spaces. It is demonstrated that the estimator, which is often derived by employing Gaussian random fields, converges in the mean norm of the reproducing kernel Hilbert space to the conditional expectation and this implies local and uniform convergence of this function estimator. By preselecting the kernel, the problem does not suffer from the curse of dimensionality. The paper analyzes the statistical properties of the estimator. We derive convergence properties and provide a conservative rate of convergence for increasing sample sizes.