 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Approximation of Kernel functions
Mar 11, 2024Various methods in statistical learning build on kernels considered in reproducing kernel Hilbert spaces. In applications, the kernel is often selected based on characteristics of the problem and the data. This kernel is then employed to infer response variables at points, where no explanatory data were observed. The data considered here are located in compact sets in higher dimensions and the paper addresses approximations of the kernel itself. The new approach considers Taylor series approximations of radial kernel functions. For the Gauss kernel on the unit cube, the paper establishes an upper bound of the associated eigenfunctions, which grows only polynomially with respect to the index. The novel approach substantiates smaller regularization parameters than considered in the literature, overall leading to better approximations. This improvement confirms low rank approximation methods such as the Nystr\"om method.
Soft Quantization using Entropic Regularization
Sep 08, 2023The quantization problem aims to find the best possible approximation of probability measures on ${\mathbb{R}}^d$ using finite, discrete measures. The Wasserstein distance is a typical choice to measure the quality of the approximation. This contribution investigates the properties and robustness of the entropy-regularized quantization problem, which relaxes the standard quantization problem. The proposed approximation technique naturally adopts the softmin function, which is well known for its robustness in terms of theoretical and practicability standpoints. Moreover, we use the entropy-regularized Wasserstein distance to evaluate the quality of the soft quantization problem's approximation, and we implement a stochastic gradient approach to achieve the optimal solutions. The control parameter in our proposed method allows for the adjustment of the optimization problem's difficulty level, providing significant advantages when dealing with exceptionally challenging problems of interest. As well, this contribution empirically illustrates the performance of the method in various expositions.
Uniform Function Estimators in Reproducing Kernel Hilbert Spaces
Aug 16, 2021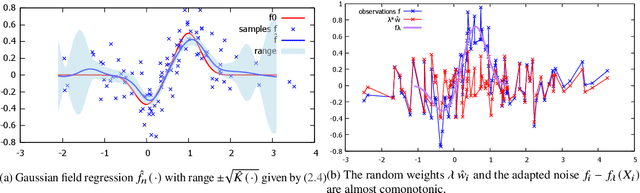
This paper addresses the problem of regression to reconstruct functions, which are observed with superimposed errors at random locations. We address the problem in reproducing kernel Hilbert spaces. It is demonstrated that the estimator, which is often derived by employing Gaussian random fields, converges in the mean norm of the reproducing kernel Hilbert space to the conditional expectation and this implies local and uniform convergence of this function estimator. By preselecting the kernel, the problem does not suffer from the curse of dimensionality. The paper analyzes the statistical properties of the estimator. We derive convergence properties and provide a conservative rate of convergence for increasing sample sizes.
New Algorithms And Fast Implementations To Approximate Stochastic Processes
Dec 01, 2020


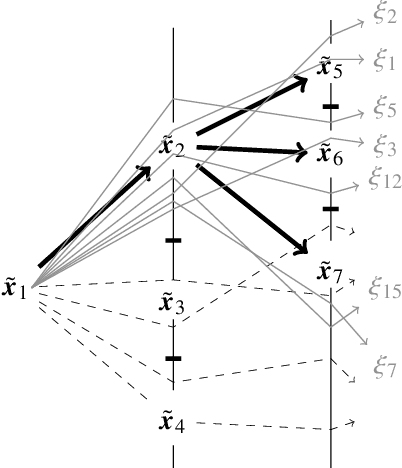
We present new algorithms and fast implementations to find efficient approximations for modelling stochastic processes. For many numerical computations it is essential to develop finite approximations for stochastic processes. While the goal is always to find a finite model, which represents a given knowledge about the real data process as accurate as possible, the ways of estimating the discrete approximating model may be quite different: (i) if the stochastic model is known as a solution of a stochastic differential equation, e.g., one may generate the scenario tree directly from the specified model; (ii) if a simulation algorithm is available, which allows simulating trajectories from all conditional distributions, a scenario tree can be generated by stochastic approximation; (iii) if only some observed trajectories of the scenario process are available, the construction of the approximating process can be based on non-parametric conditional density estimates.