 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Data Is Scarce: Scaling Sparse Language Models with Repeated Training
May 31, 2026Scaling laws for dense LLMs under infinite data are well explored, but how sparsity interacts with limited data is not. In this work, we study sparse training in data-constrained regimes where limited unique tokens require multi-epoch training. Our experiments span models up to 1.92B parameters in the fitting set, sparsity up to 93.75%, unique data budgets up to 2.6B tokens, and total training tokens up to 41.6B over 16 epochs; we further validate extrapolation on held-out dense-equivalent models up to 7.68B parameters. We find that: 1. Sparse scaling in data-limited settings: We introduce a scaling law that models loss as a function of active parameters, unique tokens, data repetition, and sparsity, accurately predicting performance across compute and data budgets. 2. Delayed data saturation: sparse training postpones diminishing returns from repeated data, making multi-epoch training more effective. 3. Resource trade-offs: With fixed data, loss-optimal sparsity is moderate ~ 50%, while compute-optimal sparsity is higher and grows with data scale. Overall, sparsity is not just a tool for efficiency, but a mechanism for improving scaling trade-offs under data scarcity. Our code is available at: https://github.com/boqian333/sparse-dc-scaling.
Memory-Efficient LLM Training with Dynamic Sparsity: From Stability to Practical Scaling
May 30, 2026Dynamic Sparse Training (DST) offers a promising paradigm for improving the training and inference efficiency of deep neural networks; however, we find that in large language model training, DST can suffer from optimization instability, manifested as loss spikes after topology updates. In this work, we show that the naive use of standard Adam-based optimizers leads to a cold-start issue for newly regrown parameters, resulting in excessively large updates and disrupted training dynamics. To address this issue, we propose Sparse Memory-Efficient Training (SMET), which stabilizes DST with optimizer warm-up and improves training progress through density-aware learning-rate scaling. SMET further reduces memory consumption by storing gradients and optimizer states only for active parameters. We provide a theoretical analysis of the update behaviors under SMET, showing improved optimization stability. Extensive experiments demonstrate that SMET enables stable, scalable, and memory-efficient sparse pre-training of LLMs, paving the way for sparse training as a practical alternative to dense training. Our code is publicly available at: https://github.com/QiaoXiao7282/SMET.
Confounder Detection via Treatment Intent: A New Observational Study Design
May 26, 2026Understanding the effects of interventions is central to scientific progress, with randomized controlled trials (RCTs) regarded as the gold standard for causal inference in many applied fields. However, RCTs are costly, time-consuming, and often constrained by ethical or practical limitations, motivating the need for causal methods able to draw conclusions from observational data. While such data is collected at ever larger scale, making its use for causal inference is often hindered by the fact that not all variables affecting treatment allocation and the outcome are observed: an issue known as unobserved confounding. In this paper, we introduce a new study design called confounder detection via treatment intent. The idea is to query a human expert who makes treatment decisions, and ask them to compare pairs of units proposed by a principled matching strategy, with the goal of eliciting unobserved variables that explain why treatment decisions differ. We provide a theoretical basis for such a procedure, ascertaining conditions under which such a study design may elicit unobserved confounders. Building on this newly established foundations, we study treatment effects of interventions in the intensive care unit (ICU). First, we show empirical evidence strongly indicating that electronic health records (EHRs) collected in ICUs are subject to unobserved confounding. By using clinical text notes as a proxy for physicians' knowledge and leveraging natural language processing, we provide a proof of concept for our methodology in a semi-synthetic environment with a known ground truth.
Large Language Model Selection with Limited Annotations
May 24, 2026Choosing a Large Language Model (LLM) for a given task requires comparing many strong candidates, yet standard evaluation relies on costly annotations over fixed evaluation sets. To address this challenge, we develop SELECT-LLM, the first framework for active model selection of LLMs. SELECT-LLM aims to find a small set of queries whose annotations are most informative for identifying the best LLM for a given task. To this end, we introduce a query selection rule based on expected information gain, computed from pairwise similarities between candidate model outputs. Because this rule only uses generated model responses, SELECT-LLM can be applied across candidate models without assumptions about their architecture or access to model weights. This makes it suitable for both open-weight and black-box LLMs. We evaluate SELECT-LLM across 23 datasets, 156 evaluated models, diverse task families, and multiple text evaluation metrics. Across all experiments, SELECT-LLM improves over the strongest baseline in every setting, with annotation cost reductions up to 81.8% for best model selection and up to 84.78% for near-best model selection.
Active Model Selection for Large Language Models
Oct 10, 2025



We introduce LLM SELECTOR, the first framework for active model selection of Large Language Models (LLMs). Unlike prior evaluation and benchmarking approaches that rely on fully annotated datasets, LLM SELECTOR efficiently identifies the best LLM with limited annotations. In particular, for any given task, LLM SELECTOR adaptively selects a small set of queries to annotate that are most informative about the best model for the task. To further reduce annotation cost, we leverage a judge-based oracle annotation model. Through extensive experiments on 6 benchmarks with 151 LLMs, we show that LLM SELECTOR reduces annotation costs by up to 59.62% when selecting the best and near-best LLM for the task.
All models are wrong, some are useful: Model Selection with Limited Labels
Oct 17, 2024



With the multitude of pretrained models available thanks to the advancements in large-scale supervised and self-supervised learning, choosing the right model is becoming increasingly pivotal in the machine learning lifecycle. However, much like the training process, choosing the best pretrained off-the-shelf model for raw, unlabeled data is a labor-intensive task. To overcome this, we introduce MODEL SELECTOR, a framework for label-efficient selection of pretrained classifiers. Given a pool of unlabeled target data, MODEL SELECTOR samples a small subset of highly informative examples for labeling, in order to efficiently identify the best pretrained model for deployment on this target dataset. Through extensive experiments, we demonstrate that MODEL SELECTOR drastically reduces the need for labeled data while consistently picking the best or near-best performing model. Across 18 model collections on 16 different datasets, comprising over 1,500 pretrained models, MODEL SELECTOR reduces the labeling cost by up to 94.15% to identify the best model compared to the cost of the strongest baseline. Our results further highlight the robustness of MODEL SELECTOR in model selection, as it reduces the labeling cost by up to 72.41% when selecting a near-best model, whose accuracy is only within 1% of the best model.
Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning
May 28, 2023



Methods for carefully selecting or generating a small set of training data to learn from, i.e., data pruning, coreset selection, and data distillation, have been shown to be effective in reducing the ever-increasing cost of training neural networks. Behind this success are rigorously designed strategies for identifying informative training examples out of large datasets. However, these strategies come with additional computational costs associated with subset selection or data distillation before training begins, and furthermore, many are shown to even under-perform random sampling in high data compression regimes. As such, many data pruning, coreset selection, or distillation methods may not reduce 'time-to-accuracy', which has become a critical efficiency measure of training deep neural networks over large datasets. In this work, we revisit a powerful yet overlooked random sampling strategy to address these challenges and introduce an approach called Repeated Sampling of Random Subsets (RSRS or RS2), where we randomly sample the subset of training data for each epoch of model training. We test RS2 against thirty state-of-the-art data pruning and data distillation methods across four datasets including ImageNet. Our results demonstrate that RS2 significantly reduces time-to-accuracy compared to existing techniques. For example, when training on ImageNet in the high-compression regime (using less than 10% of the dataset each epoch), RS2 yields accuracy improvements up to 29% compared to competing pruning methods while offering a runtime reduction of 7x. Beyond the above meta-study, we provide a convergence analysis for RS2 and discuss its generalization capability. The primary goal of our work is to establish RS2 as a competitive baseline for future data selection or distillation techniques aimed at efficient training.
Gated Domain Units for Multi-source Domain Generalization
Jun 24, 2022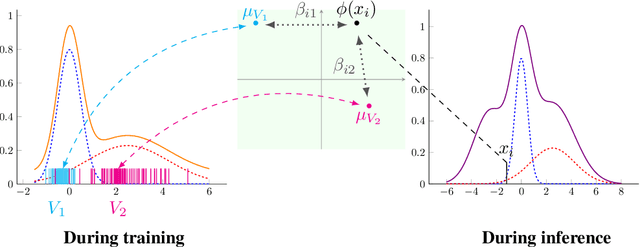

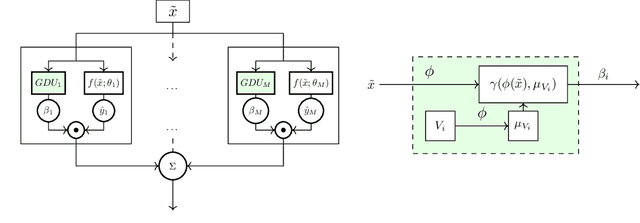
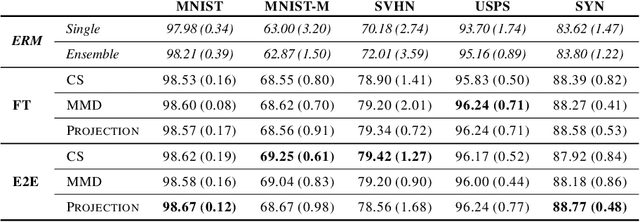
Distribution shift (DS) is a common problem that deteriorates the performance of learning machines. To overcome this problem, we postulate that real-world distributions are composed of elementary distributions that remain invariant across different domains. We call this an invariant elementary distribution (I.E.D.) assumption. This invariance thus enables knowledge transfer to unseen domains. To exploit this assumption in domain generalization (DG), we developed a modular neural network layer that consists of Gated Domain Units (GDUs). Each GDU learns an embedding of an individual elementary domain that allows us to encode the domain similarities during the training. During inference, the GDUs compute similarities between an observation and each of the corresponding elementary distributions which are then used to form a weighted ensemble of learning machines. Because our layer is trained with backpropagation, it can be easily integrated into existing deep learning frameworks. Our evaluation on Digits5, ECG, Camelyon17, iWildCam, and FMoW shows a significant improvement in the performance on out-of-training target domains without any access to data from the target domains. This finding supports the validity of the I.E.D. assumption in real-world data distributions.