 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespondeoQA: a Benchmark for Bilingual Latin-English Question Answering
Apr 22, 2026We introduce a benchmark dataset for question answering and translation in bilingual Latin and English settings, containing about 7,800 question-answer pairs. The questions are drawn from Latin pedagogical sources, including exams, quizbowl-style trivia, and textbooks ranging from the 1800s to the present. After automated extraction, cleaning, and manual review, the dataset covers a diverse range of question types: knowledge- and skill-based, multihop reasoning, constrained translation, and mixed language pairs. To our knowledge, this is the first QA benchmark centered on Latin. As a case study, we evaluate three large language models -- LLaMa 3, Qwen QwQ, and OpenAI's o3-mini -- finding that all perform worse on skill-oriented questions. Although the reasoning models perform better on scansion and literary-device tasks, they offer limited improvement overall. QwQ performs slightly better on questions asked in Latin, but LLaMa3 and o3-mini are more task dependent. This dataset provides a new resource for assessing model capabilities in a specialized linguistic and cultural domain, and the creation process can be easily adapted for other languages. The dataset is available at: https://github.com/slanglab/RespondeoQA
Contextual morphologically-guided tokenization for Latin encoder models
Nov 12, 2025Tokenization is a critical component of language model pretraining, yet standard tokenization methods often prioritize information-theoretical goals like high compression and low fertility rather than linguistic goals like morphological alignment. In fact, they have been shown to be suboptimal for morphologically rich languages, where tokenization quality directly impacts downstream performance. In this work, we investigate morphologically-aware tokenization for Latin, a morphologically rich language that is medium-resource in terms of pretraining data, but high-resource in terms of curated lexical resources -- a distinction that is often overlooked but critical in discussions of low-resource language modeling. We find that morphologically-guided tokenization improves overall performance on four downstream tasks. Performance gains are most pronounced for out of domain texts, highlighting our models' improved generalization ability. Our findings demonstrate the utility of linguistic resources to improve language modeling for morphologically complex languages. For low-resource languages that lack large-scale pretraining data, the development and incorporation of linguistic resources can serve as a feasible alternative to improve LM performance.
LatinCy: Synthetic Trained Pipelines for Latin NLP
May 07, 2023This paper introduces LatinCy, a set of trained general purpose Latin-language "core" pipelines for use with the spaCy natural language processing framework. The models are trained on a large amount of available Latin data, including all five of the Latin Universal Dependency treebanks, which have been preprocessed to be compatible with each other. The result is a set of general models for Latin with good performance on a number of natural language processing tasks (e.g. the top-performing model yields POS tagging, 97.41% accuracy; lemmatization, 94.66% accuracy; morphological tagging 92.76% accuracy). The paper describes the model training, including its training data and parameterization, and presents the advantages to Latin-language researchers of having a spaCy model available for NLP work.
Latin BERT: A Contextual Language Model for Classical Philology
Sep 21, 2020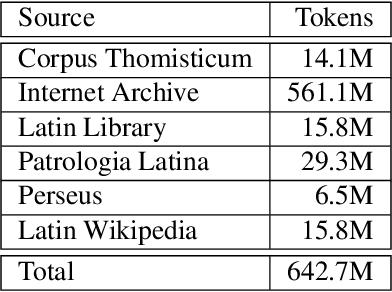
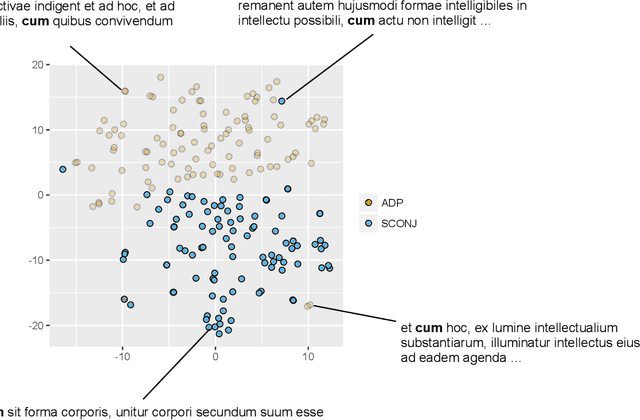
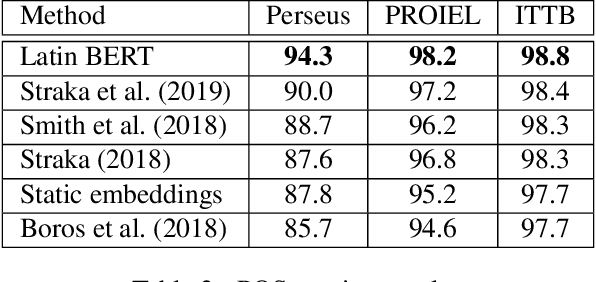
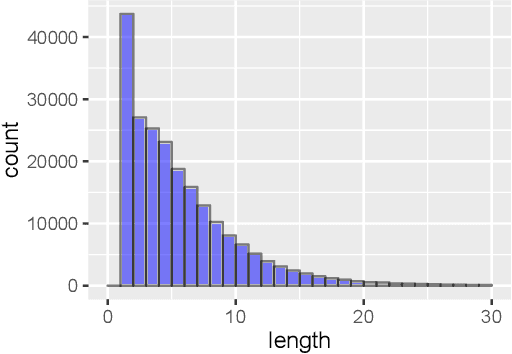
We present Latin BERT, a contextual language model for the Latin language, trained on 642.7 million words from a variety of sources spanning the Classical era to the 21st century. In a series of case studies, we illustrate the affordances of this language-specific model both for work in natural language processing for Latin and in using computational methods for traditional scholarship: we show that Latin BERT achieves a new state of the art for part-of-speech tagging on all three Universal Dependency datasets for Latin and can be used for predicting missing text (including critical emendations); we create a new dataset for assessing word sense disambiguation for Latin and demonstrate that Latin BERT outperforms static word embeddings; and we show that it can be used for semantically-informed search by querying contextual nearest neighbors. We publicly release trained models to help drive future work in this space.