 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
End-to-End Jet Classification of Quarks and Gluons with the CMS Open Data
Feb 21, 2019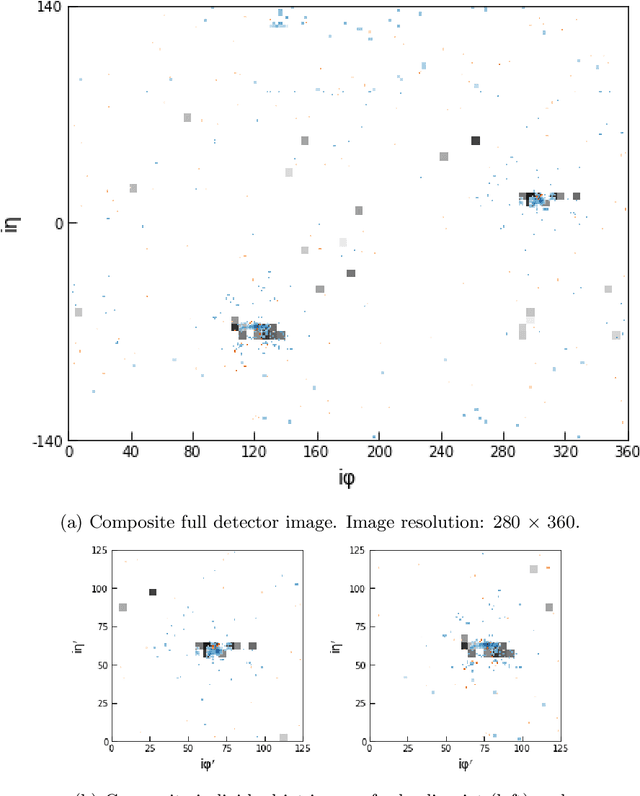
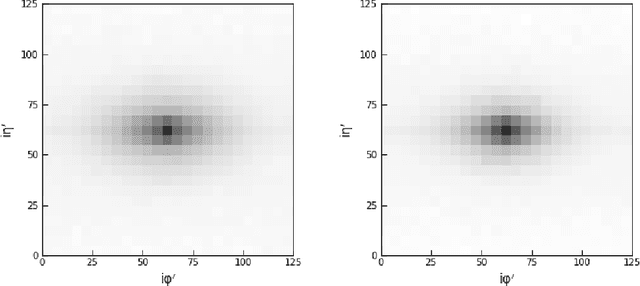
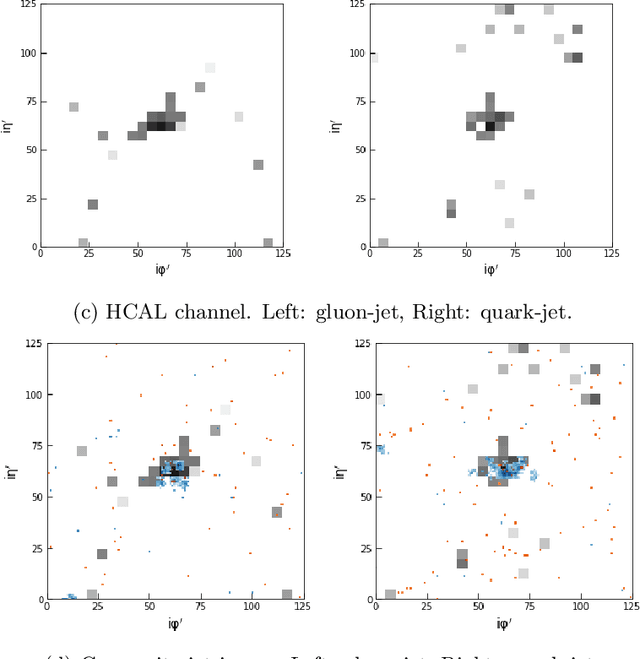
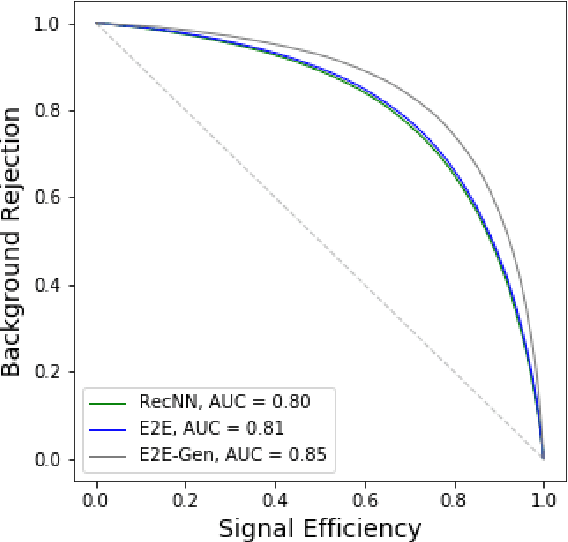
We describe the construction of end-to-end jet image classifiers based on simulated low-level detector data to discriminate quark- vs. gluon-initiated jets with high-fidelity simulated CMS Open Data. We highlight the importance of precise spatial information and demonstrate competitive performance to existing state-of-the-art jet classifiers. We further generalize the end-to-end approach to event-level classification of quark vs. gluon di-jet QCD events. We compare the fully end-to-end approach to using hand-engineered features and demonstrate that the end-to-end algorithm is robust against the effects of underlying event and pile-up.