 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacroLens: A Multi-Task Benchmark for Contextual Financial Reasoning under Macroeconomic Scenarios
Jun 23, 2026Financial decision-making is contextual: forecasting prices, valuing companies, and assessing event exposure weigh price history, accounting fundamentals, macroeconomic regime, and contemporaneous text. A benchmark over these four signals is hard to build because finance violates four assumptions of time-series evaluation: text must be gated by its publication date to prevent look-ahead, quarterly fundamentals are reported with a one- to ninety-day lag, filing text is partly redundant with the numerical statement fields it accompanies, and macroeconomic regimes leak across calendar splits. No public benchmark addresses all four signals jointly. MacroLens covers 4,416 U.S. small- and micro-cap equities over 2021-2026. Seven tasks share one point-in-time panel of prices, 46.8M XBRL accounting facts, 53 macroeconomic series, 295,860 SEC filings, and 215,882 news articles, plus a scenario layer of 1,130 macroeconomic events across 49 types automatically detected and rendered as natural language. Tasks span contextual forecasting, public and private valuation, statement generation from fundamentals and descriptions, scenario-conditioned returns, and real-estate valuation. We evaluate 19 methods across six families spanning naive heuristics through time-series foundation models, fine-tuned LLM-based time-series models, and zero-shot large language models (LLMs), plus a five-step feature-context ablation on two frontier LLMs and a gradient-boosted baseline. MacroLens is released at https://huggingface.co/datasets/DeepAuto-AI/MacroLens.
OmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
May 28, 2026Real-world information needs require access to structurally diverse knowledge sources, from unstructured text and relational tables to knowledge graphs and property graphs. Existing retrievers, however, operate over one source at a time under a fixed query language, leaving the broader landscape of available knowledge fragmented behind incompatible interfaces. A natural attempt at unification would collapse these sources into a shared space, but this erases the structural affordances (such as schemas, ontologies, compositional operators) that give each source its expressive power. Effective retrieval over diverse knowledge, therefore, requires not homogenization but an overarching layer that meets each source on its own terms. To achieve this, we present OmniRetrieval, a framework that takes any natural-language query, identifies appropriate knowledge sources, and dispatches source-native queries to their native execution engines. Across an extensive benchmark spanning 13 datasets and 309 distinct knowledge bases over text, relational, and graph-structured sources, OmniRetrieval exceeds single-source baselines, demonstrating that it can serve as a general-purpose interface to the heterogeneous sources while preserving the structural distinctions that make each source valuable.
TS-Debate: Multimodal Collaborative Debate for Zero-Shot Time Series Reasoning
Jan 27, 2026Recent progress at the intersection of large language models (LLMs) and time series (TS) analysis has revealed both promise and fragility. While LLMs can reason over temporal structure given carefully engineered context, they often struggle with numeric fidelity, modality interference, and principled cross-modal integration. We present TS-Debate, a modality-specialized, collaborative multi-agent debate framework for zero-shot time series reasoning. TS-Debate assigns dedicated expert agents to textual context, visual patterns, and numerical signals, preceded by explicit domain knowledge elicitation, and coordinates their interaction via a structured debate protocol. Reviewer agents evaluate agent claims using a verification-conflict-calibration mechanism, supported by lightweight code execution and numerical lookup for programmatic verification. This architecture preserves modality fidelity, exposes conflicting evidence, and mitigates numeric hallucinations without task-specific fine-tuning. Across 20 tasks spanning three public benchmarks, TS-Debate achieves consistent and significant performance improvements over strong baselines, including standard multimodal debate in which all agents observe all inputs.
Agentic Predictor: Performance Prediction for Agentic Workflows via Multi-View Encoding
May 26, 2025
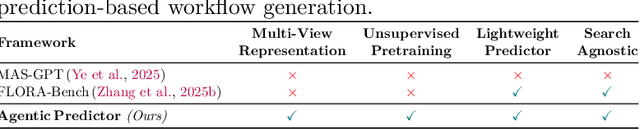

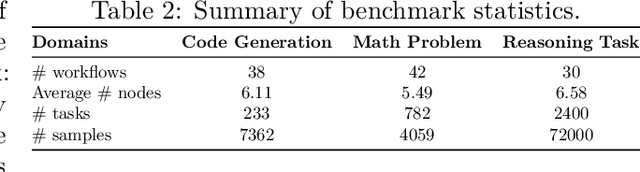
Large language models (LLMs) have demonstrated remarkable capabilities across diverse tasks, but optimizing LLM-based agentic systems remains challenging due to the vast search space of agent configurations, prompting strategies, and communication patterns. Existing approaches often rely on heuristic-based tuning or exhaustive evaluation, which can be computationally expensive and suboptimal. This paper proposes Agentic Predictor, a lightweight predictor for efficient agentic workflow evaluation. Agentic Predictor is equipped with a multi-view workflow encoding technique that leverages multi-view representation learning of agentic systems by incorporating code architecture, textual prompts, and interaction graph features. To achieve high predictive accuracy while significantly reducing the number of required workflow evaluations for training a predictor, Agentic Predictor employs cross-domain unsupervised pretraining. By learning to approximate task success rates, Agentic Predictor enables fast and accurate selection of optimal agentic workflow configurations for a given task, significantly reducing the need for expensive trial-and-error evaluations. Experiments on a carefully curated benchmark spanning three domains show that our predictor outperforms state-of-the-art methods in both predictive accuracy and workflow utility, highlighting the potential of performance predictors in streamlining the design of LLM-based agentic workflows.
MONAQ: Multi-Objective Neural Architecture Querying for Time-Series Analysis on Resource-Constrained Devices
May 15, 2025



The growing use of smartphones and IoT devices necessitates efficient time-series analysis on resource-constrained hardware, which is critical for sensing applications such as human activity recognition and air quality prediction. Recent efforts in hardware-aware neural architecture search (NAS) automate architecture discovery for specific platforms; however, none focus on general time-series analysis with edge deployment. Leveraging the problem-solving and reasoning capabilities of large language models (LLM), we propose MONAQ, a novel framework that reformulates NAS into Multi-Objective Neural Architecture Querying tasks. MONAQ is equipped with multimodal query generation for processing multimodal time-series inputs and hardware constraints, alongside an LLM agent-based multi-objective search to achieve deployment-ready models via code generation. By integrating numerical data, time-series images, and textual descriptions, MONAQ improves an LLM's understanding of time-series data. Experiments on fifteen datasets demonstrate that MONAQ-discovered models outperform both handcrafted models and NAS baselines while being more efficient.
AutoML-Agent: A Multi-Agent LLM Framework for Full-Pipeline AutoML
Oct 03, 2024



Automated machine learning (AutoML) accelerates AI development by automating tasks in the development pipeline, such as optimal model search and hyperparameter tuning. Existing AutoML systems often require technical expertise to set up complex tools, which is in general time-consuming and requires a large amount of human effort. Therefore, recent works have started exploiting large language models (LLM) to lessen such burden and increase the usability of AutoML frameworks via a natural language interface, allowing non-expert users to build their data-driven solutions. These methods, however, are usually designed only for a particular process in the AI development pipeline and do not efficiently use the inherent capacity of the LLMs. This paper proposes AutoML-Agent, a novel multi-agent framework tailored for full-pipeline AutoML, i.e., from data retrieval to model deployment. AutoML-Agent takes user's task descriptions, facilitates collaboration between specialized LLM agents, and delivers deployment-ready models. Unlike existing work, instead of devising a single plan, we introduce a retrieval-augmented planning strategy to enhance exploration to search for more optimal plans. We also decompose each plan into sub-tasks (e.g., data preprocessing and neural network design) each of which is solved by a specialized agent we build via prompting executing in parallel, making the search process more efficient. Moreover, we propose a multi-stage verification to verify executed results and guide the code generation LLM in implementing successful solutions. Extensive experiments on seven downstream tasks using fourteen datasets show that AutoML-Agent achieves a higher success rate in automating the full AutoML process, yielding systems with good performance throughout the diverse domains.
Universal Time-Series Representation Learning: A Survey
Jan 08, 2024



Time-series data exists in every corner of real-world systems and services, ranging from satellites in the sky to wearable devices on human bodies. Learning representations by extracting and inferring valuable information from these time series is crucial for understanding the complex dynamics of particular phenomena and enabling informed decisions. With the learned representations, we can perform numerous downstream analyses more effectively. Among several approaches, deep learning has demonstrated remarkable performance in extracting hidden patterns and features from time-series data without manual feature engineering. This survey first presents a novel taxonomy based on three fundamental elements in designing state-of-the-art universal representation learning methods for time series. According to the proposed taxonomy, we comprehensively review existing studies and discuss their intuitions and insights into how these methods enhance the quality of learned representations. Finally, as a guideline for future studies, we summarize commonly used experimental setups and datasets and discuss several promising research directions. An up-to-date corresponding resource is available at https://github.com/itouchz/awesome-deep-time-series-representations.