 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Re-evaluation of Knowledge Graph Completion Methods
Nov 10, 2019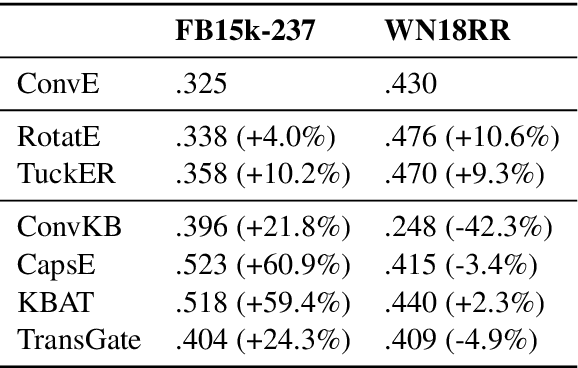
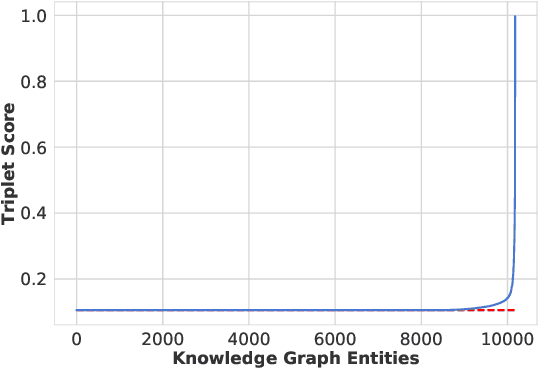

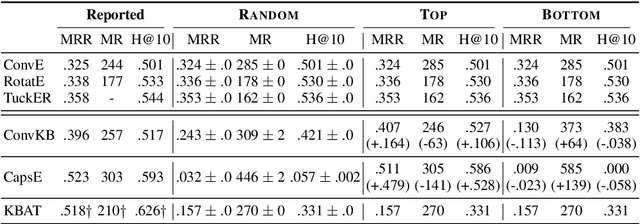
Knowledge Graph Completion (KGC) aims at automatically predicting missing links for large-scale knowledge graphs. A vast number of state-of-the-art KGC techniques have been published in top conferences in several research fields including data mining, machine learning, and natural language processing. However, we notice that several recent papers report very high performance which largely outperforms previous state-of-the-art methods. In this paper, we find that this can be attributed to the inappropriate evaluation protocol used by them and propose a simple evaluation protocol to address this problem. The proposed protocol is robust to handle bias in the model which can substantially affect the final results. We conduct extensive experiments and report the performance of several existing methods using our protocol.
Composition-based Multi-Relational Graph Convolutional Networks
Nov 08, 2019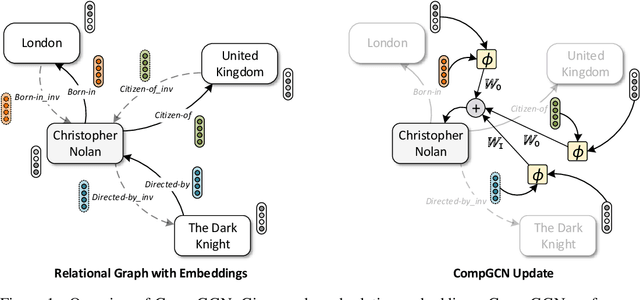

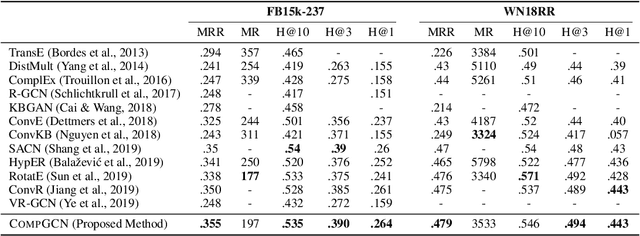
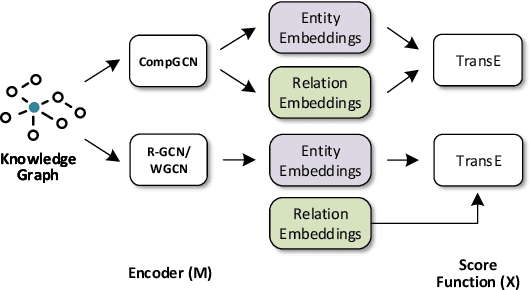
Graph Convolutional Networks (GCNs) have recently been shown to be quite successful in modeling graph-structured data. However, the primary focus has been on handling simple undirected graphs. Multi-relational graphs are a more general and prevalent form of graphs where each edge has a label and direction associated with it. Most of the existing approaches to handle such graphs suffer from over-parameterization and are restricted to learning representations of nodes only. In this paper, we propose CompGCN, a novel Graph Convolutional framework which jointly embeds both nodes and relations in a relational graph. CompGCN leverages a variety of entity-relation composition operations from Knowledge Graph Embedding techniques and scales with the number of relations. It also generalizes several of the existing multi-relational GCN methods. We evaluate our proposed method on multiple tasks such as node classification, link prediction, and graph classification, and achieve demonstrably superior results. We make the source code of CompGCN available to foster reproducible research.
Relating Simple Sentence Representations in Deep Neural Networks and the Brain
Jun 27, 2019
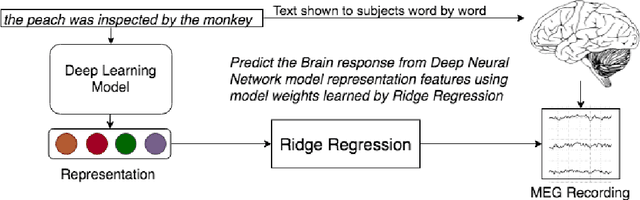
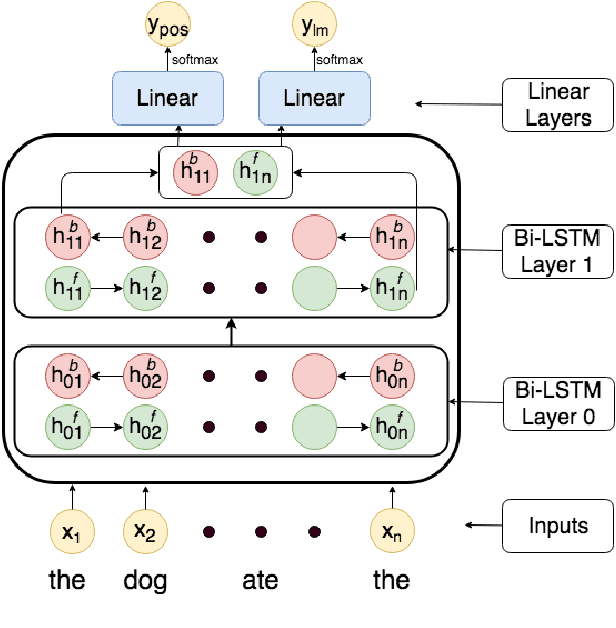
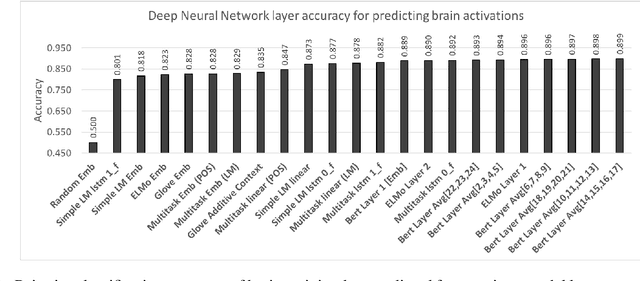
What is the relationship between sentence representations learned by deep recurrent models against those encoded by the brain? Is there any correspondence between hidden layers of these recurrent models and brain regions when processing sentences? Can these deep models be used to synthesize brain data which can then be utilized in other extrinsic tasks? We investigate these questions using sentences with simple syntax and semantics (e.g., The bone was eaten by the dog.). We consider multiple neural network architectures, including recently proposed ELMo and BERT. We use magnetoencephalography (MEG) brain recording data collected from human subjects when they were reading these simple sentences. Overall, we find that BERT's activations correlate the best with MEG brain data. We also find that the deep network representation can be used to generate brain data from new sentences to augment existing brain data. To the best of our knowledge, this is the first work showing that the MEG brain recording when reading a word in a sentence can be used to distinguish earlier words in the sentence. Our exploration is also the first to use deep neural network representations to generate synthetic brain data and to show that it helps in improving subsequent stimuli decoding task accuracy.
Dating Documents using Graph Convolution Networks
Feb 01, 2019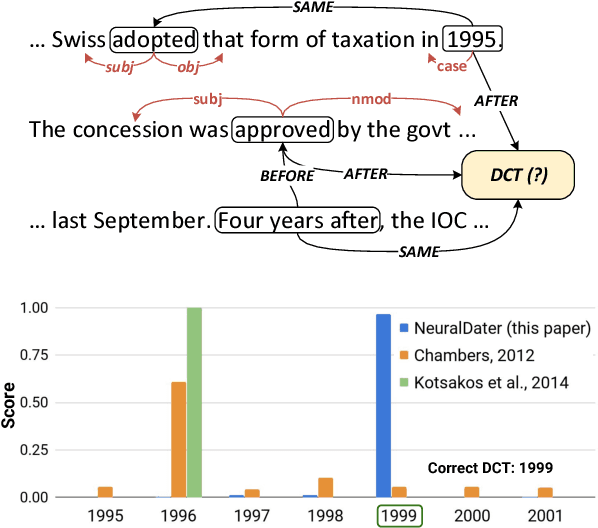
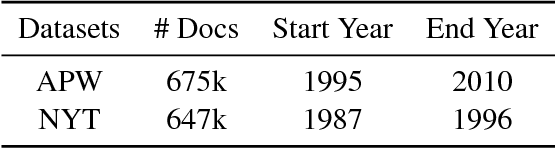
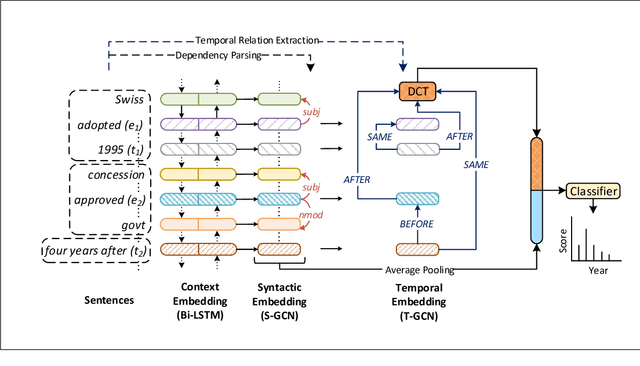
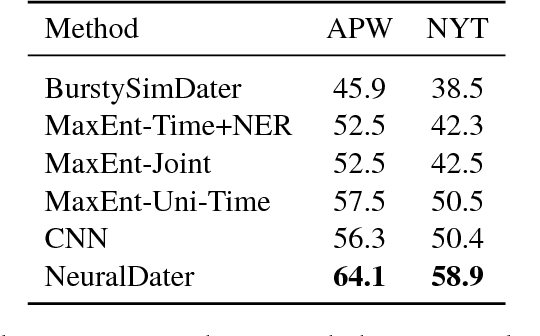
Document date is essential for many important tasks, such as document retrieval, summarization, event detection, etc. While existing approaches for these tasks assume accurate knowledge of the document date, this is not always available, especially for arbitrary documents from the Web. Document Dating is a challenging problem which requires inference over the temporal structure of the document. Prior document dating systems have largely relied on handcrafted features while ignoring such document internal structures. In this paper, we propose NeuralDater, a Graph Convolutional Network (GCN) based document dating approach which jointly exploits syntactic and temporal graph structures of document in a principled way. To the best of our knowledge, this is the first application of deep learning for the problem of document dating. Through extensive experiments on real-world datasets, we find that NeuralDater significantly outperforms state-of-the-art baseline by 19% absolute (45% relative) accuracy points.
* Accepted at ACL 2018
CESI: Canonicalizing Open Knowledge Bases using Embeddings and Side Information
Feb 01, 2019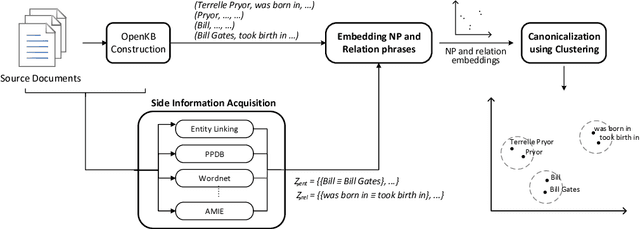
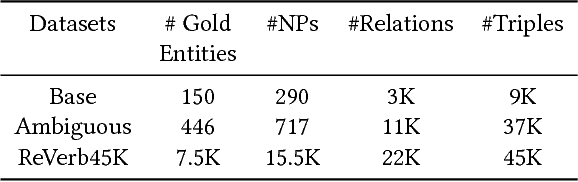
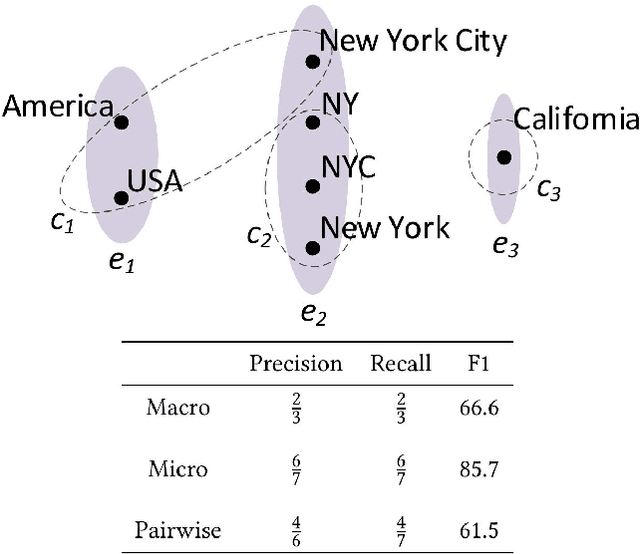
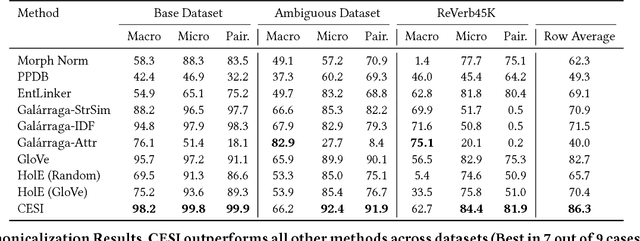
Open Information Extraction (OpenIE) methods extract (noun phrase, relation phrase, noun phrase) triples from text, resulting in the construction of large Open Knowledge Bases (Open KBs). The noun phrases (NPs) and relation phrases in such Open KBs are not canonicalized, leading to the storage of redundant and ambiguous facts. Recent research has posed canonicalization of Open KBs as clustering over manuallydefined feature spaces. Manual feature engineering is expensive and often sub-optimal. In order to overcome this challenge, we propose Canonicalization using Embeddings and Side Information (CESI) - a novel approach which performs canonicalization over learned embeddings of Open KBs. CESI extends recent advances in KB embedding by incorporating relevant NP and relation phrase side information in a principled manner. Through extensive experiments on multiple real-world datasets, we demonstrate CESI's effectiveness.
* Accepted at WWW 2018
Confidence-based Graph Convolutional Networks for Semi-Supervised Learning
Jan 24, 2019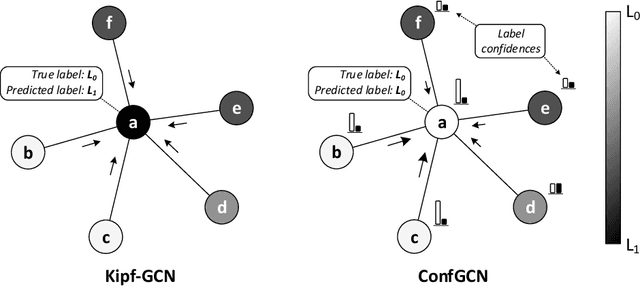
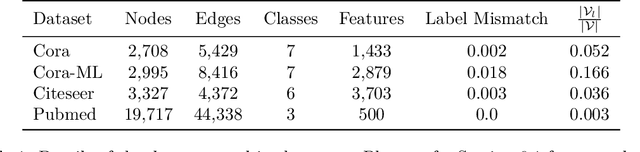
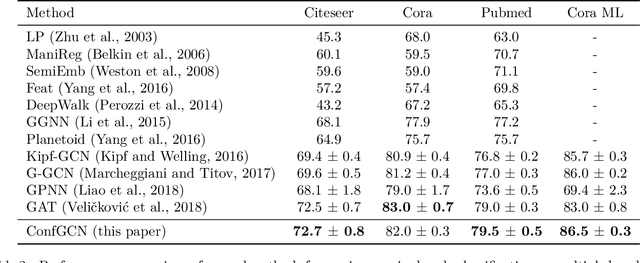
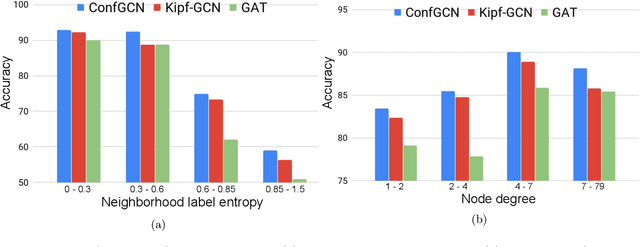
Predicting properties of nodes in a graph is an important problem with applications in a variety of domains. Graph-based Semi-Supervised Learning (SSL) methods aim to address this problem by labeling a small subset of the nodes as seeds and then utilizing the graph structure to predict label scores for the rest of the nodes in the graph. Recently, Graph Convolutional Networks (GCNs) have achieved impressive performance on the graph-based SSL task. In addition to label scores, it is also desirable to have confidence scores associated with them. Unfortunately, confidence estimation in the context of GCN has not been previously explored. We fill this important gap in this paper and propose ConfGCN, which estimates labels scores along with their confidences jointly in GCN-based setting. ConfGCN uses these estimated confidences to determine the influence of one node on another during neighborhood aggregation, thereby acquiring anisotropic capabilities. Through extensive analysis and experiments on standard benchmarks, we find that ConfGCN is able to outperform state-of-the-art baselines. We have made ConfGCN's source code available to encourage reproducible research.
RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information
Dec 11, 2018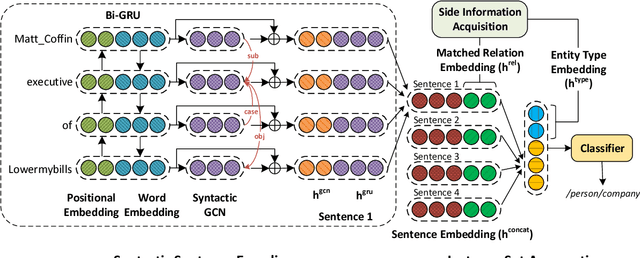
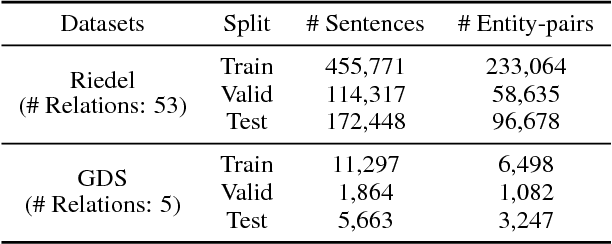
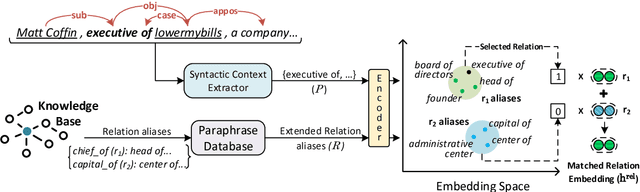

Distantly-supervised Relation Extraction (RE) methods train an extractor by automatically aligning relation instances in a Knowledge Base (KB) with unstructured text. In addition to relation instances, KBs often contain other relevant side information, such as aliases of relations (e.g., founded and co-founded are aliases for the relation founderOfCompany). RE models usually ignore such readily available side information. In this paper, we propose RESIDE, a distantly-supervised neural relation extraction method which utilizes additional side information from KBs for improved relation extraction. It uses entity type and relation alias information for imposing soft constraints while predicting relations. RESIDE employs Graph Convolution Networks (GCN) to encode syntactic information from text and improves performance even when limited side information is available. Through extensive experiments on benchmark datasets, we demonstrate RESIDE's effectiveness. We have made RESIDE's source code available to encourage reproducible research.
MT-CGCNN: Integrating Crystal Graph Convolutional Neural Network with Multitask Learning for Material Property Prediction
Nov 14, 2018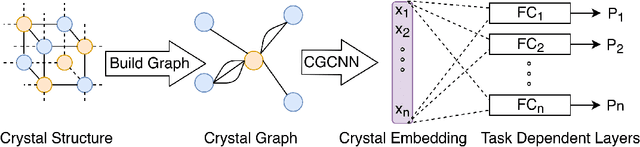

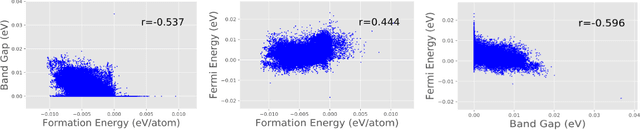
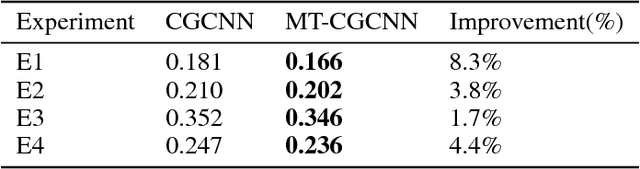
Developing accurate, transferable and computationally inexpensive machine learning models can rapidly accelerate the discovery and development of new materials. Some of the major challenges involved in developing such models are, (i) limited availability of materials data as compared to other fields, (ii) lack of universal descriptor of materials to predict its various properties. The limited availability of materials data can be addressed through transfer learning, while the generic representation was recently addressed by Xie and Grossman [1], where they developed a crystal graph convolutional neural network (CGCNN) that provides a unified representation of crystals. In this work, we develop a new model (MT-CGCNN) by integrating CGCNN with transfer learning based on multi-task (MT) learning. We demonstrate the effectiveness of MT-CGCNN by simultaneous prediction of various material properties such as Formation Energy, Band Gap and Fermi Energy for a wide range of inorganic crystals (46774 materials). MT-CGCNN is able to reduce the test error when employed on correlated properties by upto 8%. The model prediction has lower test error compared to CGCNN, even when the training data is reduced by 10%. We also demonstrate our model's better performance through prediction of end user scenario related to metal/non-metal classification. These results encourage further development of machine learning approaches which leverage multi-task learning to address the aforementioned challenges in the discovery of new materials. We make MT-CGCNN's source code available to encourage reproducible research.
Graph Convolutional Networks based Word Embeddings
Sep 12, 2018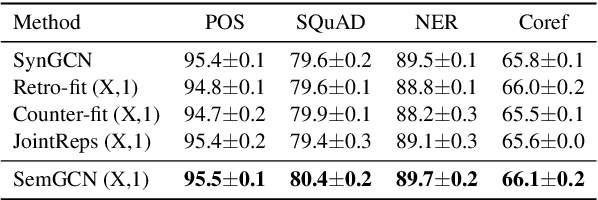
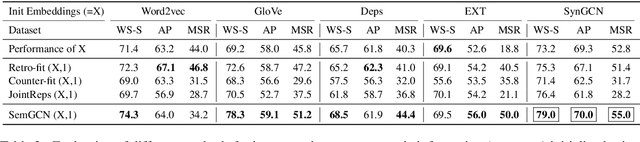
Recently, word embeddings have been widely adopted across several NLP applications. However, most word embedding methods solely rely on linear context and do not provide a framework for incorporating word relationships like hypernym, nmod in a principled manner. In this paper, we propose WordGCN, a Graph Convolution based word representation learning approach which provides a framework for exploiting multiple types of word relationships. WordGCN operates at sentence as well as corpus level and allows to incorporate dependency parse based context in an efficient manner without increasing the vocabulary size. To the best of our knowledge, this is the first approach which effectively incorporates word relationships via Graph Convolutional Networks for learning word representations. Through extensive experiments on various intrinsic and extrinsic tasks, we demonstrate WordGCN's effectiveness over existing word embedding approaches. We make WordGCN's source code available to encourage reproducible research.
HyperGCN: Hypergraph Convolutional Networks for Semi-Supervised Classification
Sep 07, 2018
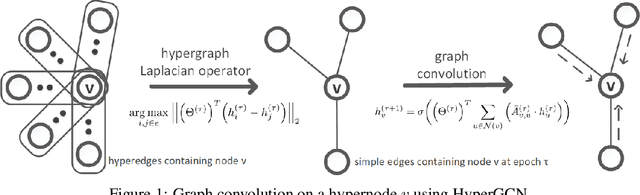

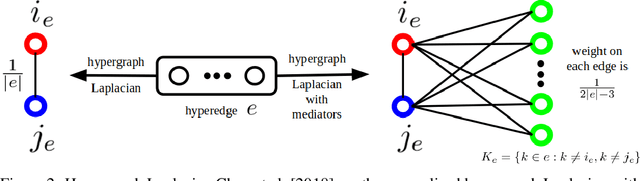
Graph-based semi-supervised learning (SSL) is an important learning problem where the goal is to assign labels to initially unlabeled nodes in a graph. Graph Convolutional Networks (GCNs) have recently been shown to be effective for graph-based SSL problems. GCNs inherently assume existence of pairwise relationships in the graph-structured data. However, in many real-world problems, relationships go beyond pairwise connections and hence are more complex. Hypergraphs provide a natural modeling tool to capture such complex relationships. In this work, we explore the use of GCNs for hypergraph-based SSL. In particular, we propose HyperGCN, an SSL method which uses a layer-wise propagation rule for convolutional neural networks operating directly on hypergraphs. To the best of our knowledge, this is the first principled adaptation of GCNs to hypergraphs. HyperGCN is able to encode both the hypergraph structure and hypernode features in an effective manner. Through detailed experimentation, we demonstrate HyperGCN's effectiveness at hypergraph-based SSL.