 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Time Domain Target Speaker Extraction with Attention
Jun 18, 2022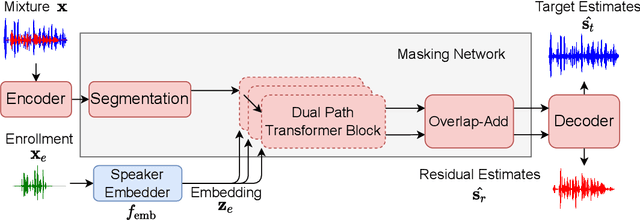

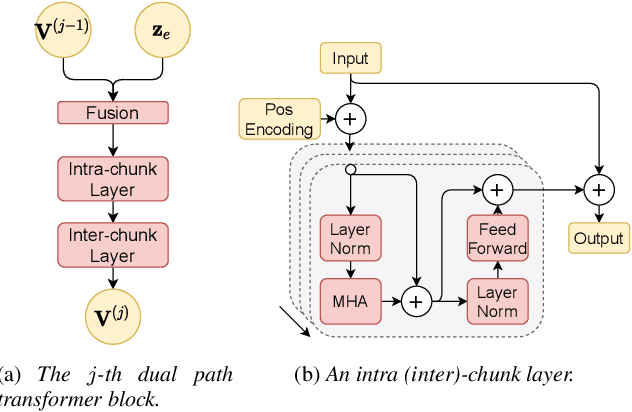
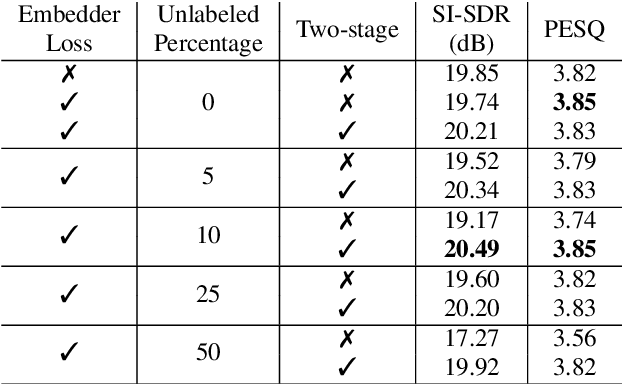
In this work, we propose Exformer, a time-domain architecture for target speaker extraction. It consists of a pre-trained speaker embedder network and a separator network based on transformer encoder blocks. We study multiple methods to combine speaker information with the input mixture, and the resulting Exformer architecture obtains superior extraction performance compared to prior time-domain networks. Furthermore, we investigate a two-stage procedure to train the model using mixtures without reference signals upon a pre-trained supervised model. Experimental results show that the proposed semi-supervised learning procedure improves the performance of the supervised baselines.
Learning Representations for New Sound Classes With Continual Self-Supervised Learning
May 15, 2022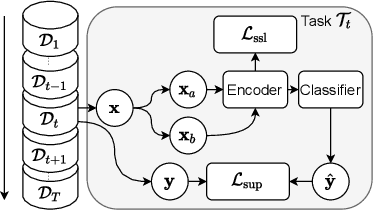
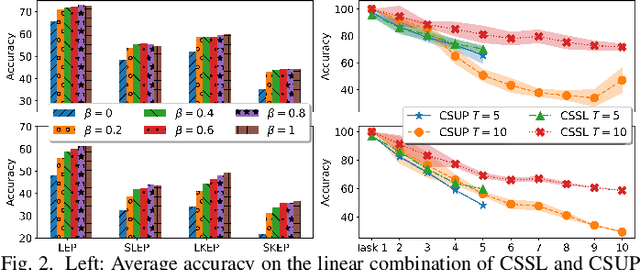
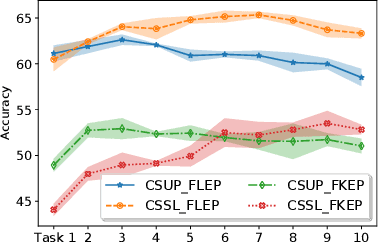
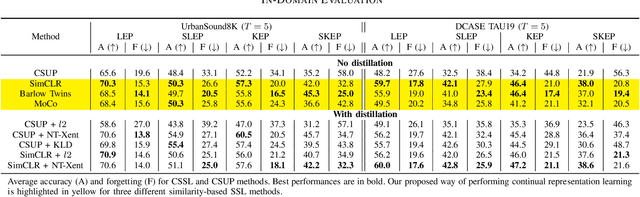
In this paper, we present a self-supervised learning framework for continually learning representations for new sound classes. The proposed system relies on a continually trained neural encoder that is trained with similarity-based learning objectives without using labels. We show that representations learned with the proposed method generalize better and are less susceptible to catastrophic forgetting than fully-supervised approaches. Remarkably, our technique does not store past data or models and is more computationally efficient than distillation-based methods. To accurately assess the system performance, in addition to using existing protocols, we propose two realistic evaluation protocols that use only a small amount of labeled data to simulate practical use cases.
Real-Time Packet Loss Concealment With Mixed Generative and Predictive Model
May 11, 2022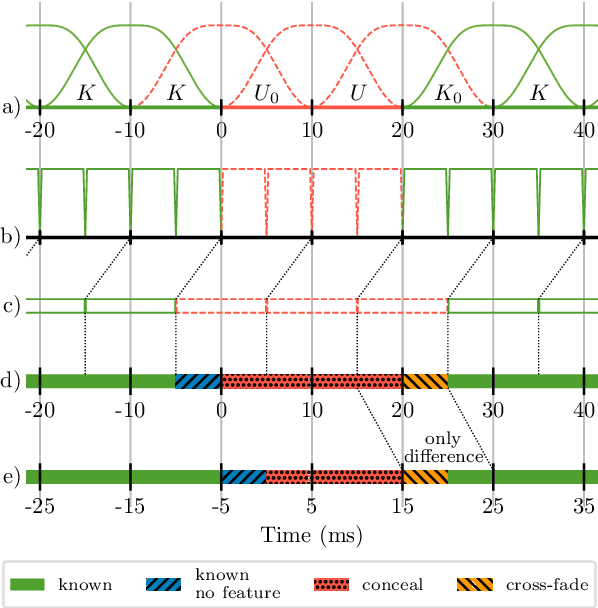

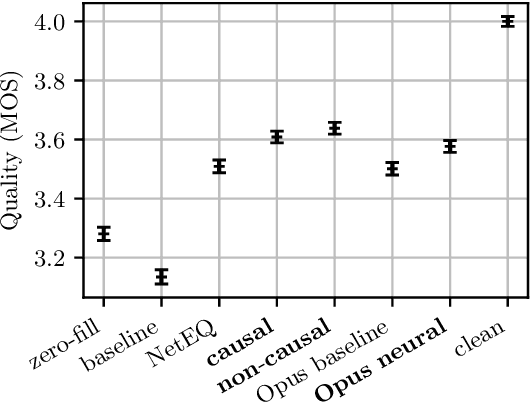
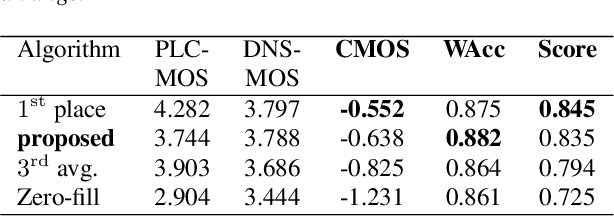
As deep speech enhancement algorithms have recently demonstrated capabilities greatly surpassing their traditional counterparts for suppressing noise, reverberation and echo, attention is turning to the problem of packet loss concealment (PLC). PLC is a challenging task because it not only involves real-time speech synthesis, but also frequent transitions between the received audio and the synthesized concealment. We propose a hybrid neural PLC architecture where the missing speech is synthesized using a generative model conditioned using a predictive model. The resulting algorithm achieves natural concealment that surpasses the quality of existing conventional PLC algorithms and ranked second in the Interspeech 2022 PLC Challenge. We show that our solution not only works for uncompressed audio, but is also applicable to a modern speech codec.
Meta-AF: Meta-Learning for Adaptive Filters
Apr 25, 2022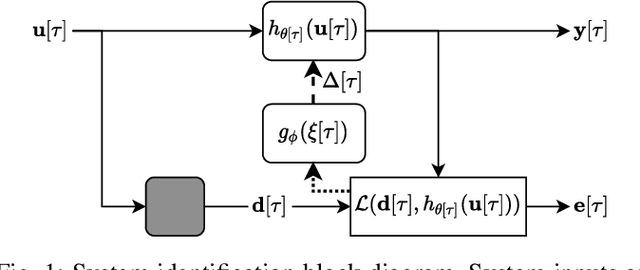
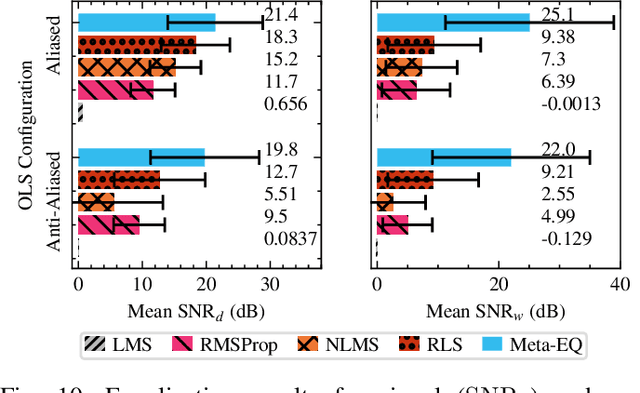
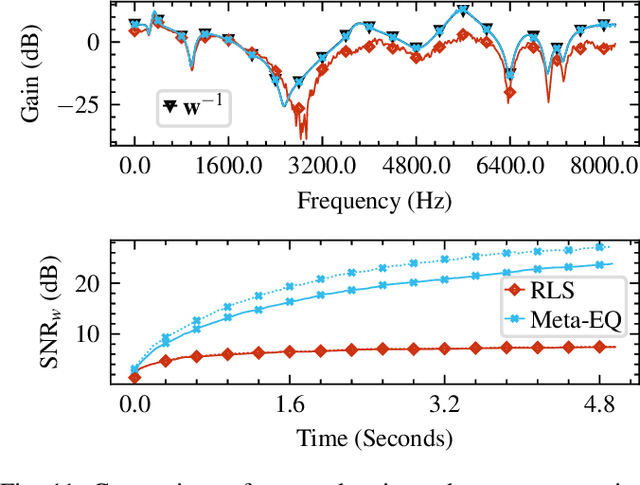
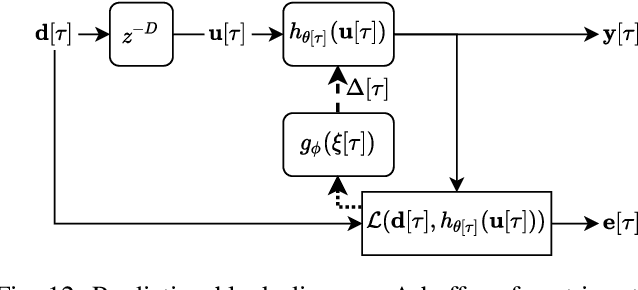
Adaptive filtering algorithms are pervasive throughout modern society and have had a significant impact on a wide variety of domains including audio processing, telecommunications, biomedical sensing, astropyhysics and cosmology, seismology, and many more. Adaptive filters typically operate via specialized online, iterative optimization methods such as least-mean squares or recursive least squares and aim to process signals in unknown or nonstationary environments. Such algorithms, however, can be slow and laborious to develop, require domain expertise to create, and necessitate mathematical insight for improvement. In this work, we seek to go beyond the limits of human-derived adaptive filter algorithms and present a comprehensive framework for learning online, adaptive signal processing algorithms or update rules directly from data. To do so, we frame the development of adaptive filters as a meta-learning problem in the context of deep learning and use a form of self-supervision to learn online iterative update rules for adaptive filters. To demonstrate our approach, we focus on audio applications and systematically develop meta-learned adaptive filters for five canonical audio problems including system identification, acoustic echo cancellation, blind equalization, multi-channel dereverberation, and beamforming. For each application, we compare against common baselines and/or current state-of-the-art methods and show we can learn high-performing adaptive filters that operate in real-time and, in most cases, significantly out perform all past specially developed methods for each task using a single general-purpose configuration of our method.
Heterogeneous Target Speech Separation
Apr 07, 2022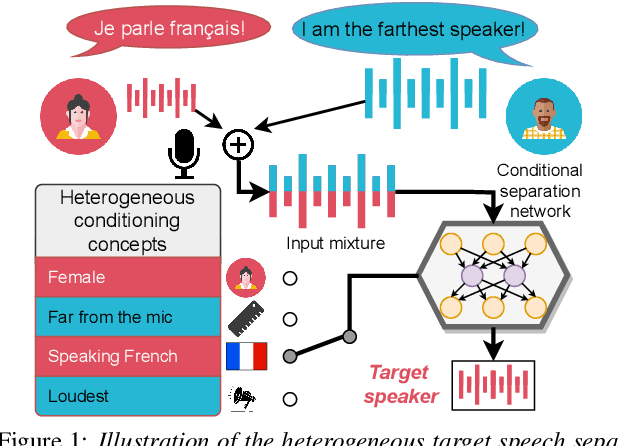
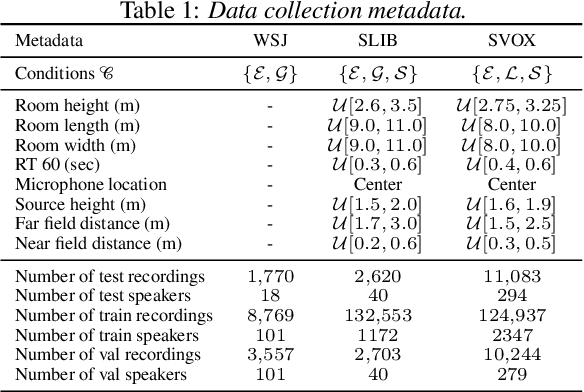
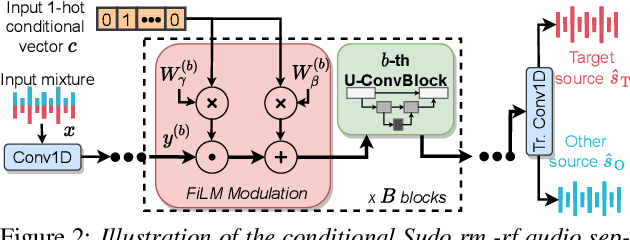
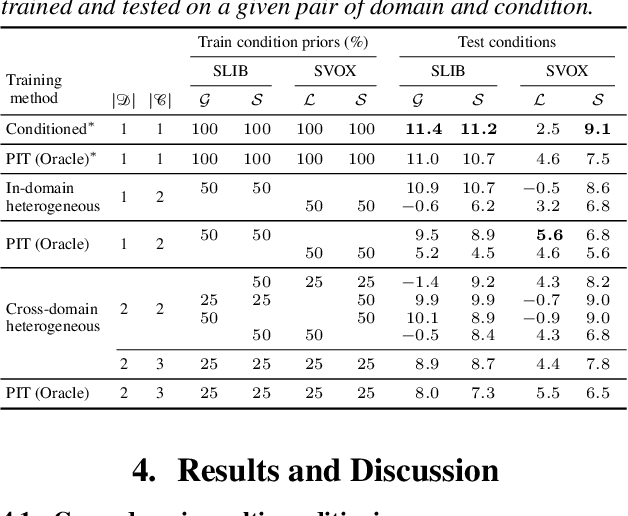
We introduce a new paradigm for single-channel target source separation where the sources of interest can be distinguished using non-mutually exclusive concepts (e.g., loudness, gender, language, spatial location, etc). Our proposed heterogeneous separation framework can seamlessly leverage datasets with large distribution shifts and learn cross-domain representations under a variety of concepts used as conditioning. Our experiments show that training separation models with heterogeneous conditions facilitates the generalization to new concepts with unseen out-of-domain data while also performing substantially higher than single-domain specialist models. Notably, such training leads to more robust learning of new harder source separation discriminative concepts and can yield improvements over permutation invariant training with oracle source selection. We analyze the intrinsic behavior of source separation training with heterogeneous metadata and propose ways to alleviate emerging problems with challenging separation conditions. We release the collection of preparation recipes for all datasets used to further promote research towards this challenging task.
End-to-end LPCNet: A Neural Vocoder With Fully-Differentiable LPC Estimation
Mar 29, 2022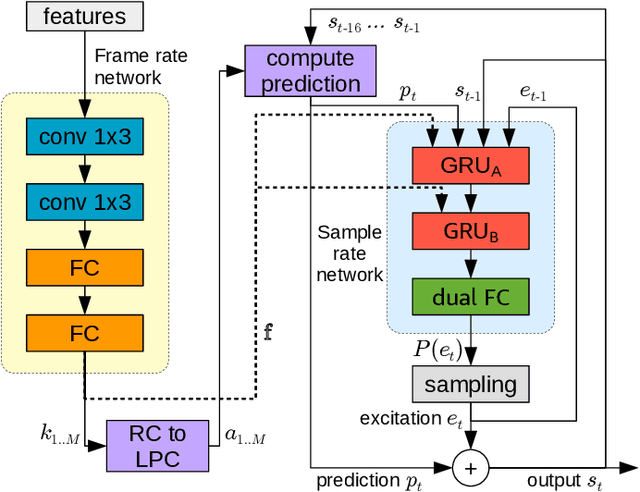
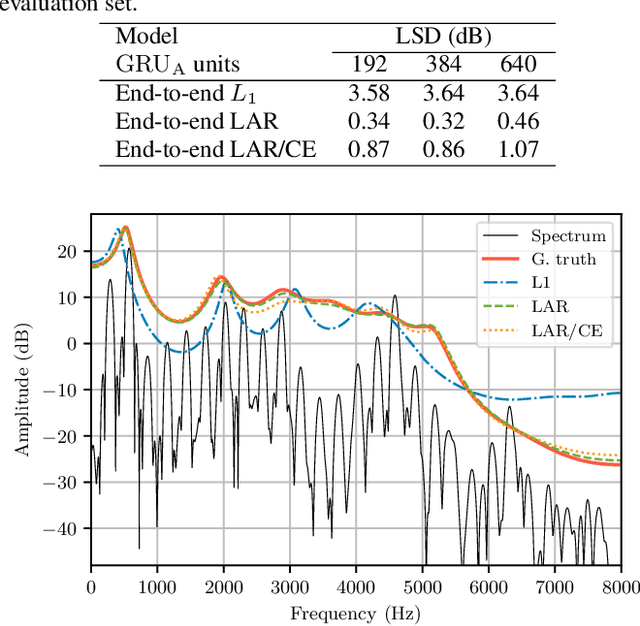
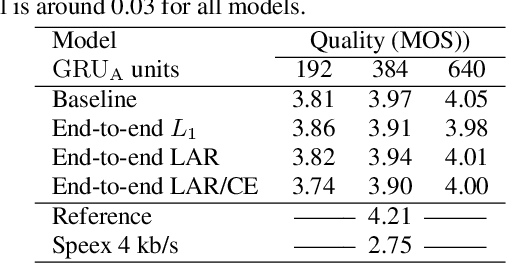
Neural vocoders have recently demonstrated high quality speech synthesis, but typically require a high computational complexity. LPCNet was proposed as a way to reduce the complexity of neural synthesis by using linear prediction (LP) to assist an autoregressive model. At inference time, LPCNet relies on the LP coefficients being explicitly computed from the input acoustic features. That makes the design of LPCNet-based systems more complicated, while adding the constraint that the input features must represent a clean speech spectrum. We propose an end-to-end version of LPCNet that lifts these limitations by learning to infer the LP coefficients from the input features in the frame rate network. Results show that the proposed end-to-end approach equals or exceeds the quality of the original LPCNet model, but without explicit LP analysis. Our open-source end-to-end model still benefits from LPCNet's low complexity, while allowing for any type of conditioning features.
Neural Speech Synthesis on a Shoestring: Improving the Efficiency of LPCNet
Feb 22, 2022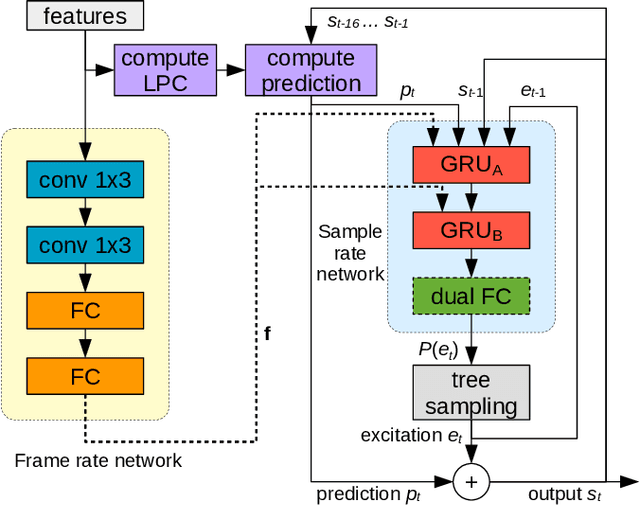
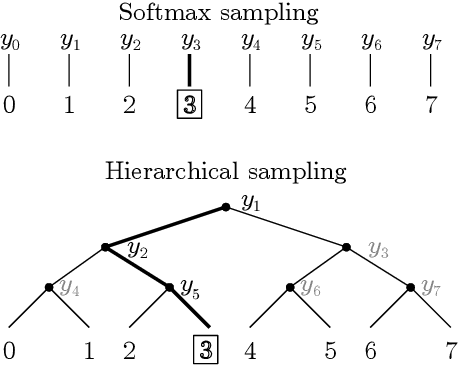
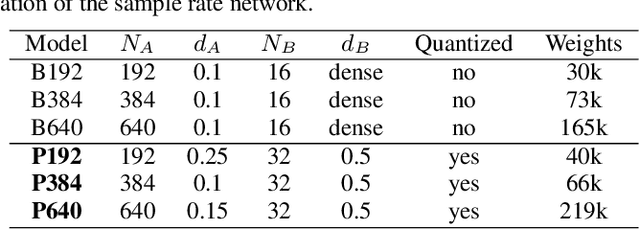
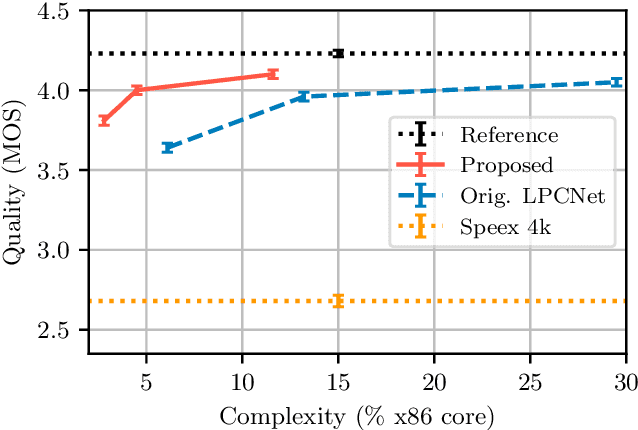
Neural speech synthesis models can synthesize high quality speech but typically require a high computational complexity to do so. In previous work, we introduced LPCNet, which uses linear prediction to significantly reduce the complexity of neural synthesis. In this work, we further improve the efficiency of LPCNet -- targeting both algorithmic and computational improvements -- to make it usable on a wide variety of devices. We demonstrate an improvement in synthesis quality while operating 2.5x faster. The resulting open-source LPCNet algorithm can perform real-time neural synthesis on most existing phones and is even usable in some embedded devices.
RemixIT: Continual self-training of speech enhancement models via bootstrapped remixing
Feb 22, 2022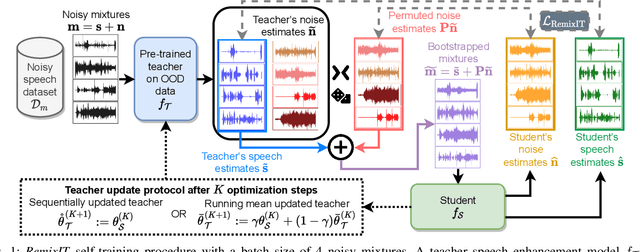
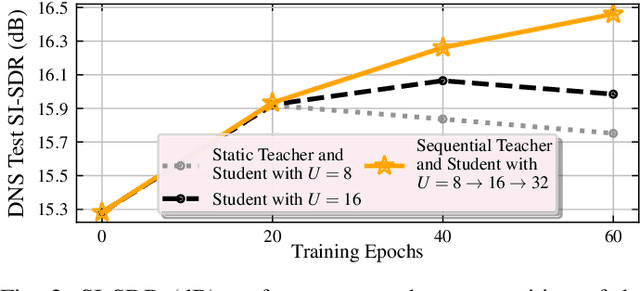
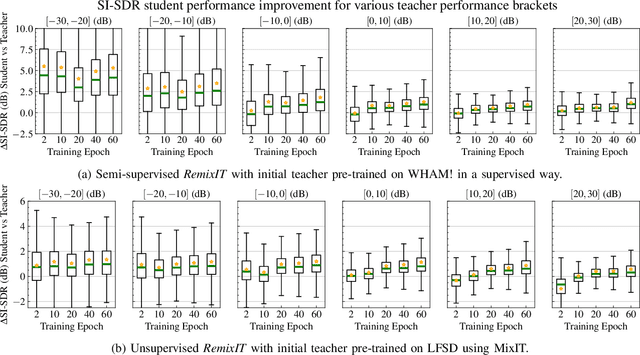
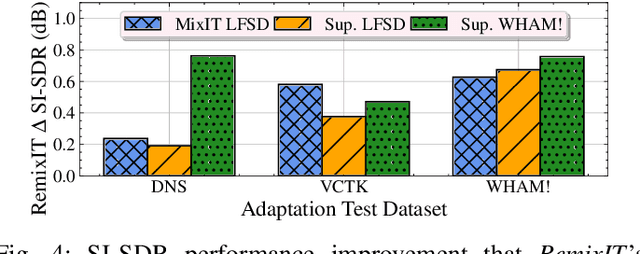
We present RemixIT, a simple yet effective self-supervised method for training speech enhancement without the need of a single isolated in-domain speech nor a noise waveform. Our approach overcomes limitations of previous methods which make them dependent on clean in-domain target signals and thus, sensitive to any domain mismatch between train and test samples. RemixIT is based on a continuous self-training scheme in which a pre-trained teacher model on out-of-domain data infers estimated pseudo-target signals for in-domain mixtures. Then, by permuting the estimated clean and noise signals and remixing them together, we generate a new set of bootstrapped mixtures and corresponding pseudo-targets which are used to train the student network. Vice-versa, the teacher periodically refines its estimates using the updated parameters of the latest student models. Experimental results on multiple speech enhancement datasets and tasks not only show the superiority of our method over prior approaches but also showcase that RemixIT can be combined with any separation model as well as be applied towards any semi-supervised and unsupervised domain adaptation task. Our analysis, paired with empirical evidence, sheds light on the inside functioning of our self-training scheme wherein the student model keeps obtaining better performance while observing severely degraded pseudo-targets.
Auto-DSP: Learning to Optimize Acoustic Echo Cancellers
Oct 08, 2021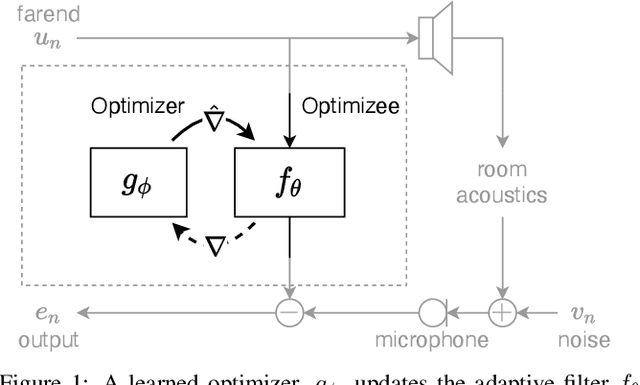
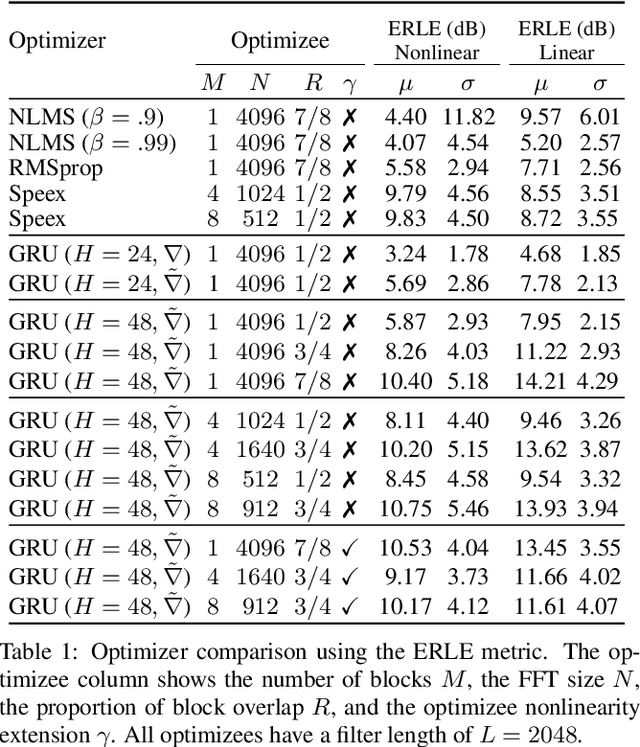
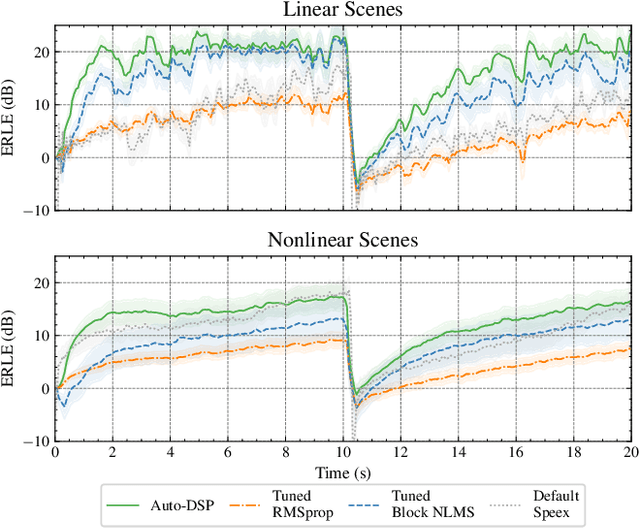
Adaptive filtering algorithms are commonplace in signal processing and have wide-ranging applications from single-channel denoising to multi-channel acoustic echo cancellation and adaptive beamforming. Such algorithms typically operate via specialized online, iterative optimization methods and have achieved tremendous success, but require expert knowledge, are slow to develop, and are difficult to customize. In our work, we present a new method to automatically learn adaptive filtering update rules directly from data. To do so, we frame adaptive filtering as a differentiable operator and train a learned optimizer to output a gradient descent-based update rule from data via backpropagation through time. We demonstrate our general approach on an acoustic echo cancellation task (single-talk with noise) and show that we can learn high-performing adaptive filters for a variety of common linear and non-linear multidelayed block frequency domain filter architectures. We also find that our learned update rules exhibit fast convergence, can optimize in the presence of nonlinearities, and are robust to acoustic scene changes despite never encountering any during training.
Sound Event Detection with Adaptive Frequency Selection
May 17, 2021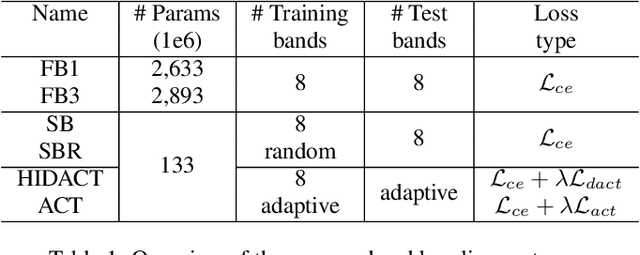
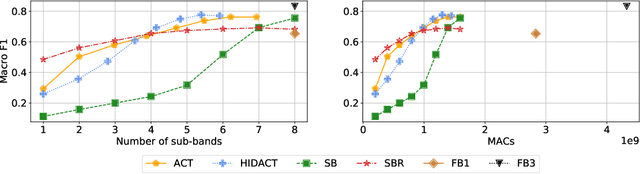
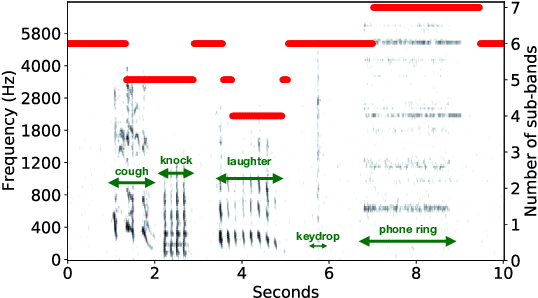
In this work, we present HIDACT, a novel network architecture for adaptive computation for efficiently recognizing acoustic events. We evaluate the model on a sound event detection task where we train it to adaptively process frequency bands. The model learns to adapt to the input without requesting all frequency sub-bands provided. It can make confident predictions within fewer processing steps, hence reducing the amount of computation. Experimental results show that HIDACT has comparable performance to baseline models with more parameters and higher computational complexity. Furthermore, the model can adjust the amount of computation based on the data and computational budget.