 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSABER: A Scalable Action-Based Embodied Dataset for Real-World VLA Adaptation
May 10, 2026Robotic deployment in real-world environments depends on rich, domain-specific action data as much as on strong model architecture. General-purpose robot foundation models show modest performance in complex unseen tasks such as manipulation in a retail domain when applied out of the box. The root cause is a data gap: retail environments are structurally absent from general robot pretraining distributions, and the path to filling that gap through teleoperation is prohibitively expensive, logistically constrained, and difficult to scale. We introduce SABER, a high-fidelity retail robotics action dataset built from over 100 hours of natural in-store capture across multiple real grocery environments. Egocentric footage from head-mounted cameras records fine-grained hand activity at the point of interaction, while exocentric 360-degree scene footage from DreamVu's ALIA camera simultaneously observes all actors and activities across the entire space. This combination yields a uniquely complete picture of human retail behavior: dexterous hand activity, whole-body motion, and scene dynamics, all captured without staging, scripting, or teleoperation overhead. The SABER corpus contains 44.8K training samples across three action representation streams: 25K latent action sequences via LAPA-style encoding, 18.6K dexterous hand-pose trajectories retargeted to robot joint space, and 1.2K whole-body synchronized motion sequences retargeted to a humanoid embodiment. When applied to GR00T N1.6 via a shared-backbone multi-task post-training recipe, SABER yields a mean success rate of 29.3% across ten retail manipulation tasks -- more than 2.19x over fine-tuning baselines (13.4%). SABER demonstrates that the path to capable retail robots runs through better data, which can be collected today, at scale, without a robot in the loop. The dataset and code are available at https://dreamvu.ai/saber
PRISM: A Multi-View Multi-Capability Retail Video Dataset for Embodied Vision-Language Models
Mar 31, 2026A critical gap exists between the general-purpose visual understanding of state-of-the-art physical AI models and the specialized perceptual demands of structured real-world deployment environments. We present PRISM, a 270K-sample multi-view video supervised fine-tuning (SFT) corpus for embodied vision-language-models (VLMs) in real-world retail environments. PRISM is motivated by a simple observation - physical AI systems fail not because of poor visual recognition, but because they do not understand space, physical dynamics and embodied action well enough to operate reliably in the world. To this end, PRISM is grounded in a novel three-dimensional knowledge ontology that spans spatial knowledge, temporal and physical knowledge, and embodied action knowledge. It covers 20+ capability probes across four evaluation dimensions - Embodied Reasoning (ER), Common Sense (CS), Spatial Perception (SP), and Intuitive Physics (IP), and to our knowledge, PRISM is the first dataset to instantiate all three knowledge dimensions within a single real-world deployment domain. The corpus captures data from egocentric, exocentric and 360° viewpoints across five supermarket locations and includes open-ended, chain-of-thought, and multiple-choice supervision. At 4 fps, PRISM spans approximately 11.8M video frames and approximately 730M tokens, placing it among the largest domain-specific video SFT corpora. Fine-tuning on PRISM reduces the error rate across all 20+ probes by 66.6% over the pre-trained baseline, with significant gains in embodied action understanding where the accuracy improves by 36.4%. Our results suggest that ontology-structured, domain specific SFT can meaningfully strengthen embodied VLMs for real-world settings. The PRISM dataset and more details are available at https://dreamvu.ai/prism
Appearance Editing with Free-viewpoint Neural Rendering
Oct 14, 2021
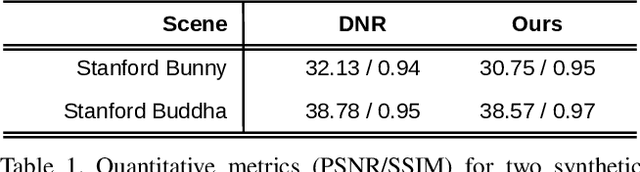
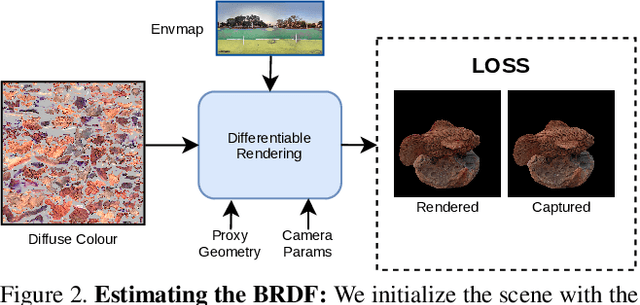

We present a neural rendering framework for simultaneous view synthesis and appearance editing of a scene from multi-view images captured under known environment illumination. Existing approaches either achieve view synthesis alone or view synthesis along with relighting, without direct control over the scene's appearance. Our approach explicitly disentangles the appearance and learns a lighting representation that is independent of it. Specifically, we independently estimate the BRDF and use it to learn a lighting-only representation of the scene. Such disentanglement allows our approach to generalize to arbitrary changes in appearance while performing view synthesis. We show results of editing the appearance of a real scene, demonstrating that our approach produces plausible appearance editing. The performance of our view synthesis approach is demonstrated to be at par with state-of-the-art approaches on both real and synthetic data.
Geometric Scene Refocusing
Dec 20, 2020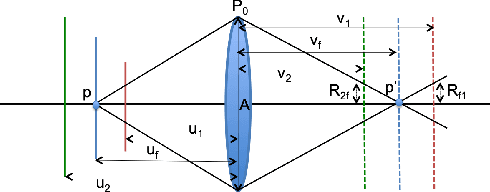
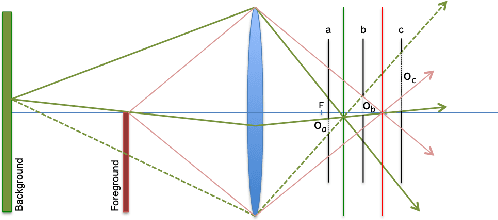

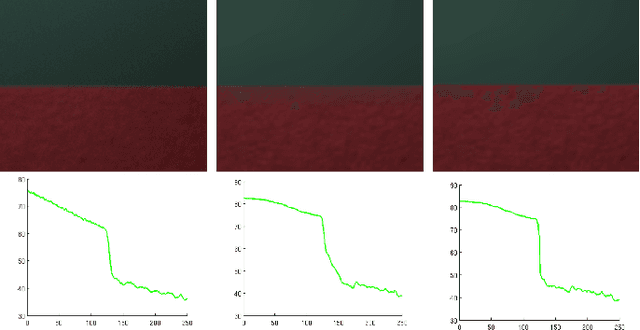
An image captured with a wide-aperture camera exhibits a finite depth-of-field, with focused and defocused pixels. A compact and robust representation of focus and defocus helps analyze and manipulate such images. In this work, we study the fine characteristics of images with a shallow depth-of-field in the context of focal stacks. We present a composite measure for focus that is a combination of existing measures. We identify in-focus pixels, dual-focus pixels, pixels that exhibit bokeh and spatially-varying blur kernels between focal slices. We use these to build a novel representation that facilitates easy manipulation of focal stacks. We present a comprehensive algorithm for post-capture refocusing in a geometrically correct manner. Our approach can refocus the scene at high fidelity while preserving fine aspects of focus and defocus blur.