 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Face and Object Recognition Independent? A Neurocomputational Modeling Exploration
Apr 26, 2016Are face and object recognition abilities independent? Although it is commonly believed that they are, Gauthier et al.(2014) recently showed that these abilities become more correlated as experience with nonface categories increases. They argued that there is a single underlying visual ability, v, that is expressed in performance with both face and nonface categories as experience grows. Using the Cambridge Face Memory Test and the Vanderbilt Expertise Test, they showed that the shared variance between Cambridge Face Memory Test and Vanderbilt Expertise Test performance increases monotonically as experience increases. Here, we address why a shared resource across different visual domains does not lead to competition and to an inverse correlation in abilities? We explain this conundrum using our neurocomputational model of face and object processing (The Model, TM). Our results show that, as in the behavioral data, the correlation between subordinate level face and object recognition accuracy increases as experience grows. We suggest that different domains do not compete for resources because the relevant features are shared between faces and objects. The essential power of experience is to generate a "spreading transform" for faces that generalizes to objects that must be individuated. Interestingly, when the task of the network is basic level categorization, no increase in the correlation between domains is observed. Hence, our model predicts that it is the type of experience that matters and that the source of the correlation is in the fusiform face area, rather than in cortical areas that subserve basic level categorization. This result is consistent with our previous modeling elucidating why the FFA is recruited for novel domains of expertise (Tong et al., 2008).
Modeling the Contribution of Central Versus Peripheral Vision in Scene, Object, and Face Recognition
Apr 25, 2016
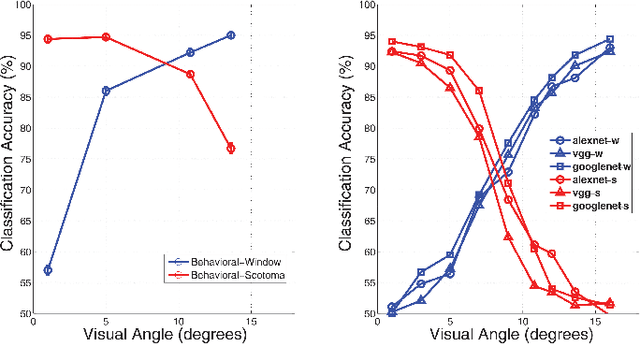
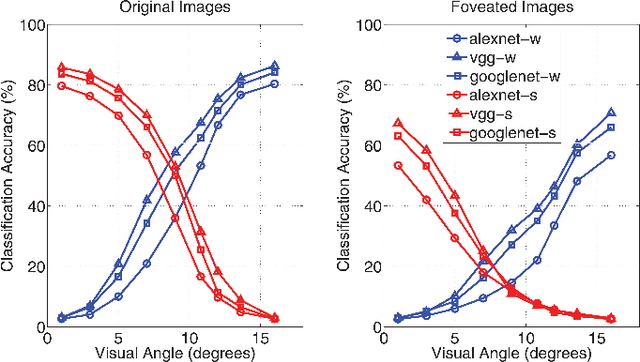
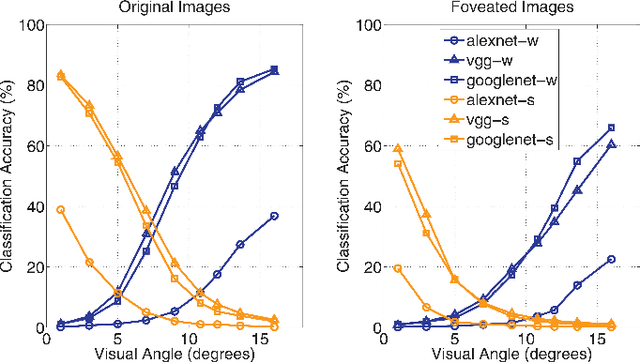
It is commonly believed that the central visual field is important for recognizing objects and faces, and the peripheral region is useful for scene recognition. However, the relative importance of central versus peripheral information for object, scene, and face recognition is unclear. In a behavioral study, Larson and Loschky (2009) investigated this question by measuring the scene recognition accuracy as a function of visual angle, and demonstrated that peripheral vision was indeed more useful in recognizing scenes than central vision. In this work, we modeled and replicated the result of Larson and Loschky (2009), using deep convolutional neural networks. Having fit the data for scenes, we used the model to predict future data for large-scale scene recognition as well as for objects and faces. Our results suggest that the relative order of importance of using central visual field information is face recognition>object recognition>scene recognition, and vice-versa for peripheral information.
Basic Level Categorization Facilitates Visual Object Recognition
Jan 07, 2016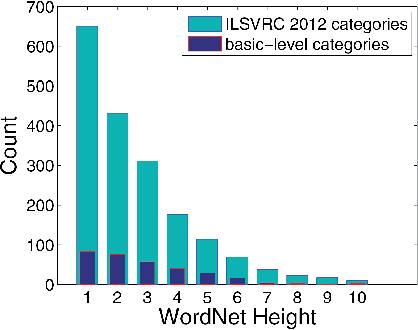
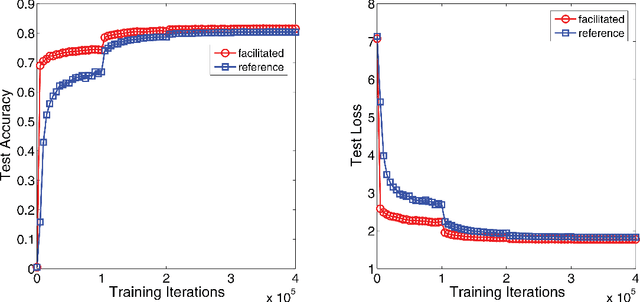
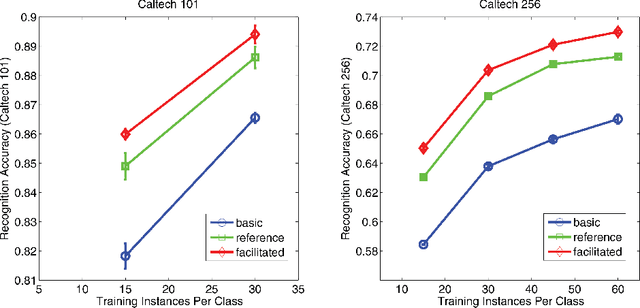
Recent advances in deep learning have led to significant progress in the computer vision field, especially for visual object recognition tasks. The features useful for object classification are learned by feed-forward deep convolutional neural networks (CNNs) automatically, and they are shown to be able to predict and decode neural representations in the ventral visual pathway of humans and monkeys. However, despite the huge amount of work on optimizing CNNs, there has not been much research focused on linking CNNs with guiding principles from the human visual cortex. In this work, we propose a network optimization strategy inspired by both of the developmental trajectory of children's visual object recognition capabilities, and Bar (2003), who hypothesized that basic level information is carried in the fast magnocellular pathway through the prefrontal cortex (PFC) and then projected back to inferior temporal cortex (IT), where subordinate level categorization is achieved. We instantiate this idea by training a deep CNN to perform basic level object categorization first, and then train it on subordinate level categorization. We apply this idea to training AlexNet (Krizhevsky et al., 2012) on the ILSVRC 2012 dataset and show that the top-5 accuracy increases from 80.13% to 82.14%, demonstrating the effectiveness of the method. We also show that subsequent transfer learning on smaller datasets gives superior results.
Suspicious Object Recognition Method in Video Stream Based on Visual Attention
Aug 23, 2013
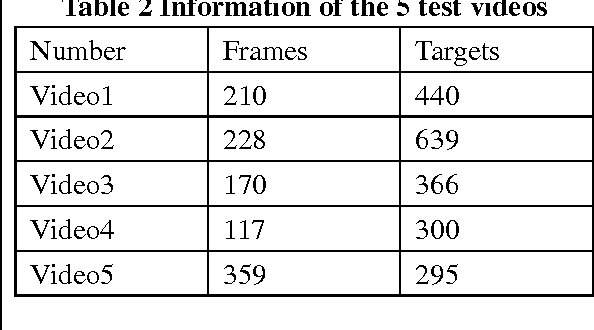
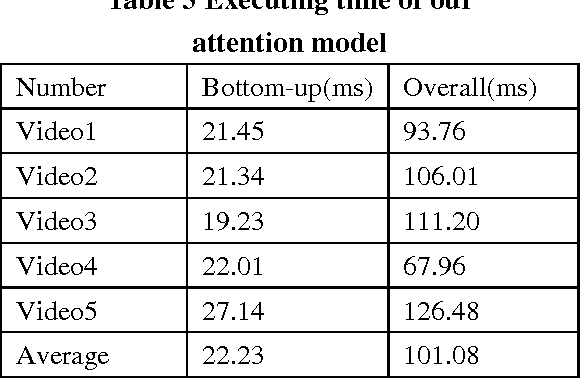
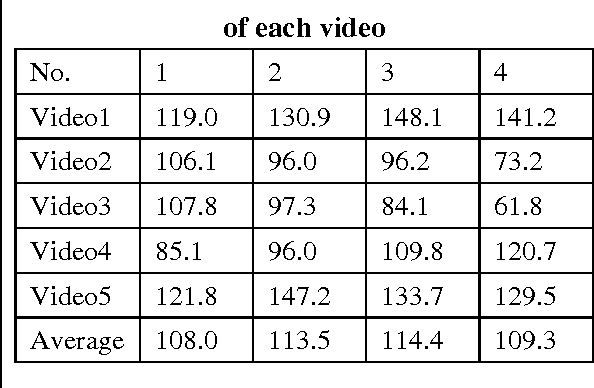
We propose a state of the art method for intelligent object recognition and video surveillance based on human visual attention. Bottom up and top down attention are applied respectively in the process of acquiring interested object(saliency map) and object recognition. The revision of 4 channel PFT method is proposed for bottom up attention and enhances the speed and accuracy. Inhibit of return (IOR) is applied in judging the sequence of saliency object pop out. Euclidean distance of color distribution, object center coordinates and speed are considered in judging whether the target is match and suspicious. The extensive tests on videos and images show that our method in video analysis has high accuracy and fast speed compared with traditional method. The method can be applied into many fields such as video surveillance and security.