 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorst-case Optimal Submodular Extensions for Marginal Estimation
Jan 10, 2018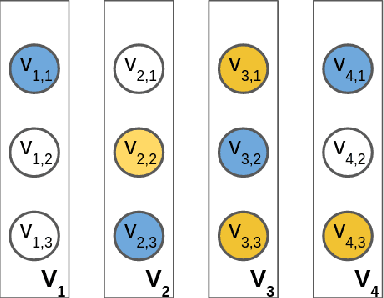
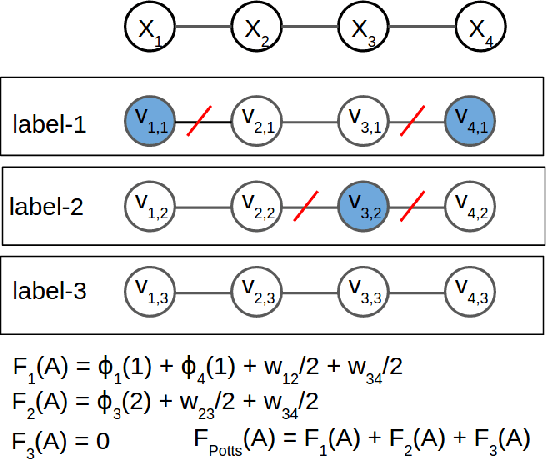
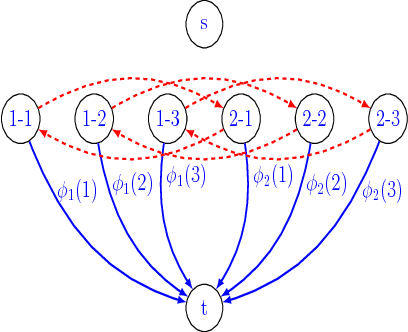
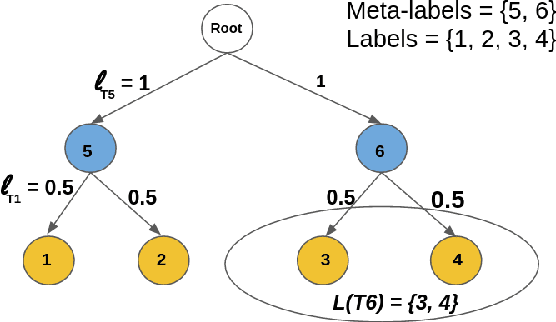
Submodular extensions of an energy function can be used to efficiently compute approximate marginals via variational inference. The accuracy of the marginals depends crucially on the quality of the submodular extension. To identify the best possible extension, we show an equivalence between the submodular extensions of the energy and the objective functions of linear programming (LP) relaxations for the corresponding MAP estimation problem. This allows us to (i) establish the worst-case optimality of the submodular extension for Potts model used in the literature; (ii) identify the worst-case optimal submodular extension for the more general class of metric labeling; and (iii) efficiently compute the marginals for the widely used dense CRF model with the help of a recently proposed Gaussian filtering method. Using synthetic and real data, we show that our approach provides comparable upper bounds on the log-partition function to those obtained using tree-reweighted message passing (TRW) in cases where the latter is computationally feasible. Importantly, unlike TRW, our approach provides the first practical algorithm to compute an upper bound on the dense CRF model.
Truncated Max-of-Convex Models
Dec 03, 2016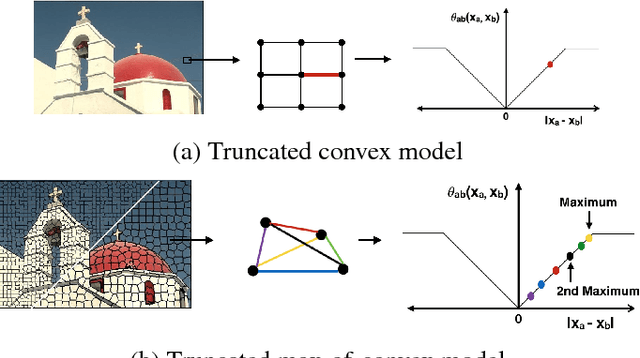


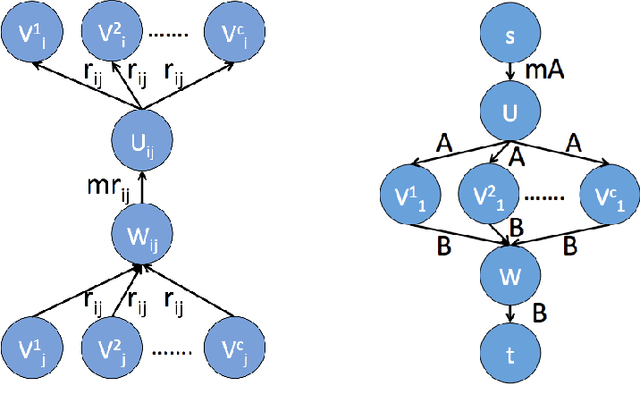
Truncated convex models (TCM) are a special case of pairwise random fields that have been widely used in computer vision. However, by restricting the order of the potentials to be at most two, they fail to capture useful image statistics. We propose a natural generalization of TCM to high-order random fields, which we call truncated max-of-convex models (TMCM). The energy function of TMCM consistsof two types of potentials: (i) unary potential, which has no restriction on its form; and (ii) clique potential, which is the sum of the m largest truncated convex distances over all label pairs in a clique. The use of a convex distance function encourages smoothness, while truncation allows for discontinuities in the labeling. By using m > 1, TMCM provides robustness towards errors in the definition of the cliques. In order to minimize the energy function of a TMCM over all possible labelings, we design an efficient st-MINCUT based range expansion algorithm. We prove the accuracy of our algorithm by establishing strong multiplicative bounds for several special cases of interest. Using synthetic and standard real data sets, we demonstrate the benefit of our high-order TMCM over pairwise TCM, as well as the benefit of our range expansion algorithm over other st-MINCUT based approaches.