 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong Neural Topic Learning in Contextualized Autoregressive Topic Models of Language via Informative Transfers
Sep 29, 2019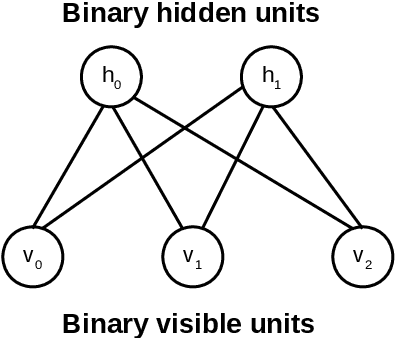
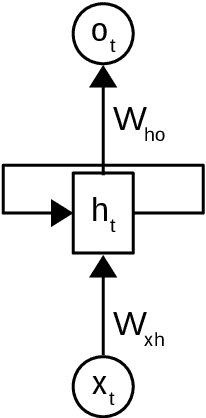
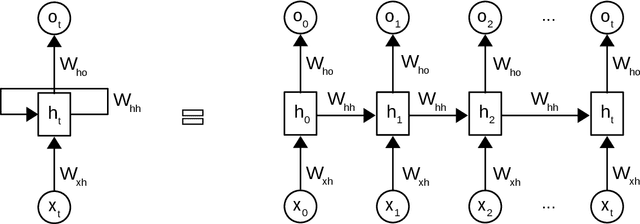
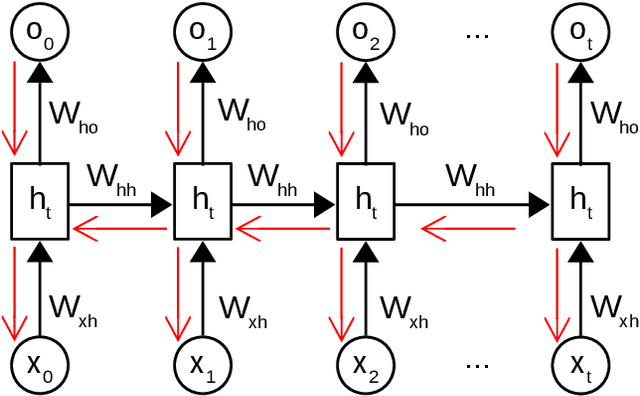
Topic models such as LDA, DocNADE, iDocNADEe have been popular in document analysis. However, the traditional topic models have several limitations including: (1) Bag-of-words (BoW) assumption, where they ignore word ordering, (2) Data sparsity, where the application of topic models is challenging due to limited word co-occurrences, leading to incoherent topics and (3) No Continuous Learning framework for topic learning in lifelong fashion, exploiting historical knowledge (or latent topics) and minimizing catastrophic forgetting. This thesis focuses on addressing the above challenges within neural topic modeling framework. We propose: (1) Contextualized topic model that combines a topic and a language model and introduces linguistic structures (such as word ordering, syntactic and semantic features, etc.) in topic modeling, (2) A novel lifelong learning mechanism into neural topic modeling framework to demonstrate continuous learning in sequential document collections and minimizing catastrophic forgetting. Additionally, we perform a selective data augmentation to alleviate the need for complete historical corpora during data hallucination or replay.
Multi-view and Multi-source Transfers in Neural Topic Modeling with Pretrained Topic and Word Embeddings
Sep 17, 2019
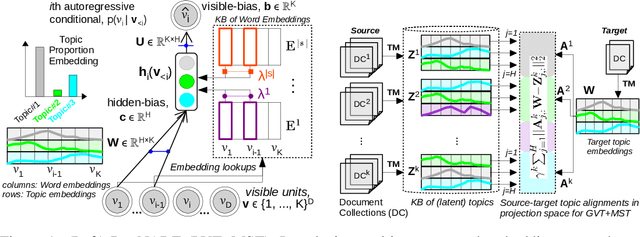
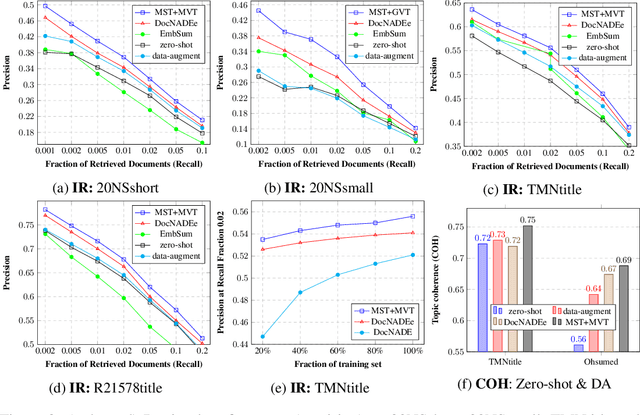
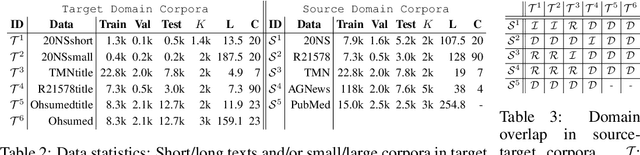
Though word embeddings and topics are complementary representations, several past works have only used pre-trained word embeddings in (neural) topic modeling to address data sparsity problem in short text or small collection of documents. However, no prior work has employed (pre-trained latent) topics in transfer learning paradigm. In this paper, we propose an approach to (1) perform knowledge transfer using latent topics obtained from a large source corpus, and (2) jointly transfer knowledge via the two representations (or views) in neural topic modeling to improve topic quality, better deal with polysemy and data sparsity issues in a target corpus. In doing so, we first accumulate topics and word representations from one or many source corpora to build a pool of topics and word vectors. Then, we identify one or multiple relevant source domain(s) and take advantage of corresponding topics and word features via the respective pools to guide meaningful learning in the sparse target domain. We quantify the quality of topic and document representations via generalization (perplexity), interpretability (topic coherence) and information retrieval (IR) using short-text, long-text, small and large document collections from news and medical domains. We have demonstrated the state-of-the-art results on topic modeling with the proposed framework.
Neural Architectures for Fine-Grained Propaganda Detection in News
Sep 13, 2019
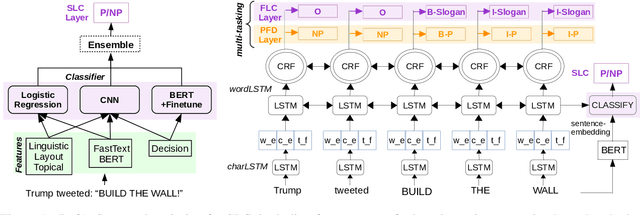
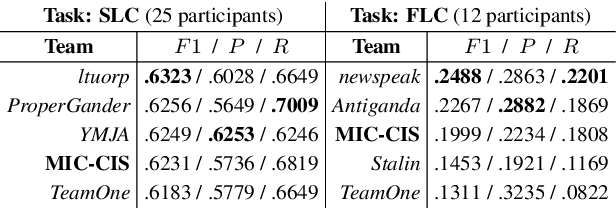
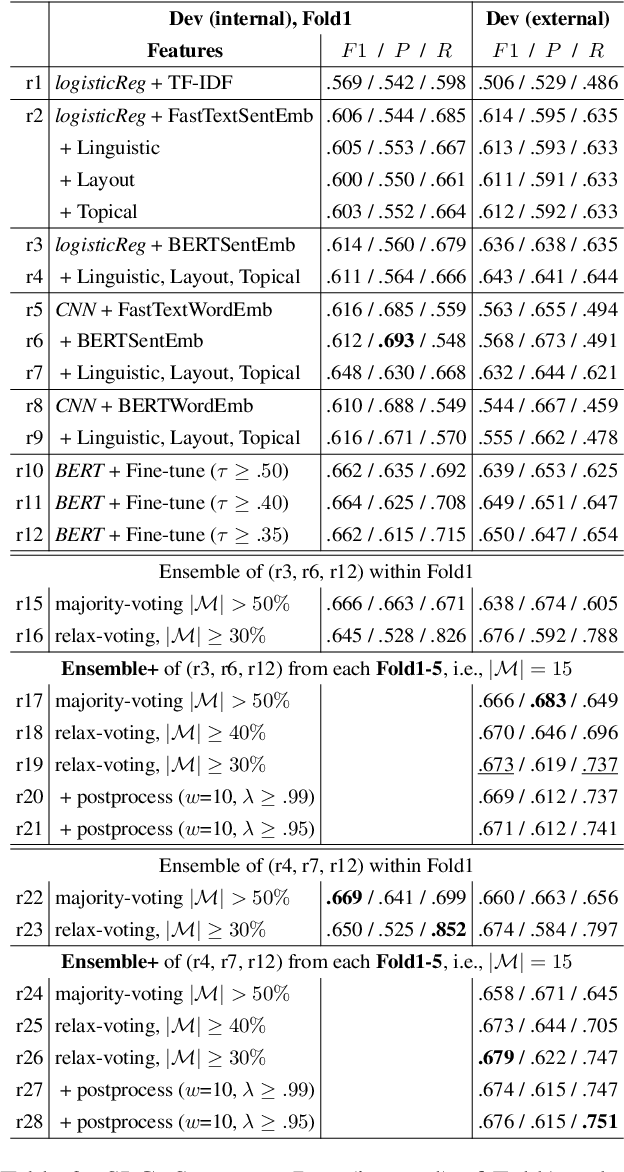
This paper describes our system (MIC-CIS) details and results of participation in the fine-grained propaganda detection shared task 2019. To address the tasks of sentence (SLC) and fragment level (FLC) propaganda detection, we explore different neural architectures (e.g., CNN, LSTM-CRF and BERT) and extract linguistic (e.g., part-of-speech, named entity, readability, sentiment, emotion, etc.), layout and topical features. Specifically, we have designed multi-granularity and multi-tasking neural architectures to jointly perform both the sentence and fragment level propaganda detection. Additionally, we investigate different ensemble schemes such as majority-voting, relax-voting, etc. to boost overall system performance. Compared to the other participating systems, our submissions are ranked 3rd and 4th in FLC and SLC tasks, respectively.
Neural Relation Extraction Within and Across Sentence Boundaries
Oct 11, 2018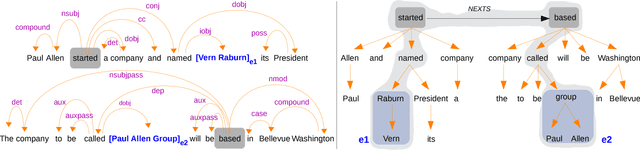
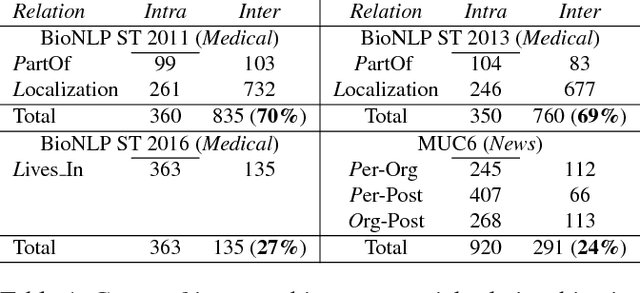
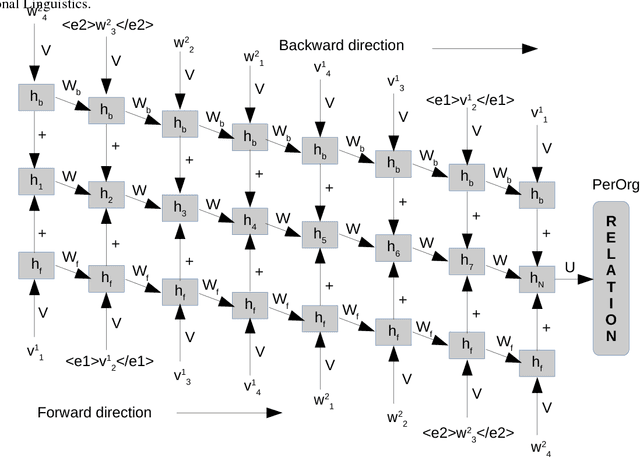
Past work in relation extraction mostly focuses on binary relation between entity pairs within single sentence. Recently, the NLP community has gained interest in relation extraction in entity pairs spanning multiple sentences. In this paper, we propose a novel architecture for this task: inter-sentential dependency-based neural networks (iDepNN). iDepNN models the shortest and augmented dependency paths via recurrent and recursive neural networks to extract relationships within (intra-) and across (inter-) sentence boundaries. Compared to SVM and neural network baselines, iDepNN is more robust to false positives in relationships spanning sentences. We evaluate our models on four datasets from newswire (MUC6) and medical (BioNLP shared task) domains that achieve state-of-the-art performance and show a better balance in precision and recall for inter-sentential relationships. We perform better than 11 teams participating in the BioNLP shared task 2016 and achieve a gain of 5.2% (0.587 vs 0.558) in F1 over the winning team. We also release the crosssentence annotations for MUC6.
textTOvec: Deep Contextualized Neural Autoregressive Models of Language with Distributed Compositional Prior
Oct 10, 2018

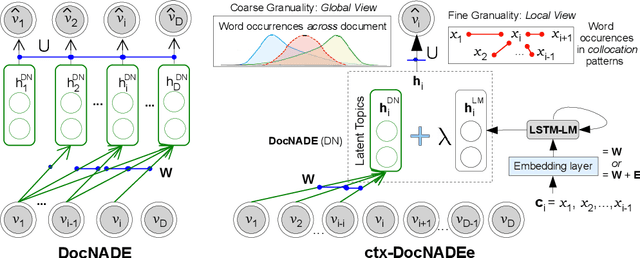
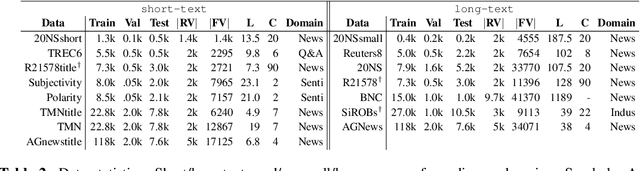
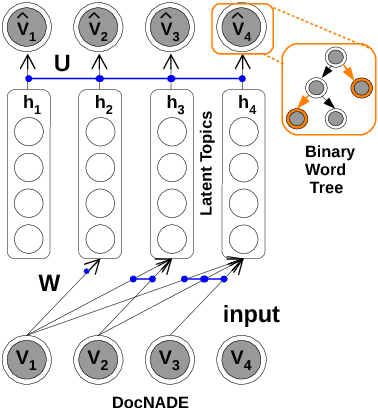
We address two challenges of probabilistic topic modelling in order to better estimate the probability of a word in a given context, i.e., P(word|context): (1) No Language Structure in Context: Probabilistic topic models ignore word order by summarizing a given context as a "bag-of-word" and consequently the semantics of words in the context is lost. The LSTM-LM learns a vector-space representation of each word by accounting for word order in local collocation patterns and models complex characteristics of language (e.g., syntax and semantics), while the TM simultaneously learns a latent representation from the entire document and discovers the underlying thematic structure. We unite two complementary paradigms of learning the meaning of word occurrences by combining a TM and a LM in a unified probabilistic framework, named as ctx-DocNADE. (2) Limited Context and/or Smaller training corpus of documents: In settings with a small number of word occurrences (i.e., lack of context) in short text or data sparsity in a corpus of few documents, the application of TMs is challenging. We address this challenge by incorporating external knowledge into neural autoregressive topic models via a language modelling approach: we use word embeddings as input of a LSTM-LM with the aim to improve the word-topic mapping on a smaller and/or short-text corpus. The proposed DocNADE extension is named as ctx-DocNADEe. We present novel neural autoregressive topic model variants coupled with neural LMs and embeddings priors that consistently outperform state-of-the-art generative TMs in terms of generalization (perplexity), interpretability (topic coherence) and applicability (retrieval and classification) over 6 long-text and 8 short-text datasets from diverse domains.
Document Informed Neural Autoregressive Topic Models with Distributional Prior
Sep 15, 2018

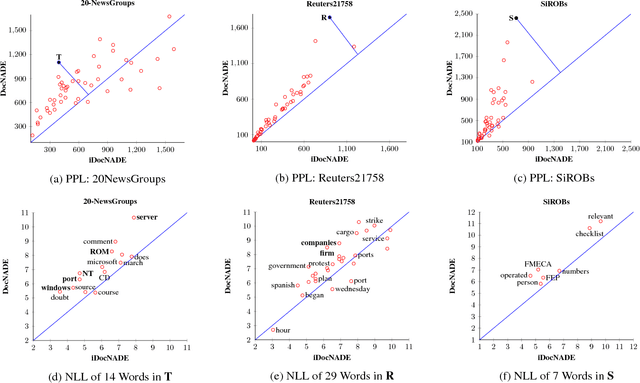
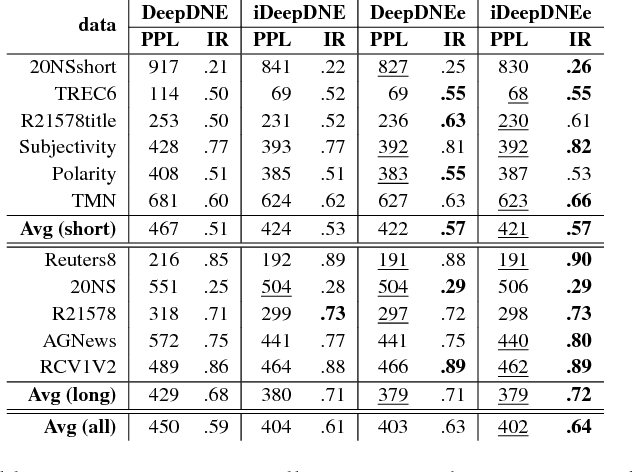
We address two challenges in topic models: (1) Context information around words helps in determining their actual meaning, e.g., "networks" used in the contexts artificial neural networks vs. biological neuron networks. Generative topic models infer topic-word distributions, taking no or only little context into account. Here, we extend a neural autoregressive topic model to exploit the full context information around words in a document in a language modeling fashion. The proposed model is named as iDocNADE. (2) Due to the small number of word occurrences (i.e., lack of context) in short text and data sparsity in a corpus of few documents, the application of topic models is challenging on such texts. Therefore, we propose a simple and efficient way of incorporating external knowledge into neural autoregressive topic models: we use embeddings as a distributional prior. The proposed variants are named as DocNADE2 and iDocNADE2. We present novel neural autoregressive topic model variants that consistently outperform state-of-the-art generative topic models in terms of generalization, interpretability (topic coherence) and applicability (retrieval and classification) over 6 long-text and 8 short-text datasets from diverse domains.
Document Informed Neural Autoregressive Topic Models
Aug 11, 2018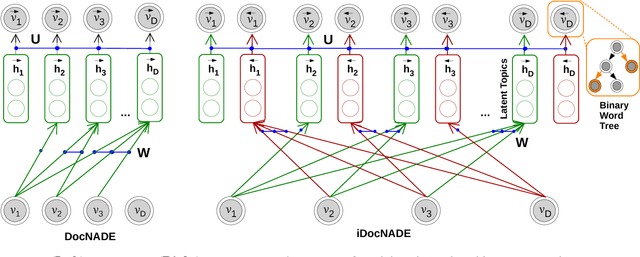
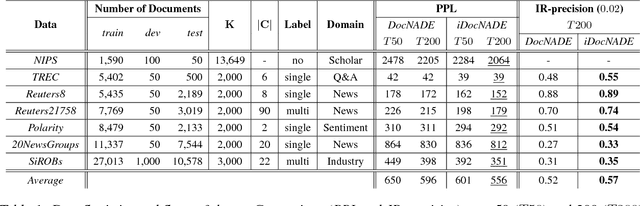
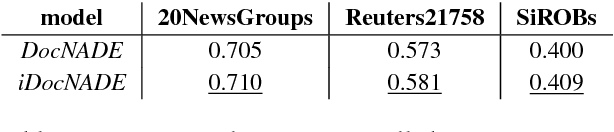
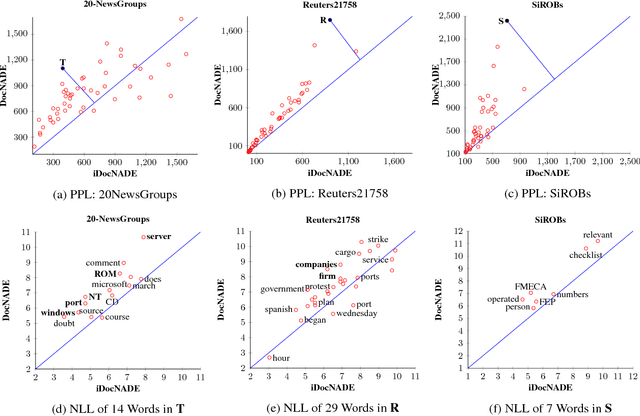
Context information around words helps in determining their actual meaning, for example "networks" used in contexts of artificial neural networks or biological neuron networks. Generative topic models infer topic-word distributions, taking no or only little context into account. Here, we extend a neural autoregressive topic model to exploit the full context information around words in a document in a language modeling fashion. This results in an improved performance in terms of generalization, interpretability and applicability. We apply our modeling approach to seven data sets from various domains and demonstrate that our approach consistently outperforms stateof-the-art generative topic models. With the learned representations, we show on an average a gain of 9.6% (0.57 Vs 0.52) in precision at retrieval fraction 0.02 and 7.2% (0.582 Vs 0.543) in F1 for text categorization.
LISA: Explaining Recurrent Neural Network Judgments via Layer-wIse Semantic Accumulation and Example to Pattern Transformation
Aug 05, 2018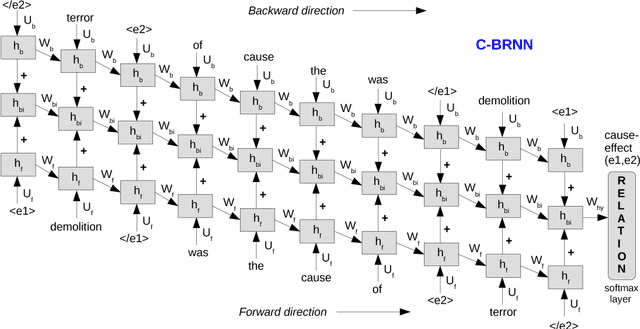

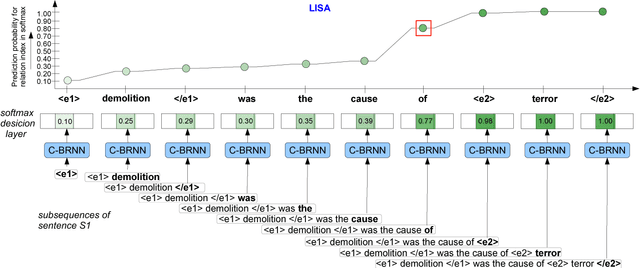

Recurrent neural networks (RNNs) are temporal networks and cumulative in nature that have shown promising results in various natural language processing tasks. Despite their success, it still remains a challenge to understand their hidden behavior. In this work, we analyze and interpret the cumulative nature of RNN via a proposed technique named as Layer-wIse-Semantic-Accumulation (LISA) for explaining decisions and detecting the most likely (i.e., saliency) patterns that the network relies on while decision making. We demonstrate (1) LISA: "How an RNN accumulates or builds semantics during its sequential processing for a given text example and expected response" (2) Example2pattern: "How the saliency patterns look like for each category in the data according to the network in decision making". We analyse the sensitiveness of RNNs about different inputs to check the increase or decrease in prediction scores and further extract the saliency patterns learned by the network. We employ two relation classification datasets: SemEval 10 Task 8 and TAC KBP Slot Filling to explain RNN predictions via the LISA and example2pattern.
Replicated Siamese LSTM in Ticketing System for Similarity Learning and Retrieval in Asymmetric Texts
Jul 08, 2018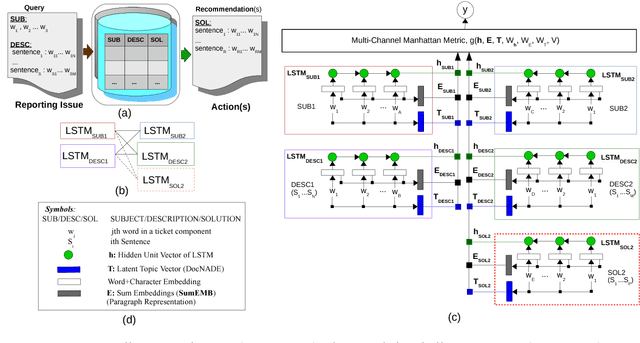
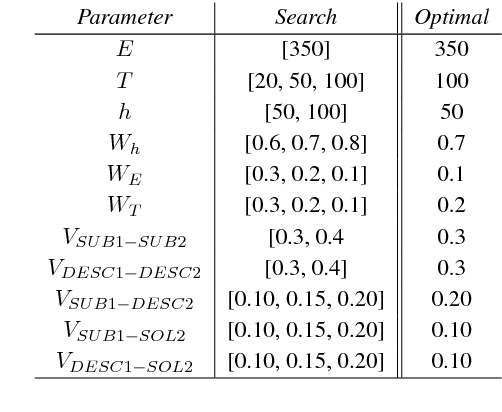
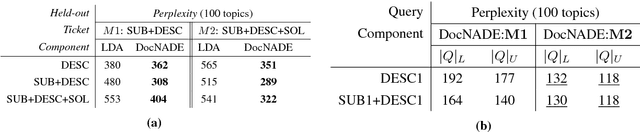
The goal of our industrial ticketing system is to retrieve a relevant solution for an input query, by matching with historical tickets stored in knowledge base. A query is comprised of subject and description, while a historical ticket consists of subject, description and solution. To retrieve a relevant solution, we use textual similarity paradigm to learn similarity in the query and historical tickets. The task is challenging due to significant term mismatch in the query and ticket pairs of asymmetric lengths, where subject is a short text but description and solution are multi-sentence texts. We present a novel Replicated Siamese LSTM model to learn similarity in asymmetric text pairs, that gives 22% and 7% gain (Accuracy@10) for retrieval task, respectively over unsupervised and supervised baselines. We also show that the topic and distributed semantic features for short and long texts improved both similarity learning and retrieval.
Joint Bootstrapping Machines for High Confidence Relation Extraction
May 01, 2018
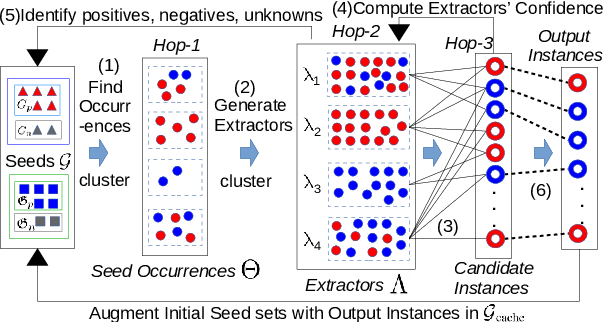
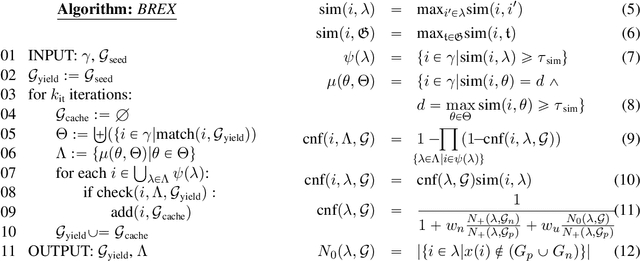

Semi-supervised bootstrapping techniques for relationship extraction from text iteratively expand a set of initial seed instances. Due to the lack of labeled data, a key challenge in bootstrapping is semantic drift: if a false positive instance is added during an iteration, then all following iterations are contaminated. We introduce BREX, a new bootstrapping method that protects against such contamination by highly effective confidence assessment. This is achieved by using entity and template seeds jointly (as opposed to just one as in previous work), by expanding entities and templates in parallel and in a mutually constraining fashion in each iteration and by introducing higherquality similarity measures for templates. Experimental results show that BREX achieves an F1 that is 0.13 (0.87 vs. 0.74) better than the state of the art for four relationships.