 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Online Multitask Learning of Behavioral Sentence Embeddings
Nov 01, 2018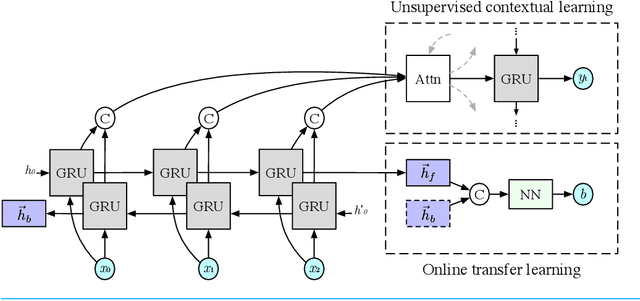

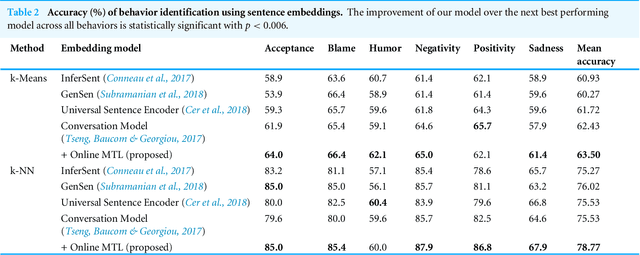
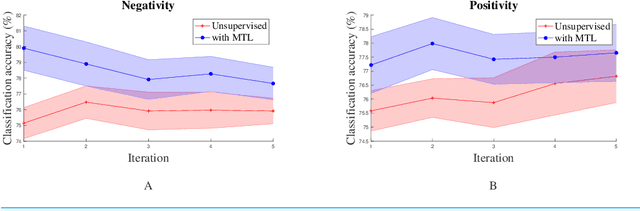
Unsupervised learning has been an attractive method for easily deriving meaningful data representations from vast amounts of unlabeled data. These representations, or embeddings, often yield superior results in many tasks, whether used directly or as features in subsequent training stages. However, the quality of the embeddings is highly dependent on the assumed knowledge in the unlabeled data and how the system extracts information without supervision. Domain portability is also very limited in unsupervised learning, often requiring re-training on other in-domain corpora to achieve robustness. In this work we present a multitask paradigm for unsupervised contextual learning of behavioral interactions which addresses unsupervised domain adaption. We introduce an online multitask objective into unsupervised learning and show that sentence embeddings generated through this process increases performance of affective tasks.
Modeling Interpersonal Influence of Verbal Behavior in Couples Therapy Dyadic Interactions
May 23, 2018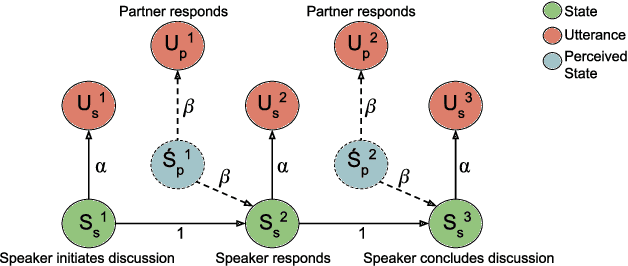

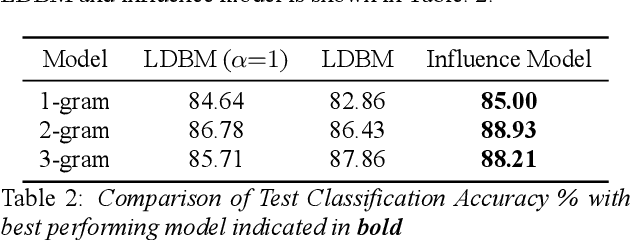
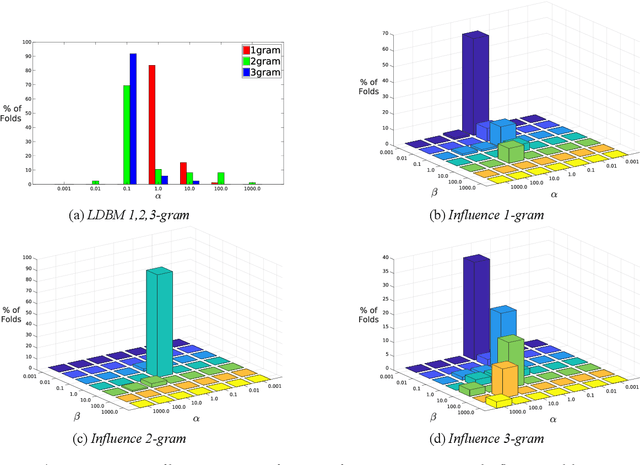
Dyadic interactions among humans are marked by speakers continuously influencing and reacting to each other in terms of responses and behaviors, among others. Understanding how interpersonal dynamics affect behavior is important for successful treatment in psychotherapy domains. Traditional schemes that automatically identify behavior for this purpose have often looked at only the target speaker. In this work, we propose a Markov model of how a target speaker's behavior is influenced by their own past behavior as well as their perception of their partner's behavior, based on lexical features. Apart from incorporating additional potentially useful information, our model can also control the degree to which the partner affects the target speaker. We evaluate our proposed model on the task of classifying Negative behavior in Couples Therapy and show that it is more accurate than the single-speaker model. Furthermore, we investigate the degree to which the optimal influence relates to how well a couple does on the long-term, via relating to relationship outcomes
Transfer Learning from Adult to Children for Speech Recognition: Evaluation, Analysis and Recommendations
May 08, 2018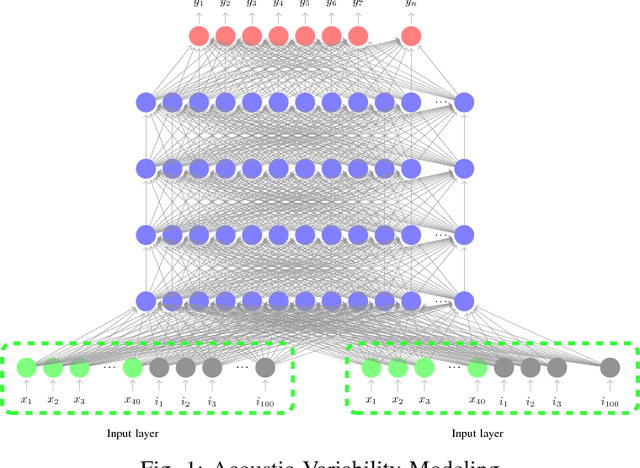
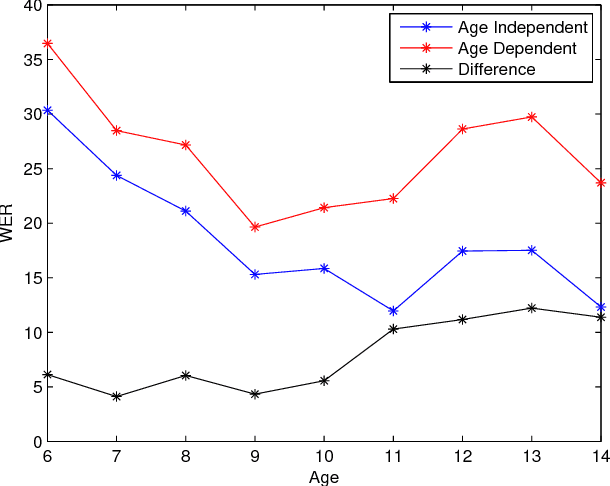
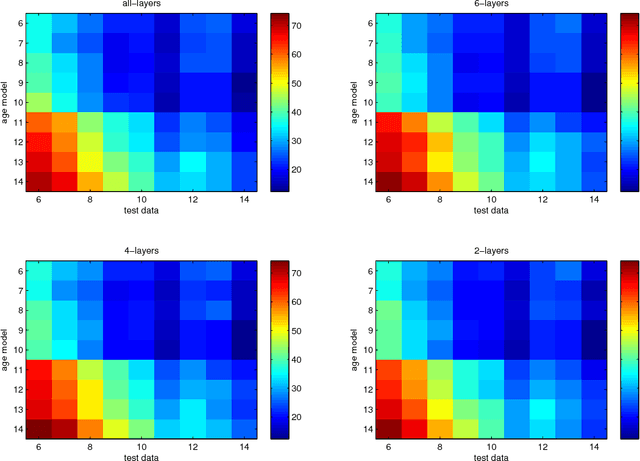
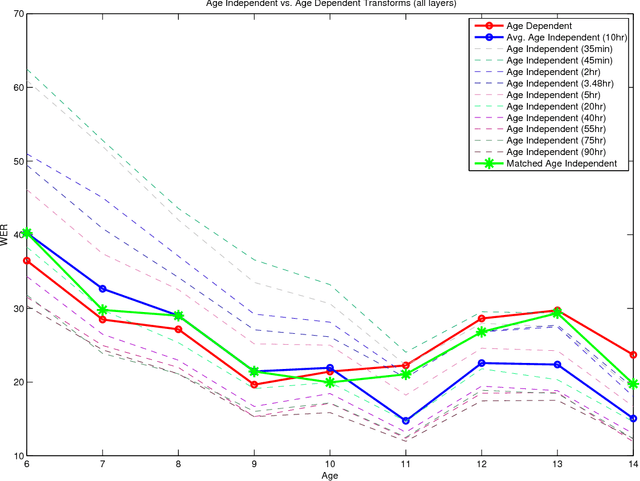
Children speech recognition is challenging mainly due to the inherent high variability in children's physical and articulatory characteristics and expressions. This variability manifests in both acoustic constructs and linguistic usage due to the rapidly changing developmental stage in children's life. Part of the challenge is due to the lack of large amounts of available children speech data for efficient modeling. This work attempts to address the key challenges using transfer learning from adult's models to children's models in a Deep Neural Network (DNN) framework for children's Automatic Speech Recognition (ASR) task evaluating on multiple children's speech corpora with a large vocabulary. The paper presents a systematic and an extensive analysis of the proposed transfer learning technique considering the key factors affecting children's speech recognition from prior literature. Evaluations are presented on (i) comparisons of earlier GMM-HMM and the newer DNN Models, (ii) effectiveness of standard adaptation techniques versus transfer learning, (iii) various adaptation configurations in tackling the variabilities present in children speech, in terms of (a) acoustic spectral variability, and (b) pronunciation variability and linguistic constraints. Our Analysis spans over (i) number of DNN model parameters (for adaptation), (ii) amount of adaptation data, (iii) ages of children, (iv) age dependent-independent adaptation. Finally, we provide Recommendations on (i) the favorable strategies over various aforementioned - analyzed parameters, and (ii) potential future research directions and relevant challenges/problems persisting in DNN based ASR for children's speech.
Towards an Unsupervised Entrainment Distance in Conversational Speech using Deep Neural Networks
Apr 23, 2018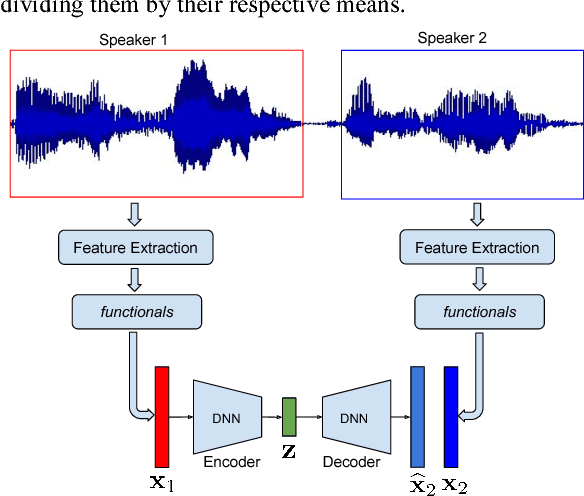
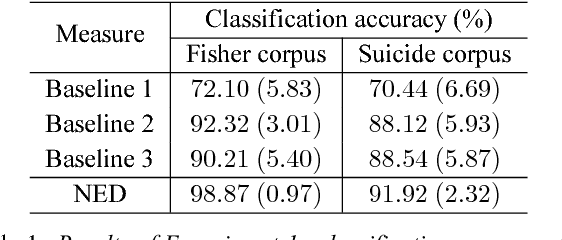
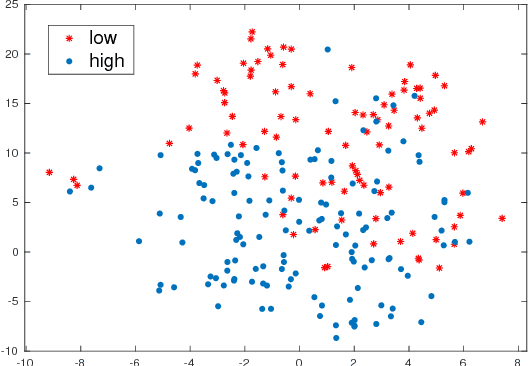
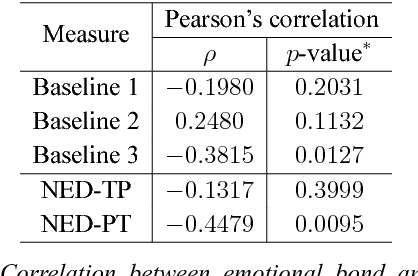
Entrainment is a known adaptation mechanism that causes interaction participants to adapt or synchronize their acoustic characteristics. Understanding how interlocutors tend to adapt to each other's speaking style through entrainment involves measuring a range of acoustic features and comparing those via multiple signal comparison methods. In this work, we present a turn-level distance measure obtained in an unsupervised manner using a Deep Neural Network (DNN) model, which we call Neural Entrainment Distance (NED). This metric establishes a framework that learns an embedding from the population-wide entrainment in an unlabeled training corpus. We use the framework for a set of acoustic features and validate the measure experimentally by showing its efficacy in distinguishing real conversations from fake ones created by randomly shuffling speaker turns. Moreover, we show real world evidence of the validity of the proposed measure. We find that high value of NED is associated with high ratings of emotional bond in suicide assessment interviews, which is consistent with prior studies.
Neural Predictive Coding using Convolutional Neural Networks towards Unsupervised Learning of Speaker Characteristics
Feb 22, 2018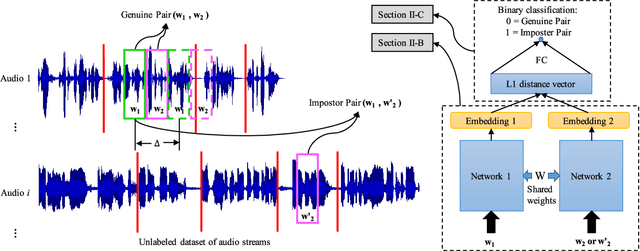
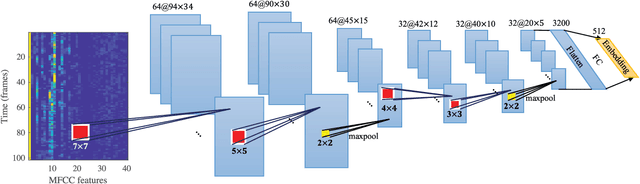
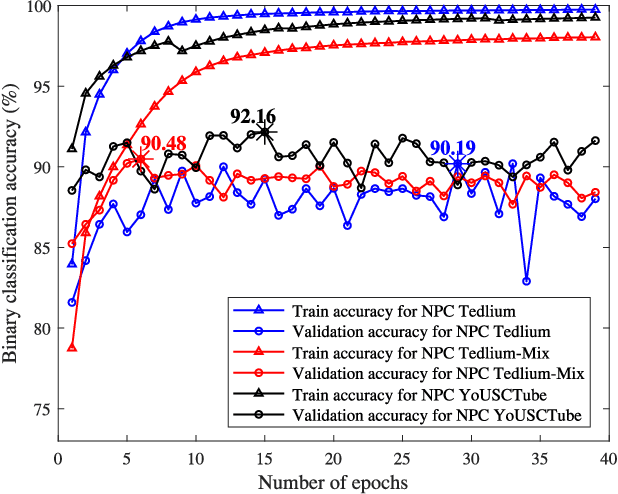
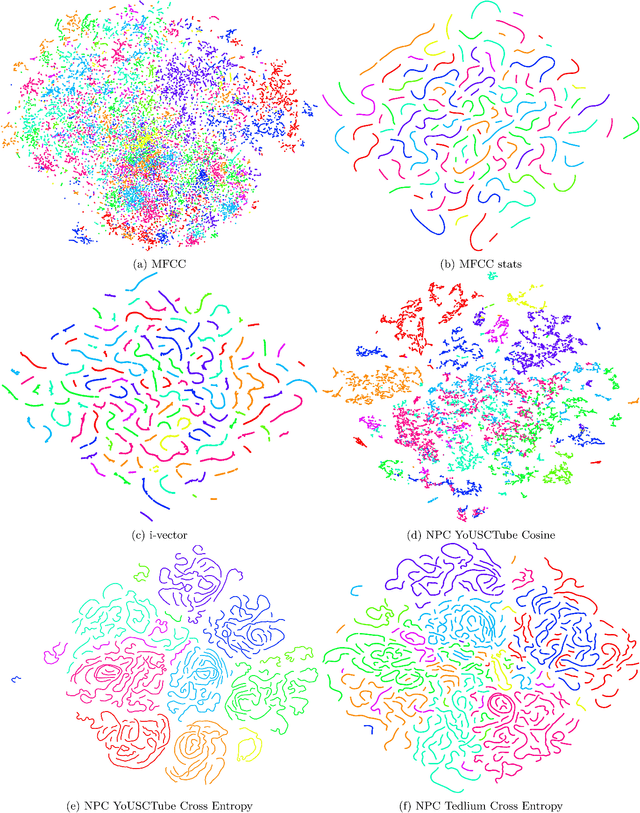
Learning speaker-specific features is vital in many applications like speaker recognition, diarization and speech recognition. This paper provides a novel approach, we term Neural Predictive Coding (NPC), to learn speaker-specific characteristics in a completely unsupervised manner from large amounts of unlabeled training data that even contain multi-speaker audio streams. The NPC framework exploits the proposed short-term active-speaker stationarity hypothesis which assumes two temporally-close short speech segments belong to the same speaker, and thus a common representation that can encode the commonalities of both the segments, should capture the vocal characteristics of that speaker. We train a convolutional deep siamese network to produce "speaker embeddings" by optimizing a loss function that increases between-speaker variability and decreases within-speaker variability. The trained NPC model can produce these embeddings by projecting any test audio stream into a high dimensional manifold where speech frames of the same speaker come closer than they do in the raw feature space. Results in the frame-level speaker classification experiment along with the visualization of the embeddings manifest the distinctive ability of the NPC model to learn short-term speaker-specific features as compared to raw MFCC features and i-vectors. The utterance-level speaker classification experiments show that concatenating simple statistics of the short-term NPC embeddings over the whole utterance with the utterance-level i-vectors can give useful complimentary information to the i-vectors and boost the classification accuracy. The results also show the efficacy of this technique to learn those characteristics from large amounts of unlabeled training set which has no prior information about the environment of the test set.
Learning from Past Mistakes: Improving Automatic Speech Recognition Output via Noisy-Clean Phrase Context Modeling
Feb 07, 2018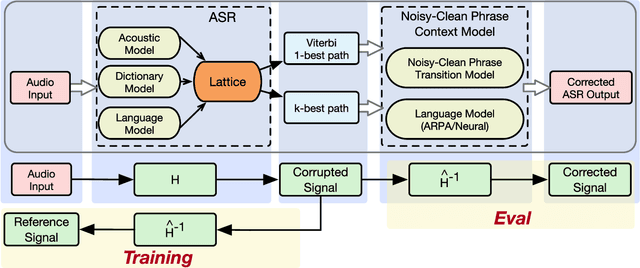

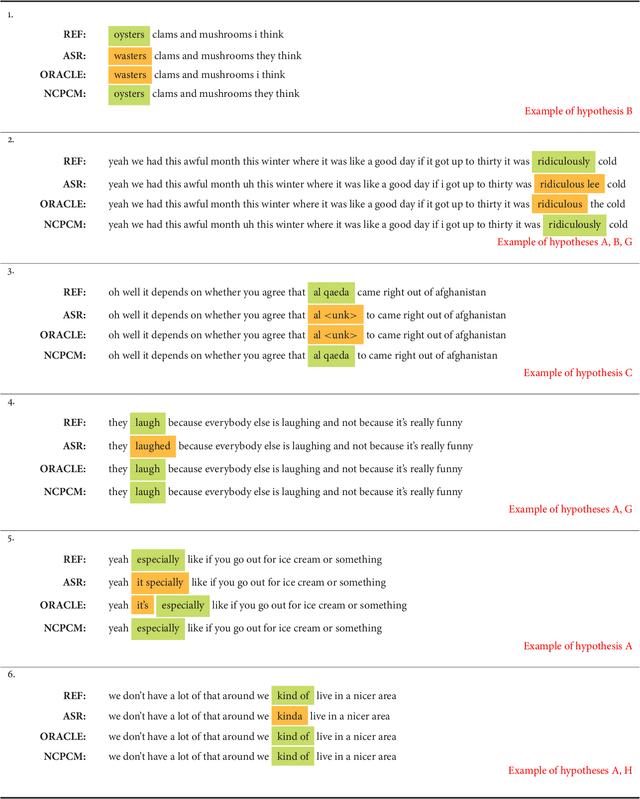
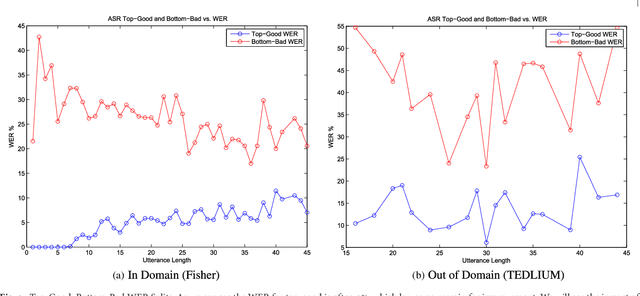
Automatic speech recognition (ASR) systems lack joint optimization during decoding over the acoustic, lexical and language models; for instance the ASR will often prune words due to acoustics using short-term context, prior to rescoring with long-term context. In this work we model the automated speech transcription process as a noisy transformation channel and propose an error correction system that can learn from the aggregate errors of all the independent modules constituting the ASR. The proposed system can exploit long-term context using a neural network language model and can better choose between existing ASR output possibilities as well as re-introduce previously pruned and unseen (out-of-vocabulary) phrases. The system provides significant corrections under poorly performing ASR conditions without degrading any accurate transcriptions. The proposed system can thus be independently optimized and post-process the output of even a highly optimized ASR. We show that the system consistently provides improvements over the baseline ASR. We also show that it performs better when used on out-of-domain and mismatched test data and under high-error ASR conditions. Finally, an extensive analysis of the type of errors corrected by our system is presented.
Unsupervised Latent Behavior Manifold Learning from Acoustic Features: audio2behavior
Jan 12, 2017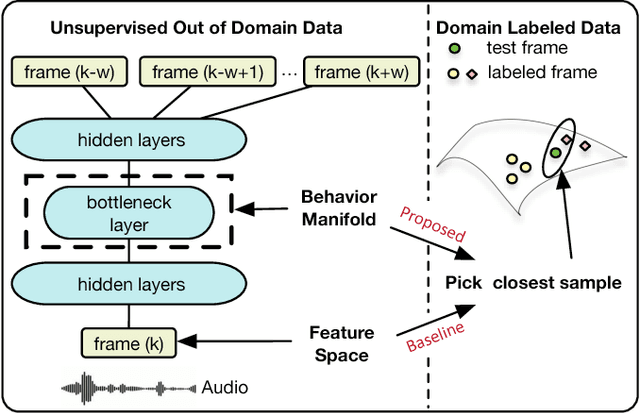

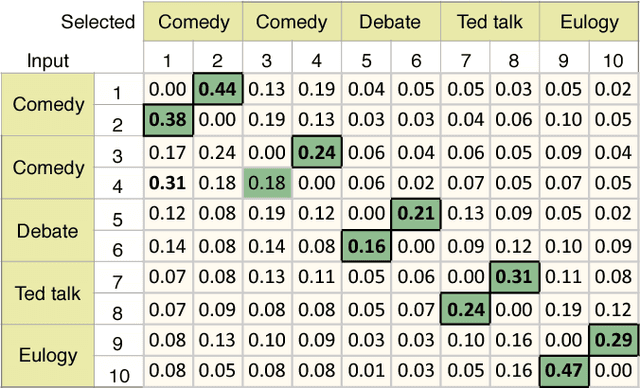
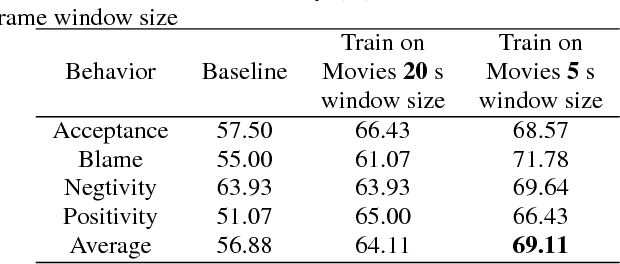
Behavioral annotation using signal processing and machine learning is highly dependent on training data and manual annotations of behavioral labels. Previous studies have shown that speech information encodes significant behavioral information and be used in a variety of automated behavior recognition tasks. However, extracting behavior information from speech is still a difficult task due to the sparseness of training data coupled with the complex, high-dimensionality of speech, and the complex and multiple information streams it encodes. In this work we exploit the slow varying properties of human behavior. We hypothesize that nearby segments of speech share the same behavioral context and hence share a similar underlying representation in a latent space. Specifically, we propose a Deep Neural Network (DNN) model to connect behavioral context and derive the behavioral manifold in an unsupervised manner. We evaluate the proposed manifold in the couples therapy domain and also provide examples from publicly available data (e.g. stand-up comedy). We further investigate training within the couples' therapy domain and from movie data. The results are extremely encouraging and promise improved behavioral quantification in an unsupervised manner and warrants further investigation in a range of applications.
Sparsely Connected and Disjointly Trained Deep Neural Networks for Low Resource Behavioral Annotation: Acoustic Classification in Couples' Therapy
Jun 14, 2016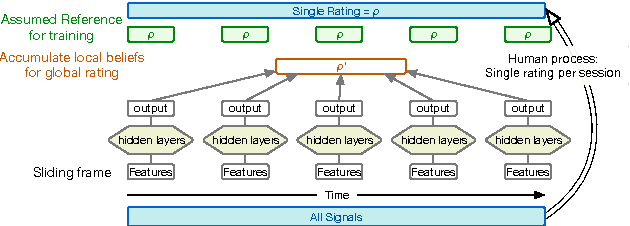
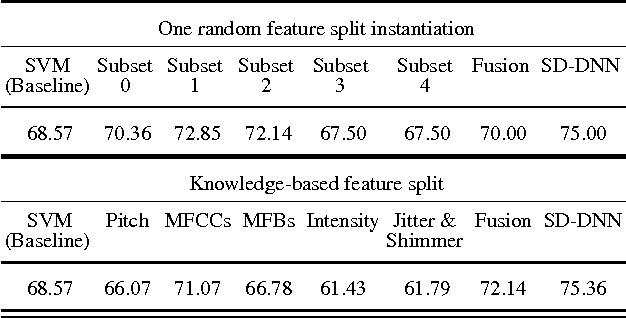
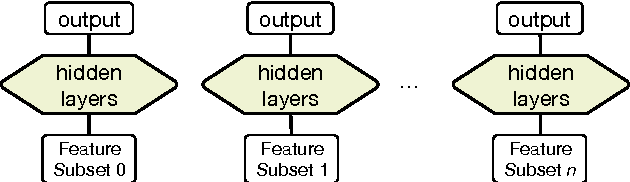

Observational studies are based on accurate assessment of human state. A behavior recognition system that models interlocutors' state in real-time can significantly aid the mental health domain. However, behavior recognition from speech remains a challenging task since it is difficult to find generalizable and representative features because of noisy and high-dimensional data, especially when data is limited and annotated coarsely and subjectively. Deep Neural Networks (DNN) have shown promise in a wide range of machine learning tasks, but for Behavioral Signal Processing (BSP) tasks their application has been constrained due to limited quantity of data. We propose a Sparsely-Connected and Disjointly-Trained DNN (SD-DNN) framework to deal with limited data. First, we break the acoustic feature set into subsets and train multiple distinct classifiers. Then, the hidden layers of these classifiers become parts of a deeper network that integrates all feature streams. The overall system allows for full connectivity while limiting the number of parameters trained at any time and allows convergence possible with even limited data. We present results on multiple behavior codes in the couples' therapy domain and demonstrate the benefits in behavior classification accuracy. We also show the viability of this system towards live behavior annotations.