 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning for surrogate modelling of 2D mantle convection
Aug 23, 2021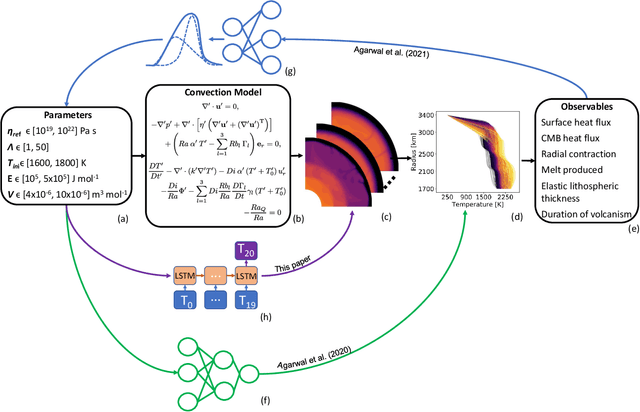
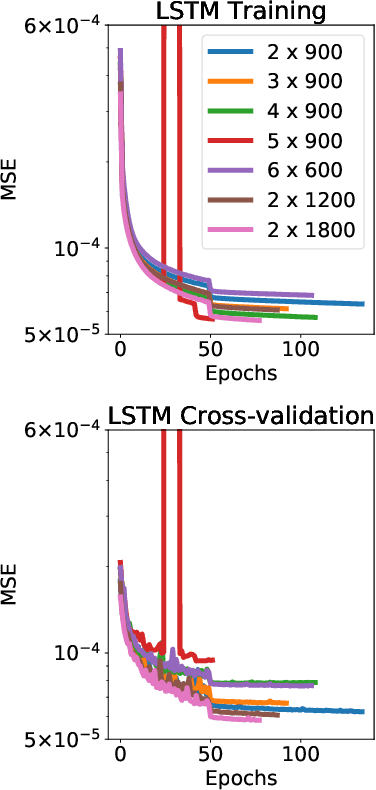
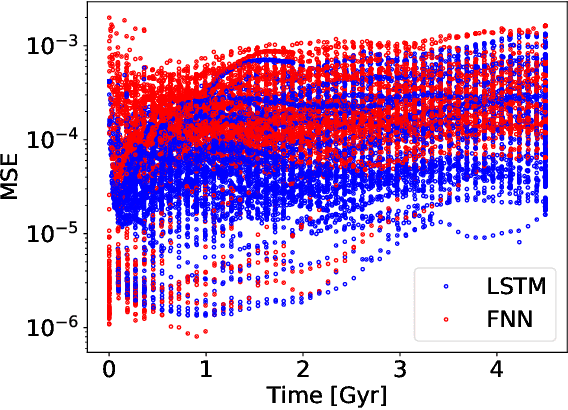
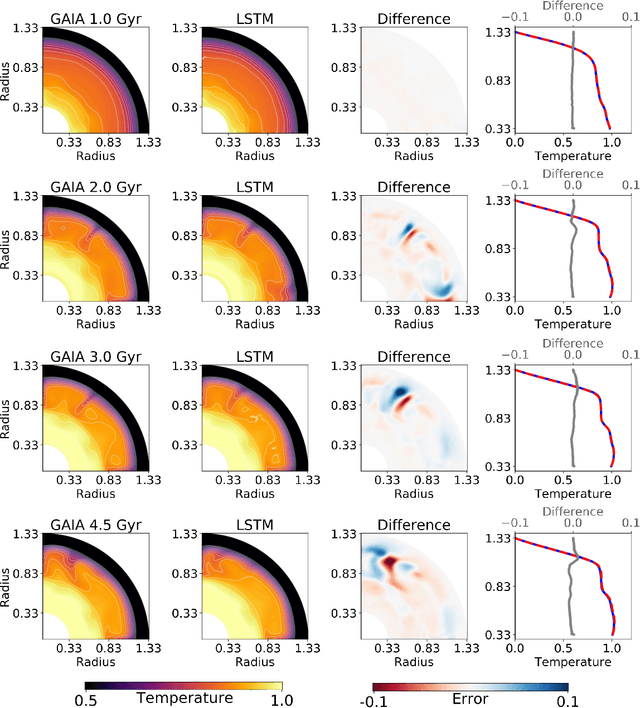
Traditionally, 1D models based on scaling laws have been used to parameterized convective heat transfer rocks in the interior of terrestrial planets like Earth, Mars, Mercury and Venus to tackle the computational bottleneck of high-fidelity forward runs in 2D or 3D. However, these are limited in the amount of physics they can model (e.g. depth dependent material properties) and predict only mean quantities such as the mean mantle temperature. We recently showed that feedforward neural networks (FNN) trained using a large number of 2D simulations can overcome this limitation and reliably predict the evolution of entire 1D laterally-averaged temperature profile in time for complex models [Agarwal et al. 2020]. We now extend that approach to predict the full 2D temperature field, which contains more information in the form of convection structures such as hot plumes and cold downwellings. Using a dataset of 10,525 two-dimensional simulations of the thermal evolution of the mantle of a Mars-like planet, we show that deep learning techniques can produce reliable parameterized surrogates (i.e. surrogates that predict state variables such as temperature based only on parameters) of the underlying partial differential equations. We first use convolutional autoencoders to compress the temperature fields by a factor of 142 and then use FNN and long-short term memory networks (LSTM) to predict the compressed fields. On average, the FNN predictions are 99.30% and the LSTM predictions are 99.22% accurate with respect to unseen simulations. Proper orthogonal decomposition (POD) of the LSTM and FNN predictions shows that despite a lower mean absolute relative accuracy, LSTMs capture the flow dynamics better than FNNs. When summed, the POD coefficients from FNN predictions and from LSTM predictions amount to 96.51% and 97.66% relative to the coefficients of the original simulations, respectively.
Towards Robust Explanations for Deep Neural Networks
Dec 18, 2020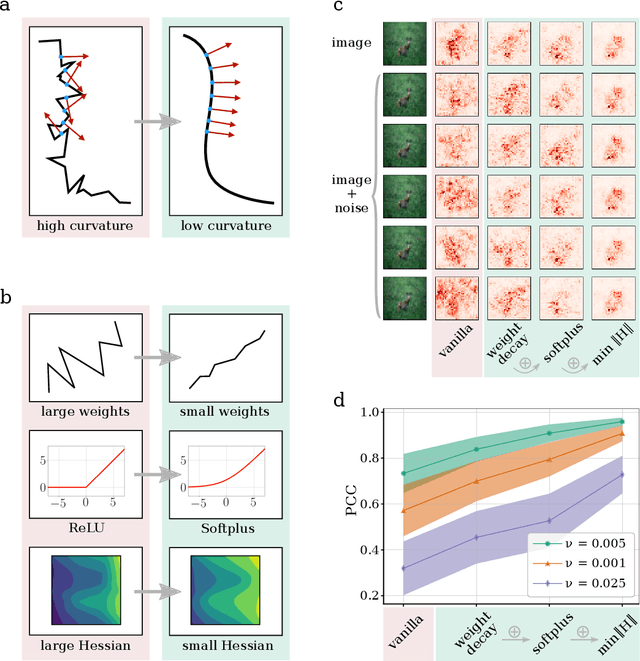

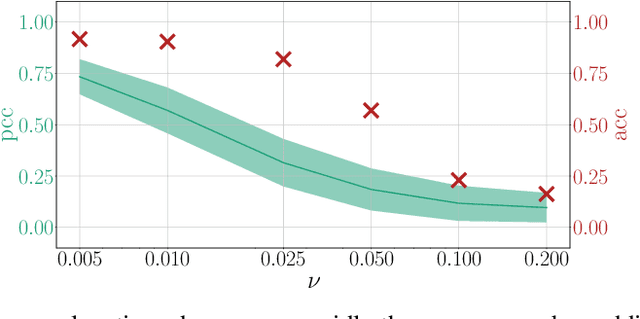
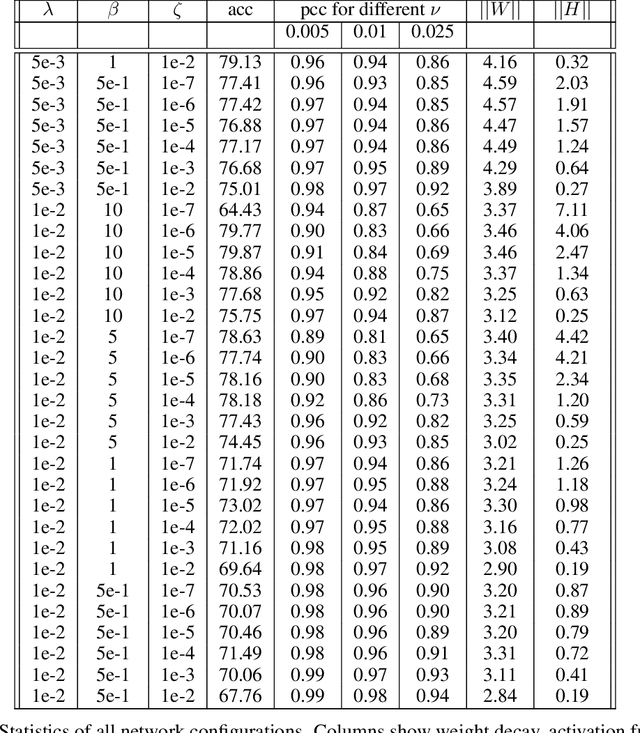
Explanation methods shed light on the decision process of black-box classifiers such as deep neural networks. But their usefulness can be compromised because they are susceptible to manipulations. With this work, we aim to enhance the resilience of explanations. We develop a unified theoretical framework for deriving bounds on the maximal manipulability of a model. Based on these theoretical insights, we present three different techniques to boost robustness against manipulation: training with weight decay, smoothing activation functions, and minimizing the Hessian of the network. Our experimental results confirm the effectiveness of these approaches.
Fairwashing Explanations with Off-Manifold Detergent
Jul 20, 2020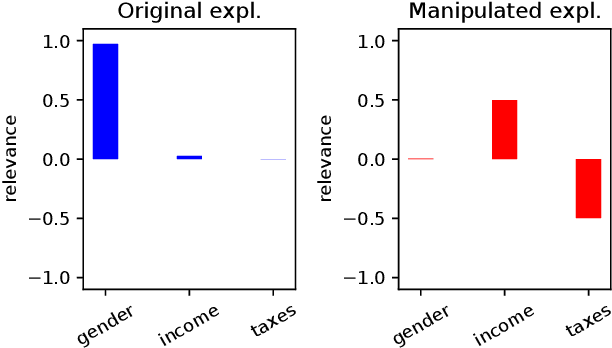
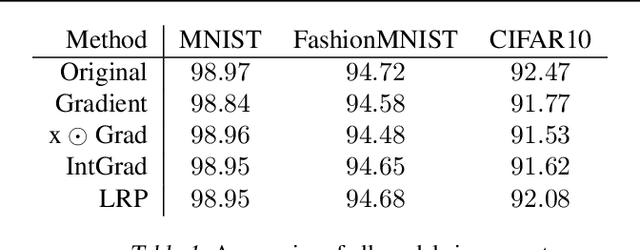

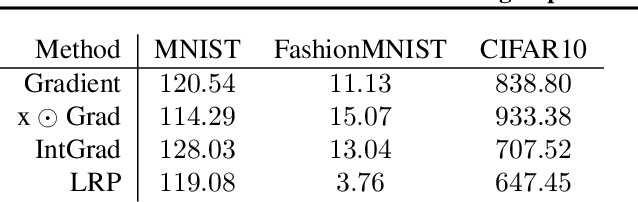
Explanation methods promise to make black-box classifiers more transparent. As a result, it is hoped that they can act as proof for a sensible, fair and trustworthy decision-making process of the algorithm and thereby increase its acceptance by the end-users. In this paper, we show both theoretically and experimentally that these hopes are presently unfounded. Specifically, we show that, for any classifier $g$, one can always construct another classifier $\tilde{g}$ which has the same behavior on the data (same train, validation, and test error) but has arbitrarily manipulated explanation maps. We derive this statement theoretically using differential geometry and demonstrate it experimentally for various explanation methods, architectures, and datasets. Motivated by our theoretical insights, we then propose a modification of existing explanation methods which makes them significantly more robust.
On Estimation of Thermodynamic Observables in Lattice Field Theories with Deep Generative Models
Jul 14, 2020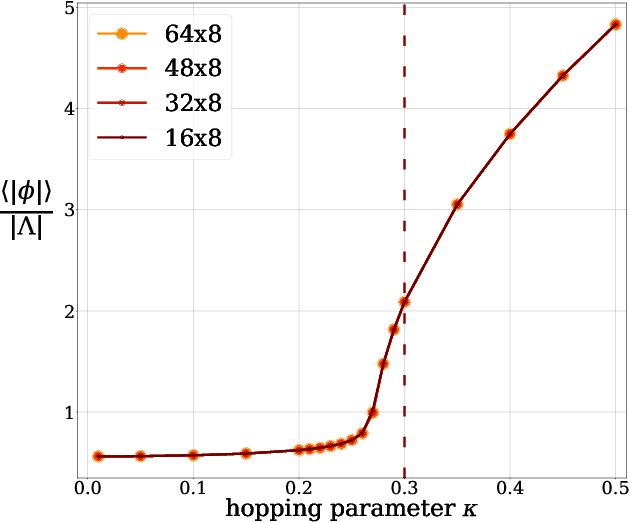
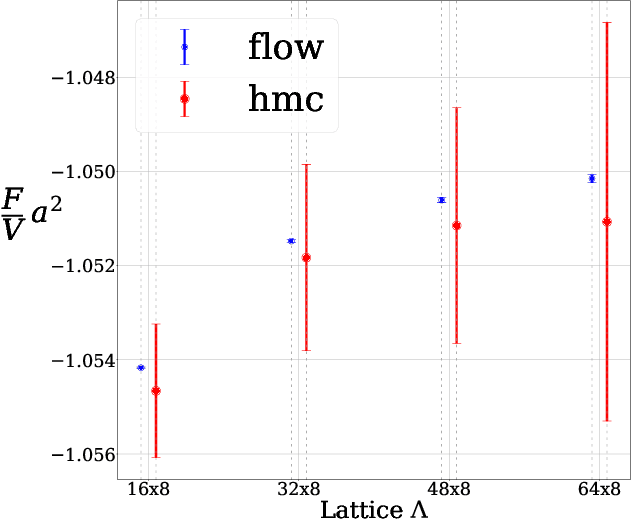
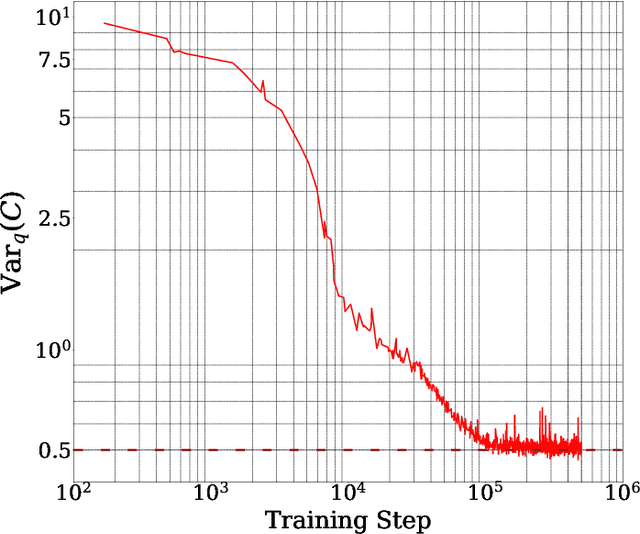
In this work, we demonstrate that applying deep generative machine learning models for lattice field theory is a promising route for solving problems where Markov Chain Monte Carlo (MCMC) methods are problematic. More specifically, we show that generative models can be used to estimate the absolute value of the free energy, which is in contrast to existing MCMC-based methods which are limited to only estimate free energy differences. We demonstrate the effectiveness of the proposed method for two-dimensional $\phi^4$ theory and compare it to MCMC-based methods in detailed numerical experiments.
Asymptotically Unbiased Generative Neural Sampling
Oct 29, 2019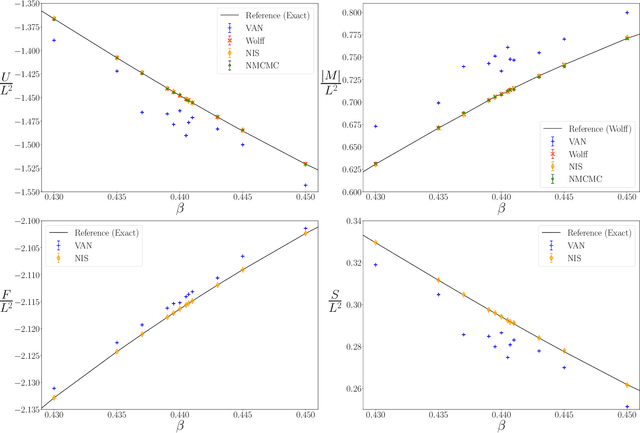
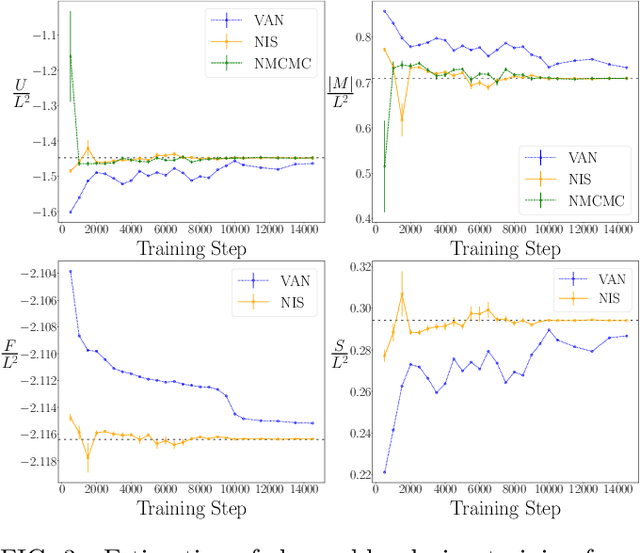
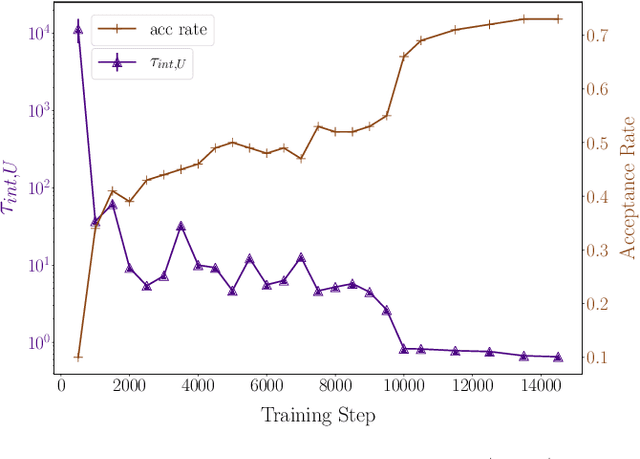
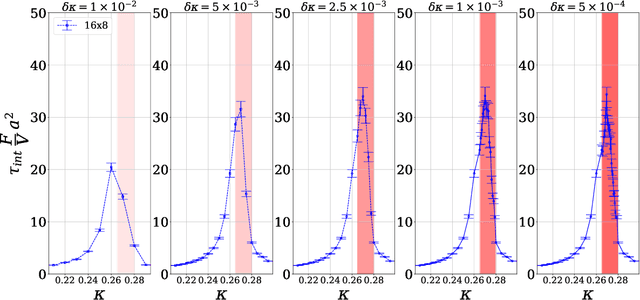
We propose a general framework for the estimation of observables with generative neural samplers focusing on modern deep generative neural networks that provide an exact sampling probability. In this framework, we present asymptotically unbiased estimators for generic observables, including those that explicitly depend on the partition function such as free energy or entropy, and derive corresponding variance estimators. We demonstrate their practical applicability by numerical experiments for the 2d Ising model which highlight the superiority over existing methods. Our approach greatly enhances the applicability of generative neural samplers to real-world physical systems.
Explanations can be manipulated and geometry is to blame
Jun 19, 2019

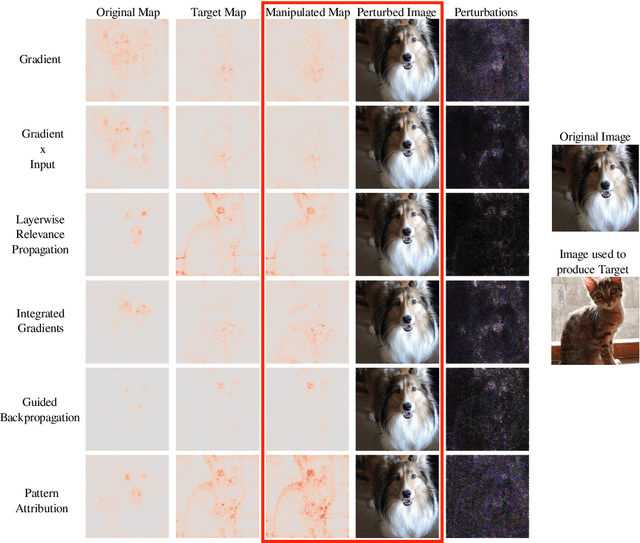
Explanation methods aim to make neural networks more trustworthy and interpretable. In this paper, we demonstrate a property of explanation methods which is disconcerting for both of these purposes. Namely, we show that explanations can be manipulated arbitrarily by applying visually hardly perceptible perturbations to the input that keep the network's output approximately constant. We establish theoretically that this phenomenon can be related to certain geometrical properties of neural networks. This allows us to derive an upper bound on the susceptibility of explanations to manipulations. Based on this result, we propose effective mechanisms to enhance the robustness of explanations.
Comment on "Solving Statistical Mechanics Using VANs": Introducing saVANt - VANs Enhanced by Importance and MCMC Sampling
Mar 26, 2019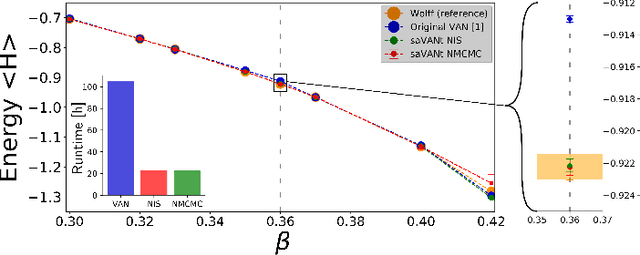
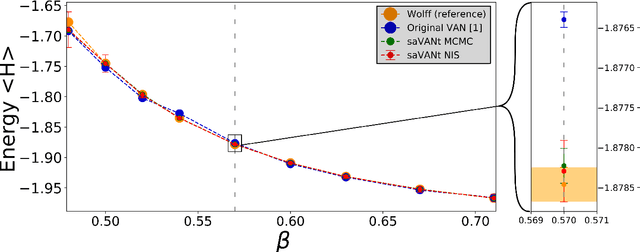
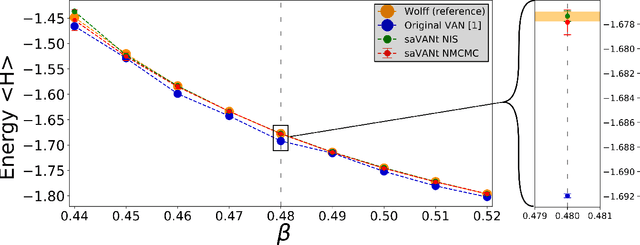
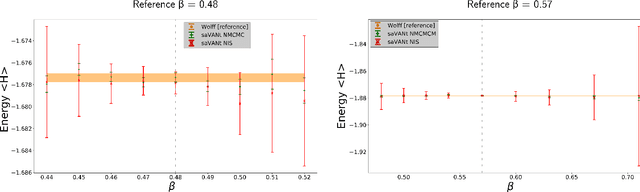
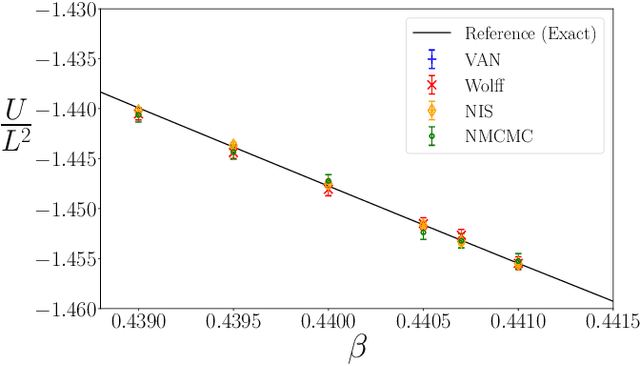
In this comment on "Solving Statistical Mechanics Using Variational Autoregressive Networks" by Wu et al., we propose a subtle yet powerful modification of their approach. We show that the inherent sampling error of their method can be corrected by using neural network-based MCMC or importance sampling which leads to asymptotically unbiased estimators for physical quantities. This modification is possible due to a singular property of VANs, namely that they provide the exact sample probability. With these modifications, we believe that their method could have a substantially greater impact on various important fields of physics, including strongly-interacting field theories and statistical physics.
Analysis of Atomistic Representations Using Weighted Skip-Connections
Oct 23, 2018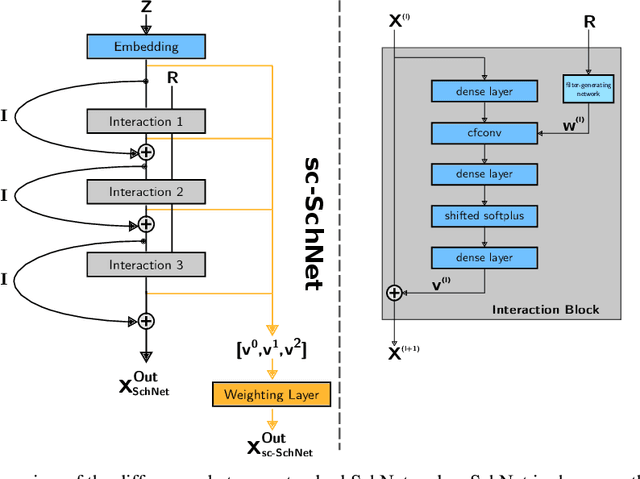
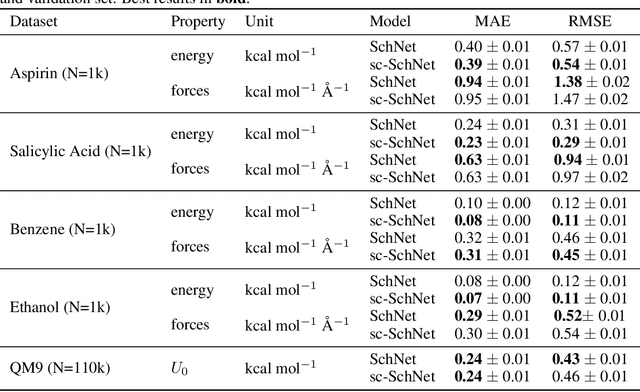
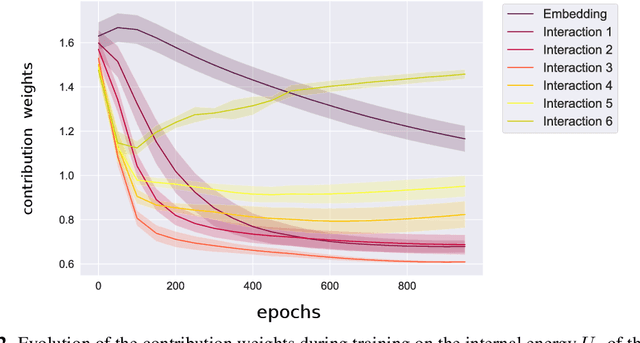
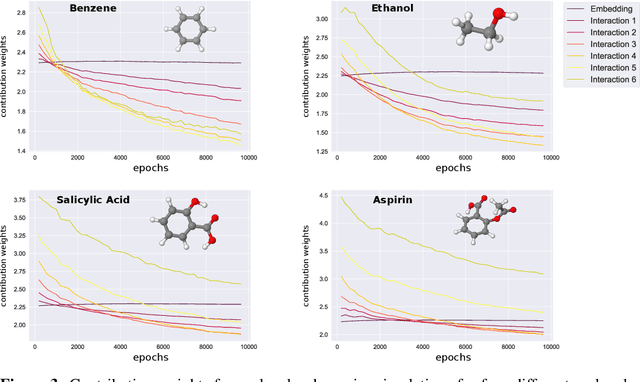
In this work, we extend the SchNet architecture by using weighted skip connections to assemble the final representation. This enables us to study the relative importance of each interaction block for property prediction. We demonstrate on both the QM9 and MD17 dataset that their relative weighting depends strongly on the chemical composition and configurational degrees of freedom of the molecules which opens the path towards a more detailed understanding of machine learning models for molecules.