 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMETER: a mobile vision transformer architecture for monocular depth estimation
Mar 13, 2024



Depth estimation is a fundamental knowledge for autonomous systems that need to assess their own state and perceive the surrounding environment. Deep learning algorithms for depth estimation have gained significant interest in recent years, owing to the potential benefits of this methodology in overcoming the limitations of active depth sensing systems. Moreover, due to the low cost and size of monocular cameras, researchers have focused their attention on monocular depth estimation (MDE), which consists in estimating a dense depth map from a single RGB video frame. State of the art MDE models typically rely on vision transformers (ViT) architectures that are highly deep and complex, making them unsuitable for fast inference on devices with hardware constraints. Purposely, in this paper, we address the problem of exploiting ViT in MDE on embedded devices. Those systems are usually characterized by limited memory capabilities and low-power CPU/GPU. We propose METER, a novel lightweight vision transformer architecture capable of achieving state of the art estimations and low latency inference performances on the considered embedded hardwares: NVIDIA Jetson TX1 and NVIDIA Jetson Nano. We provide a solution consisting of three alternative configurations of METER, a novel loss function to balance pixel estimation and reconstruction of image details, and a new data augmentation strategy to improve the overall final predictions. The proposed method outperforms previous lightweight works over the two benchmark datasets: the indoor NYU Depth v2 and the outdoor KITTI.
D4D: An RGBD diffusion model to boost monocular depth estimation
Mar 12, 2024Ground-truth RGBD data are fundamental for a wide range of computer vision applications; however, those labeled samples are difficult to collect and time-consuming to produce. A common solution to overcome this lack of data is to employ graphic engines to produce synthetic proxies; however, those data do not often reflect real-world images, resulting in poor performance of the trained models at the inference step. In this paper we propose a novel training pipeline that incorporates Diffusion4D (D4D), a customized 4-channels diffusion model able to generate realistic RGBD samples. We show the effectiveness of the developed solution in improving the performances of deep learning models on the monocular depth estimation task, where the correspondence between RGB and depth map is crucial to achieving accurate measurements. Our supervised training pipeline, enriched by the generated samples, outperforms synthetic and original data performances achieving an RMSE reduction of (8.2%, 11.9%) and (8.1%, 6.1%) respectively on the indoor NYU Depth v2 and the outdoor KITTI dataset.
(DE)^2 CO: Deep Depth Colorization
Feb 21, 2018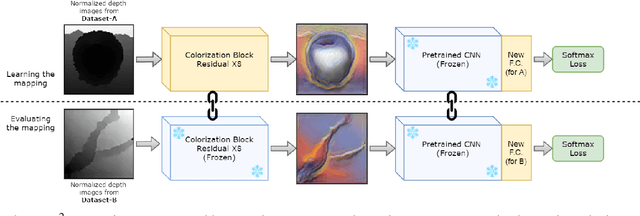
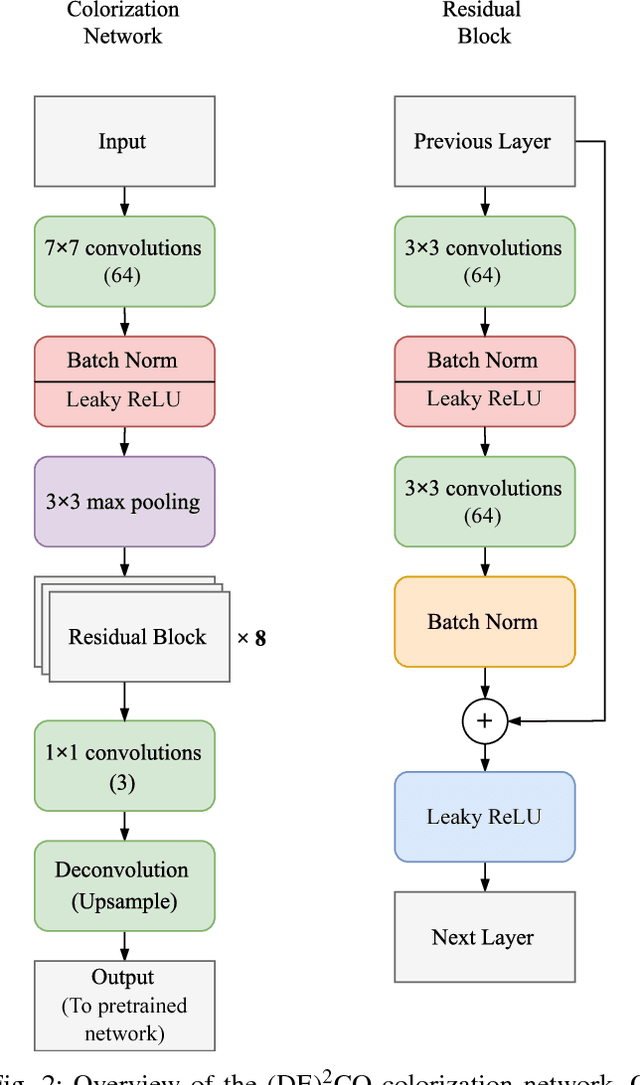
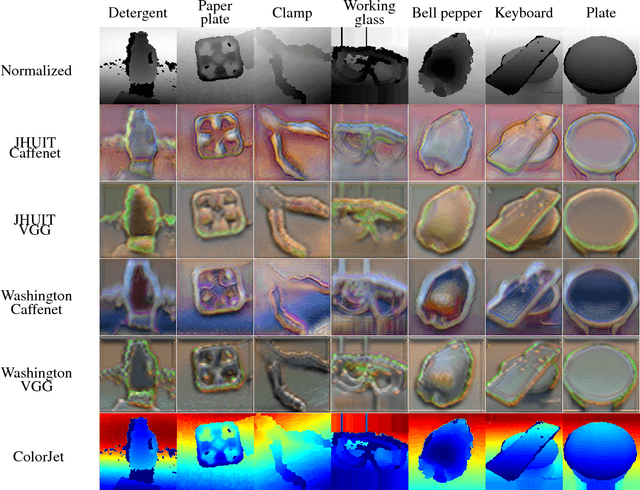
The ability to classify objects is fundamental for robots. Besides knowledge about their visual appearance, captured by the RGB channel, robots heavily need also depth information to make sense of the world. While the use of deep networks on RGB robot images has benefited from the plethora of results obtained on databases like ImageNet, using convnets on depth images requires mapping them into three dimensional channels. This transfer learning procedure makes them processable by pre-trained deep architectures. Current mappings are based on heuristic assumptions over preprocessing steps and on what depth properties should be most preserved, resulting often in cumbersome data visualizations, and in sub-optimal performance in terms of generality and recognition results. Here we take an alternative route and we attempt instead to learn an optimal colorization mapping for any given pre-trained architecture, using as training data a reference RGB-D database. We propose a deep network architecture, exploiting the residual paradigm, that learns how to map depth data to three channel images. A qualitative analysis of the images obtained with this approach clearly indicates that learning the optimal mapping preserves the richness of depth information better than current hand-crafted approaches. Experiments on the Washington, JHUIT-50 and BigBIRD public benchmark databases, using CaffeNet, VGG16, GoogleNet, and ResNet50 clearly showcase the power of our approach, with gains in performance of up to 16% compared to state of the art competitors on the depth channel only, leading to top performances when dealing with RGB-D data